Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Gute Skills sind prägnant, gut strukturiert und mit realer Nutzung getestet. Dieser Leitfaden bietet praktische Entscheidungshilfen für das Erstellen, damit du Skills schreiben kannst, die Claude effektiv entdecken und nutzen kann.
Für konzeptionelle Hintergründe zur Funktionsweise von Skills siehe die Skills-Übersicht.
Das context window (Kontextfenster) ist ein Gemeingut. Dein Skill teilt sich das Kontextfenster mit allem anderen, was Claude wissen muss, einschließlich:
Nicht jedes Token in deinem Skill verursacht sofortige Kosten. Beim Start werden nur die Metadaten (Name und Beschreibung) aller Skills vorab geladen. Claude liest SKILL.md nur, wenn der Skill relevant wird, und liest zusätzliche Dateien nur bei Bedarf. Dennoch ist Prägnanz in SKILL.md wichtig: Sobald Claude sie lädt, konkurriert jedes Token mit dem Gesprächsverlauf und anderem Kontext.
Grundannahme: Claude ist bereits sehr intelligent
Füge nur Kontext hinzu, den Claude noch nicht hat. Hinterfrage jede Information:
Gutes Beispiel: Prägnant (ungefähr 50 Token):
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```Schlechtes Beispiel: Zu ausführlich (ungefähr 150 Token):
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but
pdfplumber is recommended because it's easy to use and handles most cases well.
First, you'll need to install it using pip. Then you can use the code below...Die prägnante Version geht davon aus, dass Claude weiß, was PDFs sind und wie Bibliotheken funktionieren.
Passe den Grad der Spezifität an die Fragilität und Variabilität der Aufgabe an.
Hohe Freiheit (textbasierte Anweisungen):
Verwende dies, wenn:
Beispiel:
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventionsMittlere Freiheit (Pseudocode oder Skripte mit Parametern):
Verwende dies, wenn:
Beispiel:
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```Geringe Freiheit (spezifische Skripte, wenige oder keine Parameter):
Verwende dies, wenn:
Beispiel:
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.Analogie: Stell dir Claude als Roboter vor, der einen Pfad erkundet:
Skills wirken als Ergänzungen zu Modellen, daher hängt die Effektivität vom zugrunde liegenden Modell ab. Teste deinen Skill mit allen Modellen, mit denen du ihn verwenden möchtest.
Testüberlegungen nach Modell:
Was für Opus perfekt funktioniert, benötigt für Haiku möglicherweise mehr Details. Wenn du deinen Skill mit mehreren Modellen verwenden möchtest, strebe Anweisungen an, die mit allen gut funktionieren.
YAML-Frontmatter: Das SKILL.md-Frontmatter erfordert zwei Felder:
name:
description:
Für vollständige Details zur Skill-Struktur siehe die Skills-Übersicht.
Verwende konsistente Namensmuster, um Skills leichter referenzieren und besprechen zu können. Erwäge die Verwendung der Gerundium-Form (Verb + -ing) für Skill-Namen, da dies die Aktivität oder Fähigkeit, die der Skill bietet, klar beschreibt.
Denke daran, dass das Feld name nur Kleinbuchstaben, Zahlen und Bindestriche verwenden darf.
Gute Namensbeispiele (Gerundium-Form):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentationAkzeptable Alternativen:
pdf-processing, spreadsheet-analysisprocess-pdfs, analyze-spreadsheetsVermeide:
helper, utils, toolsdocuments, data, filesanthropic-helper, claude-toolsKonsistente Benennung erleichtert es:
Das Feld description ermöglicht die Skill-Erkennung und sollte sowohl beschreiben, was der Skill tut, als auch wann er verwendet werden soll.
Schreibe immer in der dritten Person. Die Beschreibung wird in den System-Prompt eingefügt, und eine inkonsistente Erzählperspektive kann Erkennungsprobleme verursachen.
Sei spezifisch und füge Schlüsselbegriffe ein. Beschreibe sowohl, was der Skill tut, als auch spezifische Auslöser/Kontexte für seine Verwendung.
Jeder Skill hat genau ein Beschreibungsfeld. Die Beschreibung ist entscheidend für die Skill-Auswahl: Claude verwendet sie, um den richtigen Skill aus potenziell über 100 verfügbaren Skills auszuwählen. Deine Beschreibung muss genügend Details liefern, damit Claude weiß, wann dieser Skill ausgewählt werden soll, während der Rest von SKILL.md die Implementierungsdetails bereitstellt.
Effektive Beispiele:
PDF-Verarbeitungs-Skill:
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.Excel-Analyse-Skill:
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.Git-Commit-Helper-Skill:
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.Vermeide vage Beschreibungen wie diese:
description: Helps with documentsdescription: Processes datadescription: Does stuff with filesSKILL.md dient als Übersicht, die Claude bei Bedarf auf detaillierte Materialien verweist, ähnlich wie ein Inhaltsverzeichnis in einem Onboarding-Leitfaden. Für eine Erklärung, wie „progressive disclosure" (progressive Offenlegung) funktioniert, siehe Wie Skills funktionieren in der Übersicht.
Praktische Hinweise:
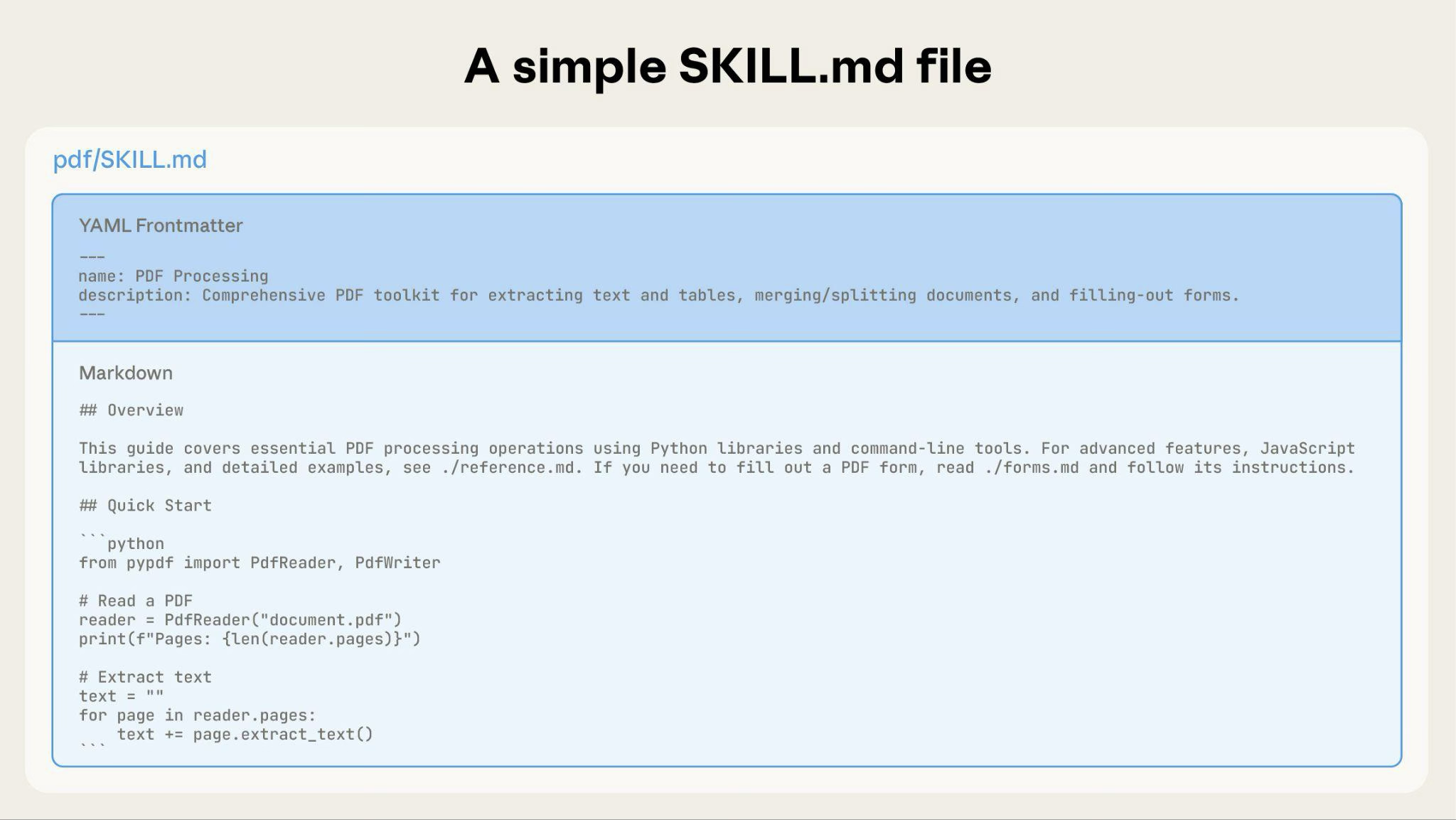
Ein einfacher Skill beginnt mit nur einer SKILL.md-Datei, die Metadaten und Anweisungen enthält:
Wenn dein Skill wächst, kannst du zusätzliche Inhalte bündeln, die Claude nur bei Bedarf lädt:

Die vollständige Skill-Verzeichnisstruktur könnte so aussehen:
pdf/
├── SKILL.md # Main instructions (loaded when triggered)
├── FORMS.md # Form-filling guide (loaded as needed)
├── reference.md # API reference (loaded as needed)
├── examples.md # Usage examples (loaded as needed)
└── scripts/
├── analyze_form.py # Utility script (executed, not loaded)
├── fill_form.py # Form filling script
└── validate.py # Validation script---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patternsClaude lädt FORMS.md, REFERENCE.md oder EXAMPLES.md nur bei Bedarf.
Für Skills mit mehreren Domänen organisiere Inhalte nach Domäne, um das Laden irrelevanten Kontexts zu vermeiden. Wenn ein Nutzer nach Verkaufsmetriken fragt, muss Claude nur verkaufsbezogene Schemata lesen, nicht Finanz- oder Marketingdaten. Dies hält die Token-Nutzung niedrig und den Kontext fokussiert.
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)# BigQuery Data Analysis
## Available datasets
**Finance**: Revenue, ARR, billing → See [reference/finance.md](reference/finance.md)
**Sales**: Opportunities, pipeline, accounts → See [reference/sales.md](reference/sales.md)
**Product**: API usage, features, adoption → See [reference/product.md](reference/product.md)
**Marketing**: Campaigns, attribution, email → See [reference/marketing.md](reference/marketing.md)
## Quick search
Find specific metrics using grep:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```Zeige grundlegende Inhalte, verlinke auf erweiterte Inhalte:
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)Claude liest REDLINING.md oder OOXML.md nur, wenn der Nutzer diese Funktionen benötigt.
Claude liest Dateien möglicherweise nur teilweise, wenn sie von anderen referenzierten Dateien aus referenziert werden. Bei verschachtelten Referenzen verwendet Claude möglicherweise Befehle wie head -100, um Inhalte in der Vorschau anzuzeigen, anstatt ganze Dateien zu lesen, was zu unvollständigen Informationen führt.
Halte Referenzen eine Ebene tief von SKILL.md aus. Alle Referenzdateien sollten direkt von SKILL.md aus verlinkt sein, um sicherzustellen, dass Claude bei Bedarf vollständige Dateien liest.
Schlechtes Beispiel: Zu tief:
# SKILL.md
See [advanced.md](advanced.md)...
# advanced.md
See [details.md](details.md)...
# details.md
Here's the actual information...Gutes Beispiel: Eine Ebene tief:
# SKILL.md
**Basic usage**: [instructions in SKILL.md]
**Advanced features**: See [advanced.md](advanced.md)
**API reference**: See [reference.md](reference.md)
**Examples**: See [examples.md](examples.md)Für Referenzdateien mit mehr als 100 Zeilen füge oben ein Inhaltsverzeichnis ein. Dies stellt sicher, dass Claude den vollen Umfang der verfügbaren Informationen sehen kann, auch wenn nur ein Teil der Datei in der Vorschau angezeigt wird.
Beispiel:
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
## Authentication and setup
...
## Core methods
...Claude kann dann die vollständige Datei lesen oder bei Bedarf zu bestimmten Abschnitten springen.
Für Details dazu, wie diese dateisystembasierte Architektur progressive Offenlegung ermöglicht, siehe den Abschnitt Laufzeitumgebung im Abschnitt „Fortgeschritten" weiter unten.
Zerlege komplexe Operationen in klare, sequenzielle Schritte. Für besonders komplexe Workflows stelle eine Checkliste bereit, die Claude in seine Antwort kopieren und beim Fortschreiten abhaken kann.
Beispiel 1: Workflow zur Recherche-Synthese (für Skills ohne Code):
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.Dieses Beispiel zeigt, wie Workflows auf Analyseaufgaben angewendet werden, die keinen Code erfordern. Das Checklisten-Muster funktioniert für jeden komplexen, mehrstufigen Prozess.
Beispiel 2: Workflow zum Ausfüllen von PDF-Formularen (für Skills mit Code):
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
```
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
```
**Step 1: Analyze the form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create field mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify output**
Run: `python scripts/verify_output.py output.pdf`
If verification fails, return to Step 2.Klare Schritte verhindern, dass Claude kritische Validierungen überspringt. Die Checkliste hilft sowohl Claude als auch dir, den Fortschritt durch mehrstufige Workflows zu verfolgen.
Häufiges Muster: Validator ausführen → Fehler beheben → wiederholen
Dieses Muster verbessert die Ausgabequalität erheblich.
Beispiel 1: Einhaltung des Styleguides (für Skills ohne Code):
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the documentDies zeigt das Validierungsschleifen-Muster unter Verwendung von Referenzdokumenten anstelle von Skripten. Der „Validator" ist STYLE_GUIDE.md, und Claude führt die Prüfung durch Lesen und Vergleichen durch.
Beispiel 2: Dokumentbearbeitungsprozess (für Skills mit Code):
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test the output documentDie Validierungsschleife erkennt Fehler frühzeitig.
Füge keine Informationen ein, die veralten werden:
Schlechtes Beispiel: Zeitkritisch (wird falsch werden):
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.Gutes Beispiel (verwende einen Abschnitt „alte Muster"):
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>Der Abschnitt „alte Muster" bietet historischen Kontext, ohne den Hauptinhalt zu überladen.
Wähle einen Begriff und verwende ihn durchgehend im Skill:
Gut – Konsistent:
Schlecht – Inkonsistent:
Konsistenz hilft Claude, Anweisungen zu verstehen und zu befolgen.
Stelle Templates für das Ausgabeformat bereit. Passe den Grad der Strenge an deine Anforderungen an.
Für strenge Anforderungen (wie API-Antworten oder Datenformate):
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```Für flexible Anleitung (wenn Anpassung nützlich ist):
## Report structure
Here is a sensible default format, but use your best judgment based on the analysis:
```markdown
# [Analysis Title]
## Executive summary
[Overview]
## Key findings
[Adapt sections based on what you discover]
## Recommendations
[Tailor to the specific context]
```
Adjust sections as needed for the specific analysis type.Für Skills, bei denen die Ausgabequalität davon abhängt, Beispiele zu sehen, stelle Input/Output-Paare bereit, genau wie beim regulären Prompting:
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
**Example 3:**
Input: Updated dependencies and refactored error handling
Output:
```
chore: update dependencies and refactor error handling
- Upgrade lodash to 4.17.21
- Standardize error response format across endpoints
```
Follow this style: type(scope): brief description, then detailed explanation.Beispiele helfen Claude, den gewünschten Stil und Detailgrad klarer zu verstehen als Beschreibungen allein.
Führe Claude durch Entscheidungspunkte:
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when completeWenn Workflows groß oder kompliziert mit vielen Schritten werden, erwäge, sie in separate Dateien auszulagern und Claude anzuweisen, die passende Datei basierend auf der aktuellen Aufgabe zu lesen.
Erstelle Evaluierungen, BEVOR du umfangreiche Dokumentation schreibst. Dies stellt sicher, dass dein Skill reale Probleme löst, anstatt imaginäre zu dokumentieren.
Evaluierungsgetriebene Entwicklung:
Dieser Ansatz stellt sicher, dass du tatsächliche Probleme löst, anstatt Anforderungen zu antizipieren, die möglicherweise nie eintreten.
Evaluierungsstruktur:
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF file and save it to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file using an appropriate PDF processing library or command-line tool",
"Extracts text content from all pages in the document without missing any pages",
"Saves the extracted text to a file named output.txt in a clear, readable format"
]
}Dieses Beispiel demonstriert eine datengetriebene Evaluierung mit einer einfachen Testrubrik. Es gibt derzeit keine integrierte Möglichkeit, diese Evaluierungen auszuführen. Nutzer können ihr eigenes Evaluierungssystem erstellen. Evaluierungen sind deine Quelle der Wahrheit für die Messung der Skill-Effektivität.
Der effektivste Skill-Entwicklungsprozess bezieht Claude selbst mit ein. Arbeite mit einer Instanz von Claude („Claude A"), um einen Skill zu erstellen, der von anderen Instanzen („Claude B") verwendet wird. Claude A hilft dir, Anweisungen zu entwerfen und zu verfeinern, während Claude B sie in realen Aufgaben testet. Dies funktioniert, weil Claude-Modelle sowohl verstehen, wie man effektive Agenten-Anweisungen schreibt, als auch welche Informationen Agenten benötigen.
Einen neuen Skill erstellen:
Eine Aufgabe ohne Skill abschließen: Arbeite ein Problem mit Claude A durch normales Prompting durch. Während du arbeitest, wirst du natürlich Kontext bereitstellen, Präferenzen erklären und prozedurales Wissen teilen. Achte darauf, welche Informationen du wiederholt bereitstellst.
Das wiederverwendbare Muster identifizieren: Nach Abschluss der Aufgabe identifiziere, welchen Kontext du bereitgestellt hast, der für ähnliche zukünftige Aufgaben nützlich wäre.
Beispiel: Wenn du eine BigQuery-Analyse durchgearbeitet hast, hast du möglicherweise Tabellennamen, Felddefinitionen, Filterregeln (wie „Testkonten immer ausschließen") und gängige Abfragemuster bereitgestellt.
Claude A bitten, einen Skill zu erstellen: „Erstelle einen Skill, der dieses BigQuery-Analysemuster erfasst, das wir gerade verwendet haben. Füge die Tabellenschemata, Namenskonventionen und die Regel zum Filtern von Testkonten ein."
Claude-Modelle verstehen das Skill-Format und die Struktur nativ. Du brauchst keine speziellen System-Prompts oder einen „Skills schreiben"-Skill, damit Claude beim Erstellen von Skills hilft. Bitte Claude einfach, einen Skill zu erstellen, und es generiert ordnungsgemäß strukturierten SKILL.md-Inhalt mit passendem Frontmatter und Body-Inhalt.
Auf Prägnanz prüfen: Überprüfe, ob Claude A keine unnötigen Erklärungen hinzugefügt hat. Frage: „Entferne die Erklärung, was Win-Rate bedeutet – Claude weiß das bereits."
Informationsarchitektur verbessern: Bitte Claude A, den Inhalt effektiver zu organisieren. Zum Beispiel: „Organisiere das so, dass das Tabellenschema in einer separaten Referenzdatei ist. Wir fügen später möglicherweise weitere Tabellen hinzu."
Auf ähnlichen Aufgaben testen: Verwende den Skill mit Claude B (einer frischen Instanz mit geladenem Skill) für verwandte Anwendungsfälle. Beobachte, ob Claude B die richtigen Informationen findet, Regeln korrekt anwendet und die Aufgabe erfolgreich bewältigt.
Basierend auf Beobachtung iterieren: Wenn Claude B Schwierigkeiten hat oder etwas übersieht, kehre mit Details zu Claude A zurück: „Als Claude diesen Skill verwendet hat, hat es vergessen, für Q4 nach Datum zu filtern. Sollten wir einen Abschnitt über Datumsfiltermuster hinzufügen?"
An bestehenden Skills iterieren:
Das gleiche hierarchische Muster setzt sich beim Verbessern von Skills fort. Du wechselst zwischen:
Den Skill in realen Workflows verwenden: Gib Claude B (mit geladenem Skill) tatsächliche Aufgaben, keine Testszenarien
Claude Bs Verhalten beobachten: Notiere, wo es Schwierigkeiten hat, erfolgreich ist oder unerwartete Entscheidungen trifft
Beispielbeobachtung: „Als ich Claude B nach einem regionalen Verkaufsbericht gefragt habe, hat es die Abfrage geschrieben, aber vergessen, Testkonten herauszufiltern, obwohl der Skill diese Regel erwähnt."
Zu Claude A für Verbesserungen zurückkehren: Teile die aktuelle SKILL.md und beschreibe, was du beobachtet hast. Frage: „Mir ist aufgefallen, dass Claude B vergessen hat, Testkonten zu filtern, als ich nach einem regionalen Bericht gefragt habe. Der Skill erwähnt das Filtern, aber vielleicht ist es nicht prominent genug?"
Claude As Vorschläge prüfen: Claude A könnte vorschlagen, neu zu organisieren, um Regeln prominenter zu machen, stärkere Formulierungen wie „MUSS filtern" statt „immer filtern" zu verwenden oder den Workflow-Abschnitt umzustrukturieren.
Änderungen anwenden und testen: Aktualisiere den Skill mit Claude As Verfeinerungen, dann teste erneut mit Claude B bei ähnlichen Anfragen
Basierend auf Nutzung wiederholen: Setze diesen Beobachten-Verfeinern-Testen-Zyklus fort, wenn du auf neue Szenarien stößt. Jede Iteration verbessert den Skill basierend auf realem Agentenverhalten, nicht auf Annahmen.
Team-Feedback sammeln:
Warum dieser Ansatz funktioniert: Claude A versteht Agentenbedürfnisse, du bringst Domänenexpertise ein, Claude B deckt Lücken durch reale Nutzung auf, und iterative Verfeinerung verbessert Skills basierend auf beobachtetem Verhalten statt auf Annahmen.
Während du an Skills iterierst, achte darauf, wie Claude sie in der Praxis tatsächlich verwendet. Achte auf:
Iteriere basierend auf diesen Beobachtungen statt auf Annahmen. Die Felder 'name' und 'description' in den Metadaten deines Skills sind besonders kritisch. Claude verwendet diese bei der Entscheidung, ob der Skill als Reaktion auf die aktuelle Aufgabe ausgelöst werden soll. Stelle sicher, dass sie klar beschreiben, was der Skill tut und wann er verwendet werden sollte.
Verwende immer Schrägstriche in Dateipfaden, auch unter Windows:
scripts/helper.py, reference/guide.mdscripts\helper.py, reference\guide.mdUnix-artige Pfade funktionieren auf allen Plattformen, während Windows-artige Pfade auf Unix-Systemen Fehler verursachen.
Präsentiere nicht mehrere Ansätze, es sei denn, es ist notwendig:
**Bad example: Too many choices** (confusing):
"You can use pypdf, or pdfplumber, or PyMuPDF, or pdf2image, or..."
**Good example: Provide a default** (with escape hatch):
"Use pdfplumber for text extraction:
```python
import pdfplumber
```
For scanned PDFs requiring OCR, use pdf2image with pytesseract instead."Die folgenden Abschnitte konzentrieren sich auf Skills, die ausführbare Skripte enthalten. Wenn dein Skill nur Markdown-Anweisungen verwendet, springe zu Checkliste für effektive Skills.
Wenn du Skripte für Skills schreibst, behandle Fehlerbedingungen, anstatt sie an Claude weiterzureichen.
Gutes Beispiel: Fehler explizit behandeln:
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# Erstelle Datei mit Standardinhalt, anstatt fehlzuschlagen
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# Biete Alternative an, anstatt fehlzuschlagen
print(f"Cannot access {path}, using default")
return ""Schlechtes Beispiel: An Claude weiterreichen:
def process_file(path):
# Einfach fehlschlagen lassen und Claude den Rest herausfinden lassen
return open(path).read()Konfigurationsparameter sollten ebenfalls begründet und dokumentiert sein, um „Voodoo-Konstanten" (Ousterhouts Gesetz) zu vermeiden. Wenn du den richtigen Wert nicht kennst, wie soll Claude ihn bestimmen?
Gutes Beispiel: Selbstdokumentierend:
# HTTP-Anfragen werden typischerweise innerhalb von 30 Sekunden abgeschlossen
# Längeres Timeout berücksichtigt langsame Verbindungen
REQUEST_TIMEOUT = 30
# Drei Wiederholungen balancieren Zuverlässigkeit und Geschwindigkeit
# Die meisten vorübergehenden Fehler lösen sich beim zweiten Versuch
MAX_RETRIES = 3Schlechtes Beispiel: Magische Zahlen:
TIMEOUT = 47 # Why 47?
RETRIES = 5 # Why 5?Auch wenn Claude ein Skript schreiben könnte, bieten vorgefertigte Skripte Vorteile:
Vorteile von Utility-Skripten:

Das obige Diagramm zeigt, wie ausführbare Skripte neben Anweisungsdateien funktionieren. Die Anweisungsdatei (forms.md) referenziert das Skript, und Claude kann es ausführen, ohne seinen Inhalt in den Kontext zu laden.
Wichtige Unterscheidung: Mache in deinen Anweisungen klar, ob Claude:
analyze_form.py aus, um Felder zu extrahieren"analyze_form.py für den Feldextraktionsalgorithmus"Für die meisten Utility-Skripte wird die Ausführung bevorzugt, da sie zuverlässiger und effizienter ist. Siehe den Abschnitt Laufzeitumgebung unten für Details zur Funktionsweise der Skriptausführung.
Beispiel:
## Utility scripts
**analyze_form.py**: Extract all form fields from PDF
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
Output format:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**: Check for overlapping bounding boxes
```bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
```
**fill_form.py**: Apply field values to PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```Wenn Eingaben als Bilder gerendert werden können, lass Claude sie analysieren:
## Form layout analysis
1. Convert PDF to images:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. Analyze each page image to identify form fields
3. Claude can see field locations and types visuallyIn diesem Beispiel müsstest du das Skript pdf_to_images.py schreiben.
Claudes Vision-Fähigkeiten helfen, Layouts und Strukturen zu verstehen.
Wenn Claude komplexe, offene Aufgaben ausführt, kann es Fehler machen. Das „Planen-Validieren-Ausführen"-Muster erkennt Fehler frühzeitig, indem Claude zuerst einen Plan in einem strukturierten Format erstellt und diesen Plan dann mit einem Skript validiert, bevor er ausgeführt wird.
Beispiel: Stell dir vor, du bittest Claude, 50 Formularfelder in einem PDF basierend auf einer Tabelle zu aktualisieren. Ohne Validierung könnte Claude nicht existierende Felder referenzieren, widersprüchliche Werte erstellen, erforderliche Felder übersehen oder Aktualisierungen falsch anwenden.
Lösung: Verwende das oben gezeigte Workflow-Muster (PDF-Formular ausfüllen), aber füge eine Zwischendatei changes.json hinzu, die validiert wird, bevor Änderungen angewendet werden. Der Workflow wird zu: analysieren → Plandatei erstellen → Plan validieren → ausführen → verifizieren.
Warum dieses Muster funktioniert:
Wann verwenden: Batch-Operationen, destruktive Änderungen, komplexe Validierungsregeln, Operationen mit hohem Risiko.
Implementierungstipp: Mache Validierungsskripte ausführlich mit spezifischen Fehlermeldungen wie „Feld 'signature_date' nicht gefunden. Verfügbare Felder: customer_name, order_total, signature_date_signed", um Claude beim Beheben von Problemen zu helfen.
Skills laufen in der Code-Ausführungsumgebung mit plattformspezifischen Einschränkungen:
Liste erforderliche Pakete in deiner SKILL.md auf und überprüfe, ob sie in der Dokumentation zum Code-Ausführungs-Tool verfügbar sind.
Skills laufen in einer Code-Ausführungsumgebung mit Dateisystemzugriff, Bash-Befehlen und Code-Ausführungsfähigkeiten. Für die konzeptionelle Erklärung dieser Architektur siehe Die Skills-Architektur in der Übersicht.
Wie sich das auf dein Authoring auswirkt:
Wie Claude auf Skills zugreift:
reference/guide.md), keine Backslashesform_validation_rules.md, nicht doc2.mdreference/finance.md, reference/sales.mddocs/file1.md, docs/file2.mdvalidate_form.py, anstatt Claude zu bitten, Validierungscode zu generierenanalyze_form.py aus, um Felder zu extrahieren" (ausführen)analyze_form.py für den Extraktionsalgorithmus" (als Referenz lesen)Beispiel:
bigquery-skill/
├── SKILL.md (overview, points to reference files)
└── reference/
├── finance.md (revenue metrics)
├── sales.md (pipeline data)
└── product.md (usage analytics)Wenn der Nutzer nach Umsatz fragt, liest Claude SKILL.md, sieht die Referenz auf reference/finance.md und ruft Bash auf, um nur diese Datei zu lesen. Die Dateien sales.md und product.md bleiben im Dateisystem und verbrauchen null Kontext-Token, bis sie benötigt werden. Dieses dateisystembasierte Modell ermöglicht progressive Offenlegung. Claude kann navigieren und selektiv genau das laden, was jede Aufgabe erfordert.
Für vollständige Details zur technischen Architektur siehe Wie Skills funktionieren in der Skills-Übersicht.
Wenn dein Skill MCP-Tools („Model Context Protocol") verwendet, verwende immer vollständig qualifizierte Tool-Namen, um „Tool nicht gefunden"-Fehler zu vermeiden.
Format: ServerName:tool_name
Beispiel:
Use the BigQuery:bigquery_schema tool to retrieve table schemas.
Use the GitHub:create_issue tool to create issues.Dabei gilt:
BigQuery und GitHub sind MCP-Servernamenbigquery_schema und create_issue sind die Tool-Namen innerhalb dieser ServerOhne das Server-Präfix kann Claude das Tool möglicherweise nicht finden, insbesondere wenn mehrere MCP-Server verfügbar sind.
Gehe nicht davon aus, dass Pakete verfügbar sind:
**Bad example: Assumes installation**:
"Use the pdf library to process the file."
**Good example: Explicit about dependencies**:
"Install required package: `pip install pypdf`
Then use it:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"Das SKILL.md-Frontmatter erfordert die Felder name und description mit spezifischen Validierungsregeln:
name: Maximal 64 Zeichen, nur Kleinbuchstaben/Zahlen/Bindestriche, keine XML-Tags, keine reservierten Wörterdescription: Maximal 1024 Zeichen, nicht leer, keine XML-TagsSiehe die Skills-Übersicht für vollständige Strukturdetails.
Halte den SKILL.md-Body unter 500 Zeilen für optimale Leistung. Wenn dein Inhalt dies überschreitet, teile ihn in separate Dateien auf, indem du die zuvor beschriebenen Muster für progressive Offenlegung verwendest. Für architektonische Details siehe die Skills-Übersicht.
Bevor du einen Skill teilst, überprüfe:
Erstelle deinen ersten Skill
Erstelle und verwalte Skills in Claude Code
Lade Skills programmatisch hoch und verwende sie
Was this page helpful?