Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Der Aufbau einer erfolgreichen LLM-basierten Anwendung beginnt damit, deine Erfolgskriterien klar zu definieren und dann Evaluierungen zu entwerfen, um die Leistung daran zu messen. Dieser Zyklus ist zentral für das Prompt Engineering.
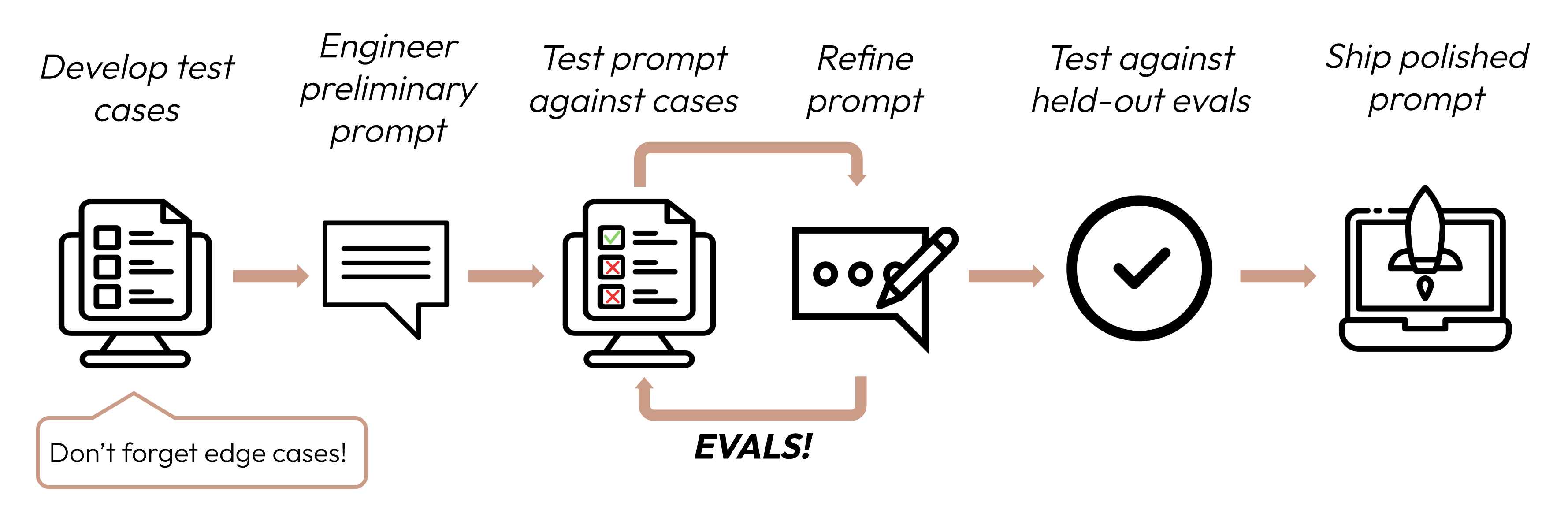
Gute Erfolgskriterien sind:
Spezifisch: Definiere klar, was du erreichen möchtest. Statt „gute Leistung" spezifiziere „genaue Sentiment-Klassifizierung".
Messbar: Verwende quantitative Metriken oder klar definierte qualitative Skalen. Zahlen bieten Klarheit und Skalierbarkeit, aber qualitative Maße können wertvoll sein, wenn sie konsistent zusammen mit quantitativen Maßen angewendet werden.
| Sicherheitskriterien | |
|---|---|
| Schlecht | Sichere Ausgaben |
| Gut | Weniger als 0,1 % der Ausgaben aus 10.000 Versuchen werden von unserem Content-Filter als toxisch markiert. |
Erreichbar: Basiere deine Ziele auf Branchen-Benchmarks, früheren Experimenten, KI-Forschung oder Expertenwissen. Deine Erfolgsmetriken sollten nicht unrealistisch im Vergleich zu den aktuellen Fähigkeiten von Frontier-Modellen sein.
Relevant: Richte deine Kriterien am Zweck deiner Anwendung und den Bedürfnissen der Nutzer aus. Hohe Zitationsgenauigkeit mag für medizinische Apps entscheidend sein, für lockere Chatbots jedoch weniger.
Hier sind einige Kriterien, die für deinen Anwendungsfall wichtig sein könnten. Diese Liste ist nicht vollständig.
Die meisten Anwendungsfälle benötigen eine mehrdimensionale Evaluierung entlang mehrerer Erfolgskriterien.
Wenn du entscheidest, welche Methode zur Bewertung von Evals verwendet werden soll, wähle die schnellste, zuverlässigste und skalierbarste Methode:
Code-basierte Bewertung: Am schnellsten und zuverlässigsten, extrem skalierbar, aber es fehlt an Nuancen für komplexere Beurteilungen, die weniger regelbasierte Starrheit erfordern.
output == golden_answerkey_phrase in outputMenschliche Bewertung: Am flexibelsten und von höchster Qualität, aber langsam und teuer. Vermeide sie, wenn möglich.
LLM-basierte Bewertung: Schnell und flexibel, skalierbar und geeignet für komplexe Beurteilungen. Teste zuerst, um die Zuverlässigkeit sicherzustellen, und skaliere dann.
Brainstorme Erfolgskriterien für deinen Anwendungsfall mit Claude auf claude.ai.
Tipp: Füge diese Seite als Orientierung für Claude in den Chat ein!
Weitere Code-Beispiele für von Menschen, Code und LLMs bewertete Evals.
Was this page helpful?