Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Costruire un'applicazione di successo basata su LLM inizia con la definizione chiara dei criteri di successo e poi con la progettazione di valutazioni per misurare le prestazioni rispetto a tali criteri. Questo ciclo è centrale nel prompt engineering.
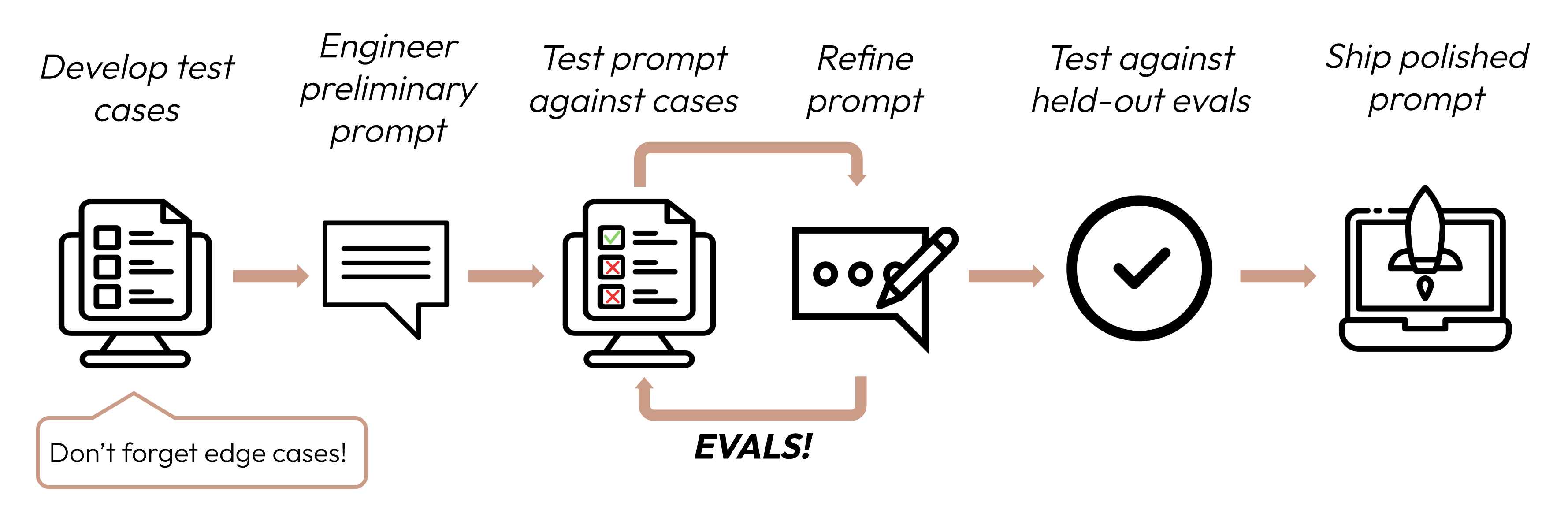
Buoni criteri di successo sono:
Specifici: Definisci chiaramente cosa vuoi ottenere. Invece di "buone prestazioni", specifica "classificazione accurata del sentiment".
Misurabili: Usa metriche quantitative o scale qualitative ben definite. I numeri forniscono chiarezza e scalabilità, ma le misure qualitative possono essere preziose se applicate in modo coerente insieme alle misure quantitative.
| Criteri di sicurezza | |
|---|---|
| Cattivo | Output sicuri |
| Buono | Meno dello 0,1% degli output su 10.000 prove segnalati per tossicità dal nostro filtro dei contenuti. |
Raggiungibili: Basa i tuoi obiettivi su benchmark di settore, esperimenti precedenti, ricerca sull'IA o conoscenze di esperti. Le tue metriche di successo non dovrebbero essere irrealistiche rispetto alle capacità attuali dei modelli di frontiera.
Rilevanti: Allinea i tuoi criteri allo scopo della tua applicazione e alle esigenze degli utenti. Un'elevata accuratezza delle citazioni potrebbe essere fondamentale per le app mediche, ma meno per i chatbot informali.
Ecco alcuni criteri che potrebbero essere importanti per il tuo caso d'uso. Questo elenco non è esaustivo.
La maggior parte dei casi d'uso richiederà una valutazione multidimensionale su diversi criteri di successo.
Quando decidi quale metodo utilizzare per valutare le eval, scegli il metodo più veloce, più affidabile e più scalabile:
Valutazione basata su codice: La più veloce e affidabile, estremamente scalabile, ma manca di sfumature per giudizi più complessi che richiedono meno rigidità basata su regole.
output == golden_answerkey_phrase in outputValutazione umana: La più flessibile e di alta qualità, ma lenta e costosa. Evitala se possibile.
Valutazione basata su LLM: Veloce e flessibile, scalabile e adatta a giudizi complessi. Testa prima per garantire l'affidabilità, poi scala.
Fai brainstorming sui criteri di successo per il tuo caso d'uso con Claude su claude.ai.
Suggerimento: Inserisci questa pagina nella chat come guida per Claude!
Altri esempi di codice di valutazioni umane, basate su codice e basate su LLM.
Was this page helpful?