Erfahren Sie, wie Sie Evaluierungen und Testfälle entwerfen, um die LLM-Leistung zu messen.
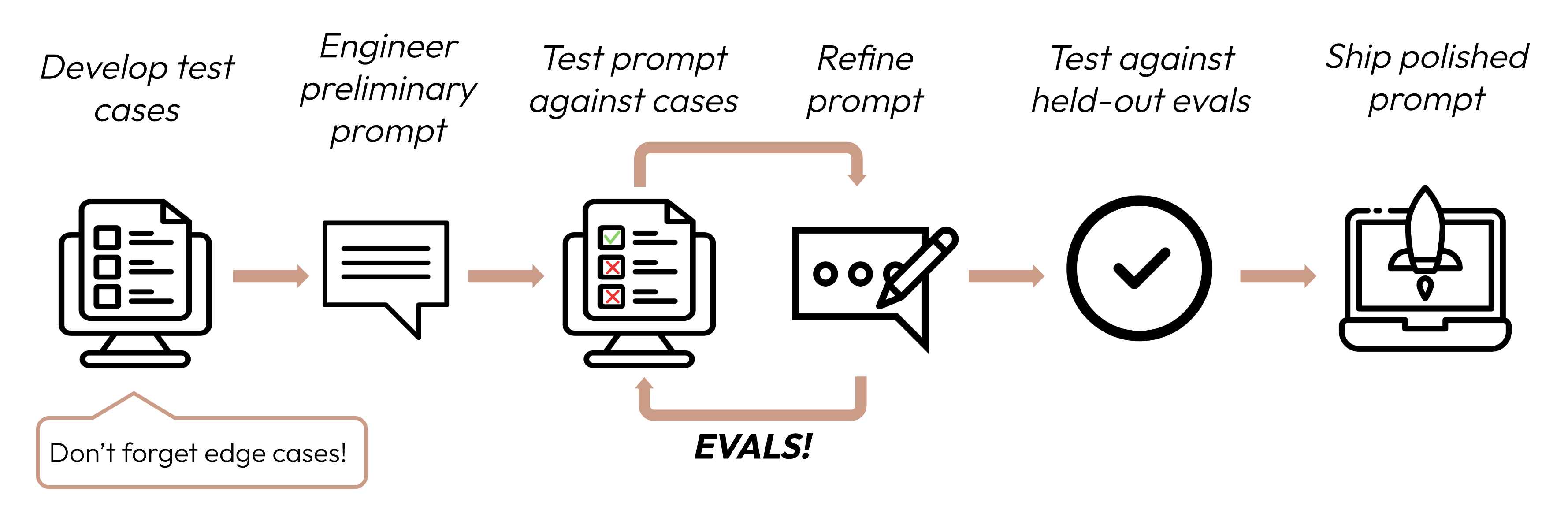
Nach der Definition Ihrer Erfolgskriterien besteht der nächste Schritt darin, Evaluierungen zu entwerfen, um die LLM-Leistung gegen diese Kriterien zu messen. Dies ist ein wichtiger Teil des Prompt-Engineering-Zyklus.
Dieser Leitfaden konzentriert sich auf die Entwicklung Ihrer Testfälle.
Evals und Testfälle erstellen
Eval-Designprinzipien
Aufgabenspezifisch sein: Entwerfen Sie Evals, die Ihre reale Aufgabenverteilung widerspiegeln. Vergessen Sie nicht, Grenzfälle einzubeziehen!
Automatisieren Sie, wenn möglich: Strukturieren Sie Fragen so, dass automatisierte Bewertung möglich ist (z. B. Multiple-Choice, String-Abgleich, Code-bewertet, LLM-bewertet).
Priorisieren Sie Volumen über Qualität: Mehr Fragen mit leicht niedrigerem Signal automatisierter Bewertung ist besser als weniger Fragen mit hochqualitativen manuell bewerteten Evals.
Beispiel-Evals
Das Schreiben von Hunderten von Testfällen kann schwierig sein! Lassen Sie Claude Ihnen helfen, mehr aus einem Basissatz von Beispiel-Testfällen zu generieren.
Wenn Sie nicht wissen, welche Eval-Methoden zur Bewertung Ihrer Erfolgskriterien nützlich sein könnten, können Sie auch mit Claude brainstormen!
Evals bewerten
Bei der Entscheidung, welche Methode zum Bewerten von Evals verwendet werden soll, wählen Sie die schnellste, zuverlässigste und skalierbarste Methode:
Code-basierte Bewertung: Am schnellsten und zuverlässigsten, äußerst skalierbar, aber auch mangelnde Nuance für komplexere Urteile, die weniger regelbasierte Starrheit erfordern.
Exact Match: output == golden_answer
String Match: key_phrase in output
Menschliche Bewertung: Am flexibelsten und höchster Qualität, aber langsam und teuer. Vermeiden Sie wenn möglich.
LLM-basierte Bewertung: Schnell und flexibel, skalierbar und geeignet für komplexe Urteile. Testen Sie zuerst auf Zuverlässigkeit, dann skalieren Sie.
Tipps für LLM-basierte Bewertung
Haben Sie detaillierte, klare Rubriken: „Die Antwort sollte immer ‚Acme Inc.' im ersten Satz erwähnen. Wenn nicht, wird die Antwort automatisch als ‚falsch' bewertet."
Ein bestimmter Anwendungsfall oder sogar ein spezifisches Erfolgskriterium für diesen Anwendungsfall könnte mehrere Rubriken für eine ganzheitliche Bewertung erfordern.
Empirisch oder spezifisch: Weisen Sie das LLM beispielsweise an, nur „korrekt" oder „falsch" auszugeben, oder urteilen Sie auf einer Skala von 1-5. Rein qualitative Bewertungen sind schwer schnell und im großen Maßstab zu bewerten.
Fördern Sie Überlegungen: Bitten Sie das LLM, zuerst zu überlegen, bevor es eine Bewertungspunktzahl entscheidet, und verwerfen Sie dann die Überlegungen. Dies verbessert die Bewertungsleistung, besonders für Aufgaben, die komplexe Urteile erfordern.