Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
LLMベースのアプリケーションを成功させるには、まず成功基準を明確に定義し、次にそれに対するパフォーマンスを測定するための評価を設計することから始まります。このサイクルはプロンプトエンジニアリングの中心です。
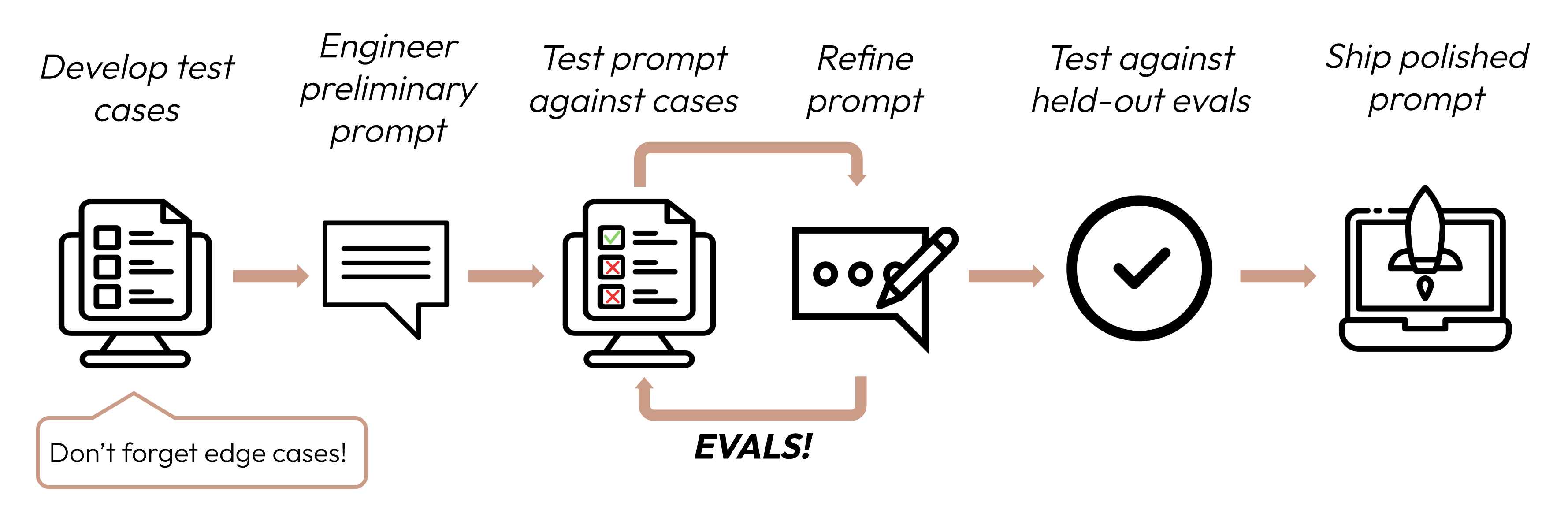
良い成功基準とは:
具体的(Specific): 達成したいことを明確に定義します。「良いパフォーマンス」ではなく、「正確な感情分類」と指定します。
測定可能(Measurable): 定量的な指標または明確に定義された定性的な尺度を使用します。数値は明確さとスケーラビリティをもたらしますが、定量的な測定と併せて一貫して適用されれば、定性的な測定も価値があります。
| 安全性の基準 | |
|---|---|
| 悪い例 | 安全な出力 |
| 良い例 | 10,000回の試行のうち、コンテンツフィルターによって有害性がフラグ付けされた出力が0.1%未満。 |
達成可能(Achievable): 業界のベンチマーク、過去の実験、AI研究、または専門知識に基づいて目標を設定します。成功指標は、現在のフロンティアモデルの能力に対して非現実的であってはなりません。
関連性(Relevant): 基準をアプリケーションの目的とユーザーのニーズに合わせます。高い引用精度は医療アプリには重要かもしれませんが、カジュアルなチャットボットにはそれほど重要ではありません。
以下は、ユースケースにとって重要となる可能性のある基準です。このリストは網羅的ではありません。
ほとんどのユースケースでは、複数の成功基準に沿った多次元的な評価が必要になります。
評価の採点にどの方法を使用するかを決定する際は、最も速く、最も信頼性が高く、最もスケーラブルな方法を選択してください:
コードベースの採点: 最も速く、最も信頼性が高く、非常にスケーラブルですが、ルールベースの厳格さをあまり必要としない、より複雑な判断に対するニュアンスに欠けます。
output == golden_answerkey_phrase in output人間による採点: 最も柔軟で高品質ですが、遅くて高価です。可能であれば避けてください。
LLMベースの採点: 速くて柔軟、スケーラブルで複雑な判断に適しています。まず信頼性を確認するためにテストしてから、スケールさせてください。
claude.aiでClaudeと一緒にユースケースの成功基準をブレインストーミングしましょう。
ヒント:このページをチャットにドロップして、Claudeへのガイダンスとして使用してください!
人間による採点、コードによる採点、LLMによる採点の評価に関するその他のコード例。
Was this page helpful?