Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
優れたスキルは、簡潔で、構造が整っており、実際の使用を通じてテストされています。このガイドでは、Claudeが発見し、効果的に使用できるスキルを書くための実践的な作成上の判断基準を提供します。
スキルの仕組みに関する概念的な背景については、スキルの概要を参照してください。
コンテキストウィンドウは共有リソースです。あなたのスキルは、Claudeが知る必要のある他のすべての情報とコンテキストウィンドウを共有します。これには以下が含まれます。
スキル内のすべてのトークンが即座にコストを発生させるわけではありません。起動時には、すべてのスキルのメタデータ(名前と説明)のみが事前に読み込まれます。ClaudeはスキルがRelevantになったときにのみSKILL.mdを読み込み、追加ファイルは必要に応じてのみ読み込みます。しかし、SKILL.mdを簡潔にすることは依然として重要です。Claudeがそれを読み込むと、すべてのトークンが会話履歴や他のコンテキストと競合するからです。
デフォルトの前提: Claudeはすでに非常に賢い
Claudeがまだ持っていないコンテキストのみを追加してください。各情報について以下を自問してください。
良い例:簡潔(約50トークン):
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```悪い例:冗長すぎる(約150トークン):
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but
pdfplumber is recommended because it's easy to use and handles most cases well.
First, you'll need to install it using pip. Then you can use the code below...簡潔なバージョンは、ClaudeがPDFとは何か、ライブラリがどのように機能するかを知っていることを前提としています。
具体性のレベルを、タスクの脆弱性と変動性に合わせてください。
高い自由度(テキストベースの指示):
使用する場面:
例:
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventions中程度の自由度(疑似コードまたはパラメータ付きスクリプト):
使用する場面:
例:
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```低い自由度(特定のスクリプト、パラメータがほとんどまたはまったくない):
使用する場面:
例:
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.例え: Claudeを経路を探索するロボットと考えてください。
スキルはモデルへの追加機能として機能するため、有効性は基盤となるモデルに依存します。使用予定のすべてのモデルでスキルをテストしてください。
モデル別のテストの考慮事項:
Opusで完璧に機能するものでも、Haikuではより詳細な説明が必要になる場合があります。複数のモデルでスキルを使用する予定がある場合は、すべてのモデルでうまく機能する指示を目指してください。
YAMLフロントマター: SKILL.mdのフロントマターには2つのフィールドが必要です。
name:
description:
スキル構造の完全な詳細については、スキルの概要を参照してください。
スキルを参照しやすく、議論しやすくするために、一貫した命名パターンを使用してください。スキル名には動名詞形(動詞 + -ing)の使用を検討してください。これにより、スキルが提供する活動や機能が明確に説明されます。
nameフィールドは小文字、数字、ハイフンのみを使用する必要があることに注意してください。
良い命名例(動名詞形):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation許容される代替案:
pdf-processing、spreadsheet-analysisprocess-pdfs、analyze-spreadsheets避けるべきもの:
helper、utils、toolsdocuments、data、filesanthropic-helper、claude-tools一貫した命名により、以下が容易になります。
descriptionフィールドはスキルの発見を可能にするもので、スキルが何をするか、いつ使用するかの両方を含める必要があります。
常に三人称で書いてください。説明はシステムプロンプトに挿入されるため、視点が一貫していないと発見に問題が生じる可能性があります。
具体的にし、キーワードを含めてください。スキルが何をするかと、いつ使用するかの具体的なトリガー/コンテキストの両方を含めてください。
各スキルには説明フィールドが1つだけあります。説明はスキル選択において重要です。Claudeはこれを使用して、100以上の利用可能なスキルの中から適切なスキルを選択します。説明は、Claudeがこのスキルをいつ選択すべきかを判断するのに十分な詳細を提供する必要があり、SKILL.mdの残りの部分が実装の詳細を提供します。
効果的な例:
PDF処理スキル:
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.Excel分析スキル:
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.Gitコミットヘルパースキル:
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.以下のような曖昧な説明は避けてください。
description: Helps with documentsdescription: Processes datadescription: Does stuff with filesSKILL.mdは、オンボーディングガイドの目次のように、必要に応じてClaudeを詳細な資料に導く概要として機能します。「progressive disclosure」(段階的開示)の仕組みの説明については、概要のスキルの仕組みを参照してください。
実践的なガイダンス:
基本的なスキルは、メタデータと指示を含むSKILL.mdファイルのみから始まります。
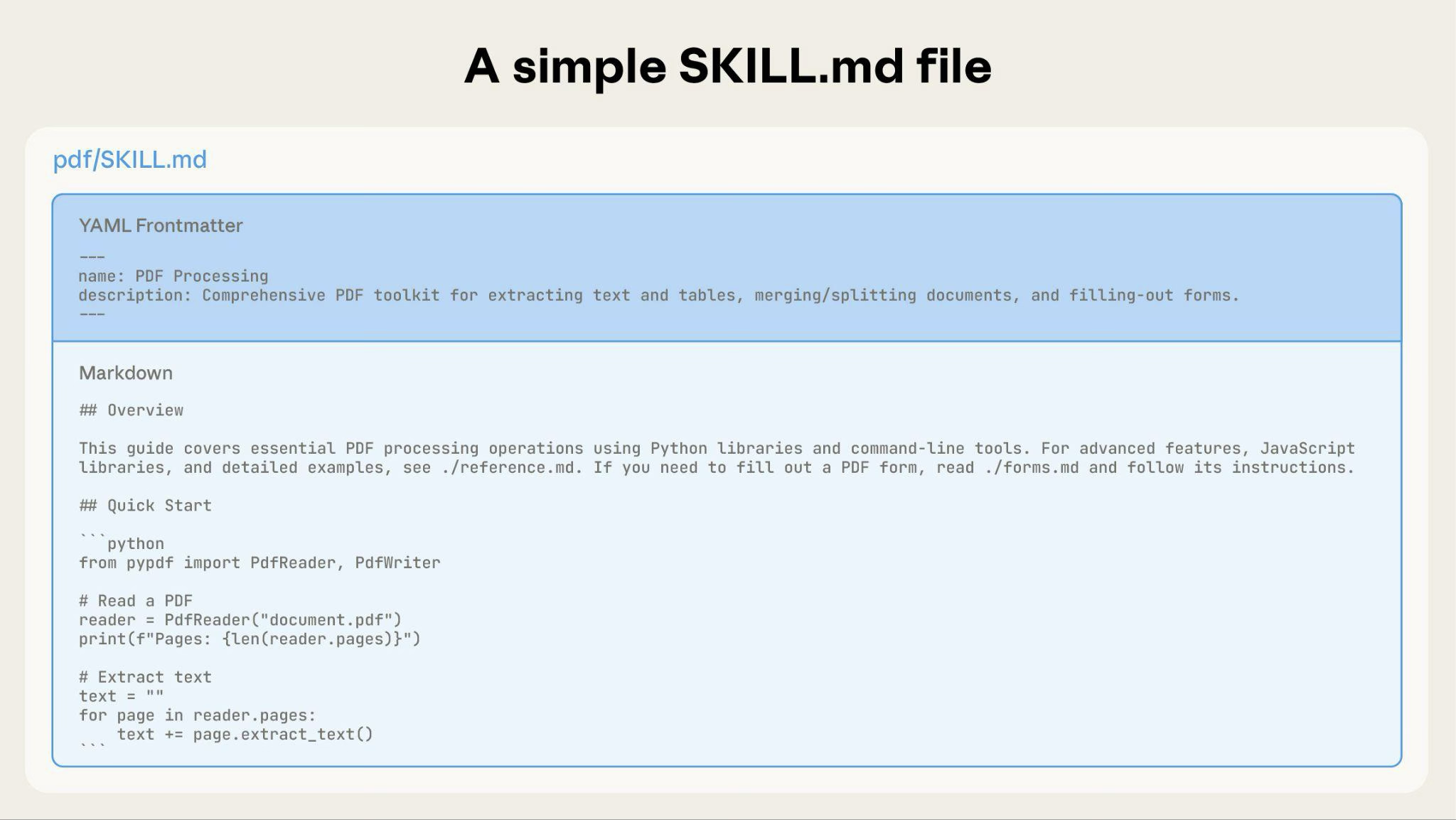
スキルが成長するにつれて、Claudeが必要なときにのみ読み込む追加コンテンツをバンドルできます。

完全なスキルディレクトリ構造は次のようになります。
pdf/
├── SKILL.md # Main instructions (loaded when triggered)
├── FORMS.md # Form-filling guide (loaded as needed)
├── reference.md # API reference (loaded as needed)
├── examples.md # Usage examples (loaded as needed)
└── scripts/
├── analyze_form.py # Utility script (executed, not loaded)
├── fill_form.py # Form filling script
└── validate.py # Validation script---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patternsClaudeは必要なときにのみFORMS.md、REFERENCE.md、またはEXAMPLES.mdを読み込みます。
複数のドメインを持つスキルの場合、無関係なコンテキストの読み込みを避けるために、コンテンツをドメイン別に整理します。ユーザーが売上指標について尋ねた場合、Claudeは財務やマーケティングのデータではなく、売上関連のスキーマのみを読む必要があります。これにより、トークン使用量が低く抑えられ、コンテキストが集中します。
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)# BigQuery Data Analysis
## Available datasets
**Finance**: Revenue, ARR, billing → See [reference/finance.md](reference/finance.md)
**Sales**: Opportunities, pipeline, accounts → See [reference/sales.md](reference/sales.md)
**Product**: API usage, features, adoption → See [reference/product.md](reference/product.md)
**Marketing**: Campaigns, attribution, email → See [reference/marketing.md](reference/marketing.md)
## Quick search
Find specific metrics using grep:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```基本的なコンテンツを表示し、高度なコンテンツへのリンクを提供します。
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)Claudeは、ユーザーがそれらの機能を必要とする場合にのみREDLINING.mdまたはOOXML.mdを読み込みます。
他の参照ファイルから参照されているファイルを、Claudeは部分的にしか読まない場合があります。ネストされた参照に遭遇すると、Claudeはファイル全体を読むのではなく、head -100のようなコマンドを使用してコンテンツをプレビューする可能性があり、情報が不完全になります。
参照はSKILL.mdから1レベルの深さに保ってください。すべての参照ファイルはSKILL.mdから直接リンクし、Claudeが必要なときに完全なファイルを読めるようにする必要があります。
悪い例:深すぎる:
# SKILL.md
See [advanced.md](advanced.md)...
# advanced.md
See [details.md](details.md)...
# details.md
Here's the actual information...良い例:1レベルの深さ:
# SKILL.md
**Basic usage**: [instructions in SKILL.md]
**Advanced features**: See [advanced.md](advanced.md)
**API reference**: See [reference.md](reference.md)
**Examples**: See [examples.md](examples.md)100行を超える参照ファイルには、先頭に目次を含めてください。これにより、Claudeが部分読み込みでプレビューする場合でも、利用可能な情報の全範囲を確認できます。
例:
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
## Authentication and setup
...
## Core methods
...Claudeは必要に応じて、ファイル全体を読むか、特定のセクションにジャンプできます。
このファイルシステムベースのアーキテクチャが段階的開示をどのように可能にするかの詳細については、以下の「高度な内容」セクションのランタイム環境セクションを参照してください。
複雑な操作を明確で順序立ったステップに分解します。特に複雑なワークフローの場合は、Claudeが応答にコピーして進行状況に応じてチェックできるチェックリストを提供してください。
例1:リサーチ統合ワークフロー(コードを含まないスキル向け):
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.この例は、コードを必要としない分析タスクにワークフローがどのように適用されるかを示しています。チェックリストパターンは、あらゆる複雑な複数ステップのプロセスに適用できます。
例2:PDFフォーム入力ワークフロー(コードを含むスキル向け):
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
```
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
```
**Step 1: Analyze the form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create field mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify output**
Run: `python scripts/verify_output.py output.pdf`
If verification fails, return to Step 2.明確なステップにより、Claudeが重要な検証をスキップすることを防ぎます。チェックリストは、Claudeとあなたの両方が複数ステップのワークフローの進捗を追跡するのに役立ちます。
一般的なパターン: バリデーターを実行 → エラーを修正 → 繰り返す
このパターンは出力品質を大幅に向上させます。
例1:スタイルガイド準拠(コードを含まないスキル向け):
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the documentこれは、スクリプトの代わりに参照ドキュメントを使用した検証ループパターンを示しています。「バリデーター」はSTYLE_GUIDE.mdであり、Claudeは読み取りと比較によってチェックを実行します。
例2:ドキュメント編集プロセス(コードを含むスキル向け):
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test the output document検証ループはエラーを早期に検出します。
古くなる情報を含めないでください。
悪い例:時間に依存する(いずれ間違いになる):
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.良い例(「古いパターン」セクションを使用):
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>古いパターンセクションは、メインコンテンツを煩雑にすることなく、歴史的なコンテキストを提供します。
1つの用語を選び、スキル全体で使用してください。
良い - 一貫している:
悪い - 一貫していない:
一貫性は、Claudeが指示を理解し、従うのに役立ちます。
出力形式のテンプレートを提供します。厳密さのレベルをニーズに合わせてください。
厳密な要件の場合(APIレスポンスやデータ形式など):
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```柔軟なガイダンスの場合(適応が有用な場合):
## Report structure
Here is a sensible default format, but use your best judgment based on the analysis:
```markdown
# [Analysis Title]
## Executive summary
[Overview]
## Key findings
[Adapt sections based on what you discover]
## Recommendations
[Tailor to the specific context]
```
Adjust sections as needed for the specific analysis type.出力品質が例を見ることに依存するスキルの場合、通常のプロンプティングと同様に入力/出力のペアを提供します。
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
**Example 3:**
Input: Updated dependencies and refactored error handling
Output:
```
chore: update dependencies and refactor error handling
- Upgrade lodash to 4.17.21
- Standardize error response format across endpoints
```
Follow this style: type(scope): brief description, then detailed explanation.例は、説明だけよりも、望ましいスタイルと詳細レベルをClaudeがより明確に理解するのに役立ちます。
Claudeを判断ポイントを通じて導きます。
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when completeワークフローが大きくなったり、多くのステップで複雑になったりした場合は、それらを別々のファイルに分割し、現在のタスクに基づいて適切なファイルを読むようにClaudeに指示することを検討してください。
広範なドキュメントを書く前に評価を作成してください。 これにより、スキルが想像上の問題ではなく、実際の問題を解決することが保証されます。
評価駆動開発:
このアプローチにより、実現しないかもしれない要件を予測するのではなく、実際の問題を解決していることが保証されます。
評価の構造:
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF file and save it to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file using an appropriate PDF processing library or command-line tool",
"Extracts text content from all pages in the document without missing any pages",
"Saves the extracted text to a file named output.txt in a clear, readable format"
]
}この例は、シンプルなテストルーブリックを使用したデータ駆動型の評価を示しています。現在、これらの評価を実行するための組み込みの方法はありません。ユーザーは独自の評価システムを作成できます。評価は、スキルの有効性を測定するための信頼できる情報源です。
最も効果的なスキル開発プロセスには、Claude自体が関与します。Claudeの1つのインスタンス(「Claude A」)と協力して、他のインスタンス(「Claude B」)が使用するスキルを作成します。Claude Aは指示の設計と改善を支援し、Claude Bは実際のタスクでそれらをテストします。これが機能するのは、Claudeモデルが効果的なエージェント指示の書き方と、エージェントが必要とする情報の両方を理解しているためです。
新しいスキルの作成:
スキルなしでタスクを完了する: 通常のプロンプティングを使用してClaude Aと問題に取り組みます。作業を進める中で、自然にコンテキストを提供し、好みを説明し、手続き的な知識を共有することになります。繰り返し提供している情報に注目してください。
再利用可能なパターンを特定する: タスクを完了した後、将来の類似タスクに役立つと思われる、提供したコンテキストを特定します。
例: BigQuery分析に取り組んだ場合、テーブル名、フィールド定義、フィルタリングルール(「常にテストアカウントを除外する」など)、一般的なクエリパターンを提供したかもしれません。
Claude Aにスキルの作成を依頼する: 「今使用したこのBigQuery分析パターンをキャプチャするスキルを作成してください。テーブルスキーマ、命名規則、テストアカウントのフィルタリングに関するルールを含めてください。」
Claudeモデルはスキルの形式と構造をネイティブに理解しています。Claudeにスキルの作成を手伝ってもらうために、特別なシステムプロンプトや「スキル作成」スキルは必要ありません。単にClaudeにスキルの作成を依頼すれば、適切なフロントマターと本文コンテンツを持つ、適切に構造化されたSKILL.mdコンテンツが生成されます。
簡潔さを確認する: Claude Aが不要な説明を追加していないか確認します。次のように依頼します。「勝率が何を意味するかの説明を削除してください。Claudeはすでにそれを知っています。」
情報アーキテクチャを改善する: Claude Aにコンテンツをより効果的に整理するよう依頼します。例:「テーブルスキーマが別の参照ファイルになるように整理してください。後でテーブルを追加するかもしれません。」
類似タスクでテストする: 関連するユースケースで、Claude B(スキルが読み込まれた新しいインスタンス)でスキルを使用します。Claude Bが適切な情報を見つけ、ルールを正しく適用し、タスクを正常に処理するかどうかを観察します。
観察に基づいて反復する: Claude Bが苦労したり、何かを見逃したりした場合は、具体的な内容を持ってClaude Aに戻ります。「Claudeがこのスキルを使用したとき、Q4の日付でフィルタリングするのを忘れました。日付フィルタリングパターンに関するセクションを追加すべきでしょうか?」
既存のスキルの反復:
スキルを改善する際も、同じ階層的なパターンが続きます。以下を交互に行います。
実際のワークフローでスキルを使用する: Claude B(スキルが読み込まれた状態)にテストシナリオではなく、実際のタスクを与えます
Claude Bの動作を観察する: 苦労している箇所、成功している箇所、予期しない選択をしている箇所に注目します
観察例: 「Claude Bに地域別売上レポートを依頼したとき、クエリは書きましたが、スキルにこのルールが記載されているにもかかわらず、テストアカウントを除外するのを忘れました。」
改善のためにClaude Aに戻る: 現在のSKILL.mdを共有し、観察したことを説明します。次のように尋ねます。「地域別レポートを依頼したとき、Claude Bがテストアカウントのフィルタリングを忘れていることに気づきました。スキルにはフィルタリングについて記載されていますが、十分に目立っていないのかもしれません。」
Claude Aの提案を確認する: Claude Aは、ルールをより目立たせるための再編成、「always filter」の代わりに「MUST filter」のようなより強い表現の使用、またはワークフローセクションの再構築を提案するかもしれません。
変更を適用してテストする: Claude Aの改善でスキルを更新し、類似のリクエストでClaude Bで再度テストします
使用状況に基づいて繰り返す: 新しいシナリオに遭遇するたびに、この観察-改善-テストのサイクルを続けます。各反復は、仮定ではなく実際のエージェントの動作に基づいてスキルを改善します。
チームからのフィードバックの収集:
このアプローチが機能する理由: Claude Aはエージェントのニーズを理解し、あなたはドメインの専門知識を提供し、Claude Bは実際の使用を通じてギャップを明らかにし、反復的な改善は仮定ではなく観察された動作に基づいてスキルを改善します。
スキルを反復する際は、Claudeが実際にそれらをどのように使用しているかに注意を払ってください。以下を確認してください。
仮定ではなく、これらの観察に基づいて反復してください。スキルのメタデータの「name」と「description」は特に重要です。Claudeは、現在のタスクに応じてスキルをトリガーするかどうかを決定する際にこれらを使用します。スキルが何をするか、いつ使用すべきかを明確に説明していることを確認してください。
Windowsでも、ファイルパスには常にスラッシュを使用してください。
scripts/helper.py、reference/guide.mdscripts\helper.py、reference\guide.mdUnixスタイルのパスはすべてのプラットフォームで機能しますが、WindowsスタイルのパスはUnixシステムでエラーを引き起こします。
必要でない限り、複数のアプローチを提示しないでください。
**Bad example: Too many choices** (confusing):
"You can use pypdf, or pdfplumber, or PyMuPDF, or pdf2image, or..."
**Good example: Provide a default** (with escape hatch):
"Use pdfplumber for text extraction:
```python
import pdfplumber
```
For scanned PDFs requiring OCR, use pdf2image with pytesseract instead."以下のセクションは、実行可能なスクリプトを含むスキルに焦点を当てています。スキルがマークダウンの指示のみを使用する場合は、効果的なスキルのチェックリストにスキップしてください。
スキル用のスクリプトを書く際は、Claudeに丸投げするのではなく、エラー条件を処理してください。
良い例:エラーを明示的に処理する:
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# 失敗させる代わりにデフォルトの内容でファイルを作成
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# 失敗させる代わりに代替案を提供
print(f"Cannot access {path}, using default")
return ""悪い例:Claudeに丸投げする:
def process_file(path):
# 単に失敗させてClaudeに判断を任せる
return open(path).read()設定パラメータも、「voodoo constants」(ブードゥー定数、Ousterhoutの法則)を避けるために、正当化され文書化されるべきです。あなたが正しい値を知らないなら、Claudeはどうやってそれを判断するのでしょうか?
良い例:自己文書化:
# HTTPリクエストは通常30秒以内に完了します
# タイムアウトを長めに設定して低速な接続に対応します
REQUEST_TIMEOUT = 30
# 3回のリトライで信頼性と速度のバランスを取ります
# 断続的な障害のほとんどは2回目のリトライまでに解消します
MAX_RETRIES = 3悪い例:マジックナンバー:
TIMEOUT = 47 # Why 47?
RETRIES = 5 # Why 5?Claudeがスクリプトを書けるとしても、事前に作成されたスクリプトには利点があります。
ユーティリティスクリプトの利点:

上の図は、実行可能なスクリプトが指示ファイルと並んでどのように機能するかを示しています。指示ファイル(forms.md)はスクリプトを参照し、Claudeはその内容をコンテキストに読み込むことなく実行できます。
重要な区別: 指示の中で、Claudeが以下のどちらを行うべきかを明確にしてください。
analyze_form.pyを実行してフィールドを抽出する」analyze_form.pyを参照」ほとんどのユーティリティスクリプトでは、より信頼性が高く効率的であるため、実行が推奨されます。スクリプト実行の仕組みの詳細については、以下のランタイム環境セクションを参照してください。
例:
## Utility scripts
**analyze_form.py**: Extract all form fields from PDF
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
Output format:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**: Check for overlapping bounding boxes
```bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
```
**fill_form.py**: Apply field values to PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```入力を画像としてレンダリングできる場合は、Claudeにそれらを分析させます。
## Form layout analysis
1. Convert PDF to images:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. Analyze each page image to identify form fields
3. Claude can see field locations and types visuallyこの例では、pdf_to_images.pyスクリプトを書く必要があります。
Claudeのビジョン機能は、レイアウトと構造の理解に役立ちます。
Claudeが複雑でオープンエンドなタスクを実行する際、ミスをする可能性があります。「計画-検証-実行」パターンは、Claudeにまず構造化された形式で計画を作成させ、実行前にスクリプトでその計画を検証することで、エラーを早期に検出します。
例: スプレッドシートに基づいてPDFの50個のフォームフィールドを更新するようClaudeに依頼することを想像してください。検証なしでは、Claudeは存在しないフィールドを参照したり、矛盾する値を作成したり、必須フィールドを見逃したり、更新を誤って適用したりする可能性があります。
解決策: 上記のワークフローパターン(PDFフォーム入力)を使用しますが、変更を適用する前に検証される中間のchanges.jsonファイルを追加します。ワークフローは次のようになります:分析 → 計画ファイルを作成 → 計画を検証 → 実行 → 確認。
このパターンが機能する理由:
使用する場面: バッチ操作、破壊的な変更、複雑な検証ルール、重要度の高い操作。
実装のヒント: 検証スクリプトを詳細にし、「Field 'signature_date' not found. Available fields: customer_name, order_total, signature_date_signed」のような具体的なエラーメッセージを出力して、Claudeが問題を修正できるようにします。
スキルは、プラットフォーム固有の制限があるコード実行環境で実行されます。
必要なパッケージをSKILL.mdにリストし、コード実行ツールのドキュメントで利用可能であることを確認してください。
スキルは、ファイルシステムアクセス、bashコマンド、コード実行機能を備えたコード実行環境で実行されます。このアーキテクチャの概念的な説明については、概要のスキルのアーキテクチャを参照してください。
これが作成にどう影響するか:
Claudeがスキルにアクセスする方法:
reference/guide.md)を使用してくださいdoc2.mdではなくform_validation_rules.mdreference/finance.md、reference/sales.mddocs/file1.md、docs/file2.mdvalidate_form.pyを書きますanalyze_form.pyを実行してフィールドを抽出する」(実行)analyze_form.pyを参照」(参照として読む)例:
bigquery-skill/
├── SKILL.md (overview, points to reference files)
└── reference/
├── finance.md (revenue metrics)
├── sales.md (pipeline data)
└── product.md (usage analytics)ユーザーが収益について尋ねると、ClaudeはSKILL.mdを読み、reference/finance.mdへの参照を確認し、bashを呼び出してそのファイルのみを読み込みます。sales.mdとproduct.mdファイルはファイルシステム上に残り、必要になるまでコンテキストトークンをゼロ消費します。このファイルシステムベースのモデルが段階的開示を可能にします。Claudeは各タスクが必要とするものを正確にナビゲートし、選択的に読み込むことができます。
技術アーキテクチャの完全な詳細については、スキルの概要のスキルの仕組みを参照してください。
スキルがMCP(Model Context Protocol)ツールを使用する場合、「tool not found」エラーを避けるために、常に完全修飾ツール名を使用してください。
形式: ServerName:tool_name
例:
Use the BigQuery:bigquery_schema tool to retrieve table schemas.
Use the GitHub:create_issue tool to create issues.ここで:
BigQueryとGitHubはMCPサーバー名ですbigquery_schemaとcreate_issueはそれらのサーバー内のツール名ですサーバープレフィックスがないと、特に複数のMCPサーバーが利用可能な場合、Claudeはツールを見つけられない可能性があります。
パッケージが利用可能であると仮定しないでください。
**Bad example: Assumes installation**:
"Use the pdf library to process the file."
**Good example: Explicit about dependencies**:
"Install required package: `pip install pypdf`
Then use it:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"SKILL.mdのフロントマターには、特定の検証ルールを持つnameとdescriptionフィールドが必要です。
name:最大64文字、小文字/数字/ハイフンのみ、XMLタグなし、予約語なしdescription:最大1024文字、空でない、XMLタグなし完全な構造の詳細については、スキルの概要を参照してください。
最適なパフォーマンスのために、SKILL.mdの本文を500行未満に保ってください。コンテンツがこれを超える場合は、前述の段階的開示パターンを使用して別々のファイルに分割してください。アーキテクチャの詳細については、スキルの概要を参照してください。
スキルを共有する前に、以下を確認してください。
最初のスキルを作成する
Claude Codeでスキルを作成・管理する
プログラムでスキルをアップロードして使用する
Was this page helpful?