Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Le Skill ben fatte sono concise, ben strutturate e testate con l'uso reale. Questa guida fornisce decisioni pratiche di authoring per aiutarti a scrivere Skill che Claude possa individuare e utilizzare in modo efficace.
Per il contesto concettuale su come funzionano le Skill, consulta la panoramica delle Skill.
La "context window" (finestra di contesto) è un bene pubblico. La tua Skill condivide la finestra di contesto con tutto il resto di ciò che Claude deve sapere, inclusi:
Non tutti i token nella tua Skill hanno un costo immediato. All'avvio, vengono precaricati solo i metadati (nome e descrizione) di tutte le Skill. Claude legge SKILL.md solo quando la Skill diventa rilevante e legge i file aggiuntivi solo quando necessario. Tuttavia, essere concisi in SKILL.md è comunque importante: una volta che Claude lo carica, ogni token compete con la cronologia della conversazione e altro contesto.
Assunzione predefinita: Claude è già molto intelligente
Aggiungi solo il contesto che Claude non ha già. Metti in discussione ogni informazione:
Buon esempio: Conciso (circa 50 token):
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```Cattivo esempio: Troppo prolisso (circa 150 token):
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but
pdfplumber is recommended because it's easy to use and handles most cases well.
First, you'll need to install it using pip. Then you can use the code below...La versione concisa presuppone che Claude sappia cosa sono i PDF e come funzionano le librerie.
Adatta il livello di specificità alla fragilità e variabilità del compito.
Alta libertà (istruzioni testuali):
Usa quando:
Esempio:
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventionsMedia libertà (pseudocodice o script con parametri):
Usa quando:
Esempio:
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```Bassa libertà (script specifici, pochi o nessun parametro):
Usa quando:
Esempio:
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.Analogia: Pensa a Claude come a un robot che esplora un percorso:
Le Skill agiscono come aggiunte ai modelli, quindi l'efficacia dipende dal modello sottostante. Testa la tua Skill con tutti i modelli con cui intendi utilizzarla.
Considerazioni di test per modello:
Ciò che funziona perfettamente per Opus potrebbe richiedere più dettagli per Haiku. Se prevedi di utilizzare la tua Skill su più modelli, punta a istruzioni che funzionino bene con tutti.
Frontmatter YAML: Il frontmatter di SKILL.md richiede due campi:
name:
description:
Per i dettagli completi sulla struttura delle Skill, consulta la panoramica delle Skill.
Usa pattern di denominazione coerenti per rendere le Skill più facili da referenziare e discutere. Considera l'uso della forma al gerundio (verbo + -ing) per i nomi delle Skill, poiché descrive chiaramente l'attività o la capacità che la Skill fornisce.
Ricorda che il campo name deve usare solo lettere minuscole, numeri e trattini.
Buoni esempi di denominazione (forma al gerundio):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentationAlternative accettabili:
pdf-processing, spreadsheet-analysisprocess-pdfs, analyze-spreadsheetsEvita:
helper, utils, toolsdocuments, data, filesanthropic-helper, claude-toolsUna denominazione coerente rende più facile:
Il campo description consente l'individuazione della Skill e dovrebbe includere sia cosa fa la Skill sia quando usarla.
Scrivi sempre in terza persona. La descrizione viene iniettata nel prompt di sistema, e un punto di vista incoerente può causare problemi di individuazione.
Sii specifico e includi termini chiave. Includi sia cosa fa la Skill sia trigger/contesti specifici per quando usarla.
Ogni Skill ha esattamente un campo description. La descrizione è critica per la selezione della Skill: Claude la usa per scegliere la Skill giusta tra potenzialmente più di 100 Skill disponibili. La tua descrizione deve fornire dettagli sufficienti affinché Claude sappia quando selezionare questa Skill, mentre il resto di SKILL.md fornisce i dettagli di implementazione.
Esempi efficaci:
Skill di elaborazione PDF:
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.Skill di analisi Excel:
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.Skill di supporto ai commit Git:
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.Evita descrizioni vaghe come queste:
description: Helps with documentsdescription: Processes datadescription: Does stuff with filesSKILL.md funge da panoramica che indirizza Claude verso materiali dettagliati quando necessario, come un indice in una guida di onboarding. Per una spiegazione di come funziona la divulgazione progressiva, consulta Come funzionano le Skill nella panoramica.
Indicazioni pratiche:
Una Skill di base inizia con un solo file SKILL.md contenente metadati e istruzioni:
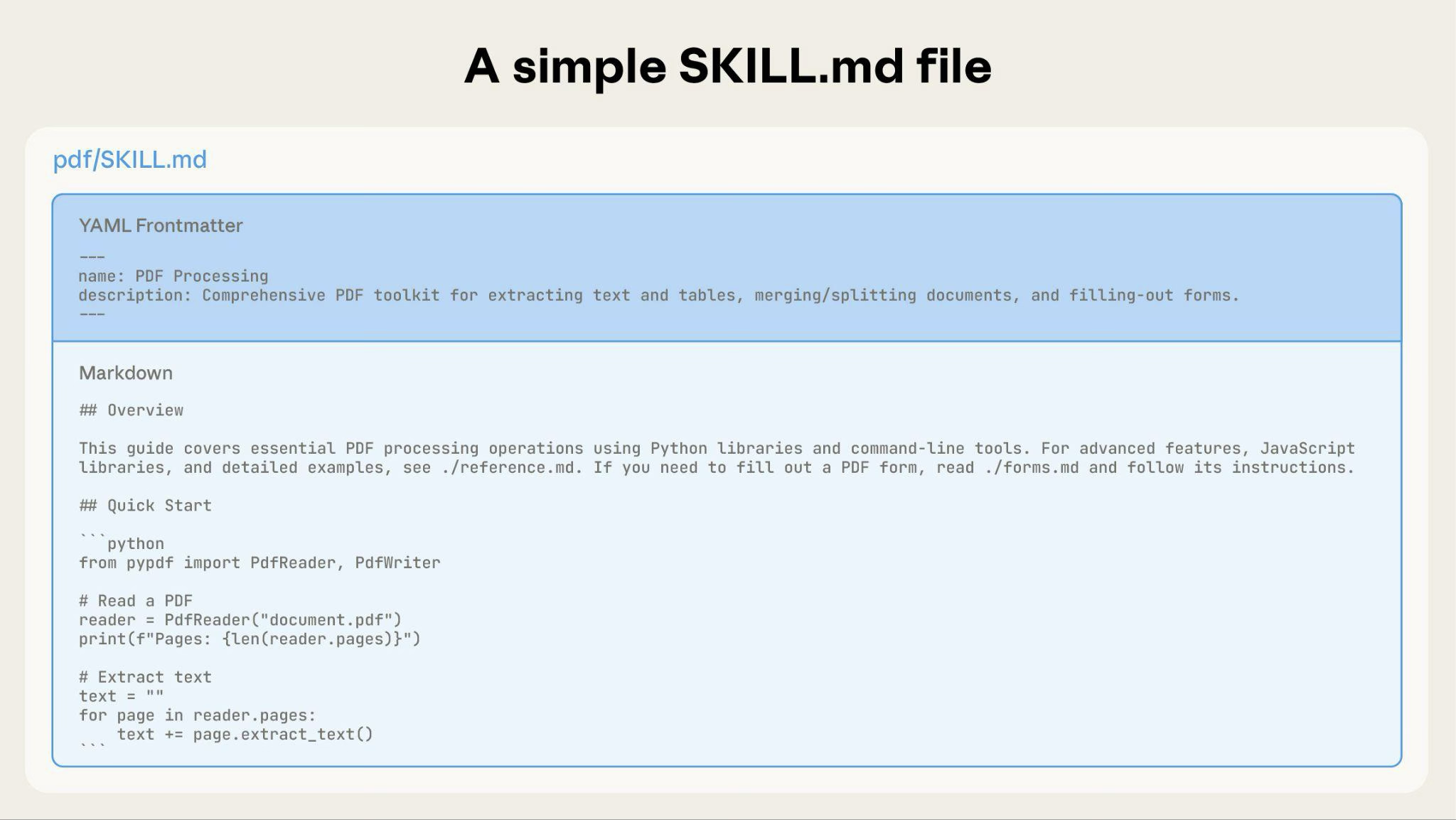
Man mano che la tua Skill cresce, puoi raggruppare contenuti aggiuntivi che Claude carica solo quando necessario:

La struttura completa della directory della Skill potrebbe apparire così:
pdf/
├── SKILL.md # Main instructions (loaded when triggered)
├── FORMS.md # Form-filling guide (loaded as needed)
├── reference.md # API reference (loaded as needed)
├── examples.md # Usage examples (loaded as needed)
└── scripts/
├── analyze_form.py # Utility script (executed, not loaded)
├── fill_form.py # Form filling script
└── validate.py # Validation script---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patternsClaude carica FORMS.md, REFERENCE.md o EXAMPLES.md solo quando necessario.
Per le Skill con più domini, organizza il contenuto per dominio per evitare di caricare contesto irrilevante. Quando un utente chiede informazioni sulle metriche di vendita, Claude deve leggere solo gli schemi relativi alle vendite, non i dati finanziari o di marketing. Questo mantiene basso l'uso dei token e il contesto focalizzato.
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)# BigQuery Data Analysis
## Available datasets
**Finance**: Revenue, ARR, billing → See [reference/finance.md](reference/finance.md)
**Sales**: Opportunities, pipeline, accounts → See [reference/sales.md](reference/sales.md)
**Product**: API usage, features, adoption → See [reference/product.md](reference/product.md)
**Marketing**: Campaigns, attribution, email → See [reference/marketing.md](reference/marketing.md)
## Quick search
Find specific metrics using grep:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```Mostra il contenuto di base, collega al contenuto avanzato:
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)Claude legge REDLINING.md o OOXML.md solo quando l'utente ha bisogno di quelle funzionalità.
Claude potrebbe leggere parzialmente i file quando sono referenziati da altri file referenziati. Quando incontra riferimenti annidati, Claude potrebbe usare comandi come head -100 per visualizzare in anteprima il contenuto invece di leggere interi file, ottenendo informazioni incomplete.
Mantieni i riferimenti a un livello di profondità da SKILL.md. Tutti i file di riferimento dovrebbero essere collegati direttamente da SKILL.md per garantire che Claude legga i file completi quando necessario.
Cattivo esempio: Troppo profondo:
# SKILL.md
See [advanced.md](advanced.md)...
# advanced.md
See [details.md](details.md)...
# details.md
Here's the actual information...Buon esempio: Un livello di profondità:
# SKILL.md
**Basic usage**: [instructions in SKILL.md]
**Advanced features**: See [advanced.md](advanced.md)
**API reference**: See [reference.md](reference.md)
**Examples**: See [examples.md](examples.md)Per i file di riferimento più lunghi di 100 righe, includi un indice all'inizio. Questo garantisce che Claude possa vedere l'intera portata delle informazioni disponibili anche quando visualizza in anteprima con letture parziali.
Esempio:
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
## Authentication and setup
...
## Core methods
...Claude può quindi leggere il file completo o saltare a sezioni specifiche secondo necessità.
Per i dettagli su come questa architettura basata su filesystem consente la divulgazione progressiva, consulta la sezione Ambiente di runtime nella sezione Avanzata di seguito.
Suddividi le operazioni complesse in passaggi chiari e sequenziali. Per workflow particolarmente complessi, fornisci una checklist che Claude possa copiare nella sua risposta e spuntare man mano che procede.
Esempio 1: Workflow di sintesi della ricerca (per Skill senza codice):
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.Questo esempio mostra come i workflow si applicano a compiti di analisi che non richiedono codice. Il pattern della checklist funziona per qualsiasi processo complesso e multi-step.
Esempio 2: Workflow di compilazione moduli PDF (per Skill con codice):
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
```
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
```
**Step 1: Analyze the form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create field mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify output**
Run: `python scripts/verify_output.py output.pdf`
If verification fails, return to Step 2.Passaggi chiari impediscono a Claude di saltare validazioni critiche. La checklist aiuta sia Claude che te a tracciare i progressi attraverso workflow multi-step.
Pattern comune: Esegui validatore → correggi errori → ripeti
Questo pattern migliora notevolmente la qualità dell'output.
Esempio 1: Conformità alla guida di stile (per Skill senza codice):
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the documentQuesto mostra il pattern del ciclo di validazione usando documenti di riferimento invece di script. Il "validatore" è STYLE_GUIDE.md, e Claude esegue il controllo leggendo e confrontando.
Esempio 2: Processo di modifica documenti (per Skill con codice):
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test the output documentIl ciclo di validazione rileva gli errori in anticipo.
Non includere informazioni che diventeranno obsolete:
Cattivo esempio: Sensibile al tempo (diventerà errato):
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.Buon esempio (usa la sezione "vecchi pattern"):
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>La sezione dei vecchi pattern fornisce contesto storico senza appesantire il contenuto principale.
Scegli un termine e usalo in tutta la Skill:
Bene - Coerente:
Male - Incoerente:
La coerenza aiuta Claude a comprendere e seguire le istruzioni.
Fornisci template per il formato di output. Adatta il livello di rigidità alle tue esigenze.
Per requisiti rigidi (come risposte API o formati di dati):
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```Per indicazioni flessibili (quando l'adattamento è utile):
## Report structure
Here is a sensible default format, but use your best judgment based on the analysis:
```markdown
# [Analysis Title]
## Executive summary
[Overview]
## Key findings
[Adapt sections based on what you discover]
## Recommendations
[Tailor to the specific context]
```
Adjust sections as needed for the specific analysis type.Per le Skill in cui la qualità dell'output dipende dalla visione di esempi, fornisci coppie input/output proprio come nel prompting normale:
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
**Example 3:**
Input: Updated dependencies and refactored error handling
Output:
```
chore: update dependencies and refactor error handling
- Upgrade lodash to 4.17.21
- Standardize error response format across endpoints
```
Follow this style: type(scope): brief description, then detailed explanation.Gli esempi aiutano Claude a comprendere lo stile e il livello di dettaglio desiderati più chiaramente delle sole descrizioni.
Guida Claude attraverso i punti decisionali:
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when completeSe i workflow diventano grandi o complicati con molti passaggi, considera di spostarli in file separati e indica a Claude di leggere il file appropriato in base al compito da svolgere.
Crea le valutazioni PRIMA di scrivere documentazione estesa. Questo garantisce che la tua Skill risolva problemi reali invece di documentare problemi immaginari.
Sviluppo guidato dalle valutazioni:
Questo approccio garantisce che tu stia risolvendo problemi reali invece di anticipare requisiti che potrebbero non materializzarsi mai.
Struttura della valutazione:
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF file and save it to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file using an appropriate PDF processing library or command-line tool",
"Extracts text content from all pages in the document without missing any pages",
"Saves the extracted text to a file named output.txt in a clear, readable format"
]
}Questo esempio dimostra una valutazione basata sui dati con una semplice rubrica di test. Attualmente non esiste un modo integrato per eseguire queste valutazioni. Gli utenti possono creare il proprio sistema di valutazione. Le valutazioni sono la tua fonte di verità per misurare l'efficacia della Skill.
Il processo di sviluppo delle Skill più efficace coinvolge Claude stesso. Lavora con un'istanza di Claude ("Claude A") per creare una Skill che viene utilizzata da altre istanze ("Claude B"). Claude A ti aiuta a progettare e perfezionare le istruzioni, mentre Claude B le testa in compiti reali. Questo funziona perché i modelli Claude comprendono sia come scrivere istruzioni efficaci per agenti sia quali informazioni servono agli agenti.
Creare una nuova Skill:
Completa un compito senza una Skill: Lavora su un problema con Claude A usando il prompting normale. Mentre lavori, fornirai naturalmente contesto, spiegherai preferenze e condividerai conoscenze procedurali. Nota quali informazioni fornisci ripetutamente.
Identifica il pattern riutilizzabile: Dopo aver completato il compito, identifica quale contesto hai fornito che sarebbe utile per compiti futuri simili.
Esempio: Se hai lavorato su un'analisi BigQuery, potresti aver fornito nomi di tabelle, definizioni di campi, regole di filtraggio (come "escludi sempre gli account di test") e pattern di query comuni.
Chiedi a Claude A di creare una Skill: "Crea una Skill che catturi questo pattern di analisi BigQuery che abbiamo appena usato. Includi gli schemi delle tabelle, le convenzioni di denominazione e la regola sul filtraggio degli account di test."
I modelli Claude comprendono nativamente il formato e la struttura delle Skill. Non hai bisogno di prompt di sistema speciali o di una Skill "per scrivere Skill" per far sì che Claude ti aiuti a creare Skill. Chiedi semplicemente a Claude di creare una Skill e genererà contenuto SKILL.md correttamente strutturato con frontmatter e corpo appropriati.
Rivedi per concisione: Verifica che Claude A non abbia aggiunto spiegazioni non necessarie. Chiedi: "Rimuovi la spiegazione su cosa significa win rate - Claude lo sa già."
Migliora l'architettura delle informazioni: Chiedi a Claude A di organizzare il contenuto in modo più efficace. Ad esempio: "Organizza questo in modo che lo schema della tabella sia in un file di riferimento separato. Potremmo aggiungere altre tabelle in seguito."
Testa su compiti simili: Usa la Skill con Claude B (una nuova istanza con la Skill caricata) su casi d'uso correlati. Osserva se Claude B trova le informazioni giuste, applica le regole correttamente e gestisce il compito con successo.
Itera in base all'osservazione: Se Claude B ha difficoltà o perde qualcosa, torna da Claude A con dettagli specifici: "Quando Claude ha usato questa Skill, ha dimenticato di filtrare per data per il Q4. Dovremmo aggiungere una sezione sui pattern di filtraggio per data?"
Iterare su Skill esistenti:
Lo stesso pattern gerarchico continua quando si migliorano le Skill. Alterni tra:
Usa la Skill in workflow reali: Dai a Claude B (con la Skill caricata) compiti effettivi, non scenari di test
Osserva il comportamento di Claude B: Nota dove ha difficoltà, ha successo o fa scelte inaspettate
Esempio di osservazione: "Quando ho chiesto a Claude B un report di vendita regionale, ha scritto la query ma ha dimenticato di filtrare gli account di test, anche se la Skill menziona questa regola."
Torna da Claude A per miglioramenti: Condividi l'attuale SKILL.md e descrivi cosa hai osservato. Chiedi: "Ho notato che Claude B ha dimenticato di filtrare gli account di test quando ho chiesto un report regionale. La Skill menziona il filtraggio, ma forse non è abbastanza evidente?"
Rivedi i suggerimenti di Claude A: Claude A potrebbe suggerire di riorganizzare per rendere le regole più evidenti, usare un linguaggio più forte come "DEVE filtrare" invece di "filtra sempre", o ristrutturare la sezione del workflow.
Applica e testa le modifiche: Aggiorna la Skill con i perfezionamenti di Claude A, poi testa di nuovo con Claude B su richieste simili
Ripeti in base all'uso: Continua questo ciclo osserva-perfeziona-testa man mano che incontri nuovi scenari. Ogni iterazione migliora la Skill in base al comportamento reale dell'agente, non a supposizioni.
Raccogliere feedback dal team:
Perché questo approccio funziona: Claude A comprende le esigenze degli agenti, tu fornisci competenza di dominio, Claude B rivela le lacune attraverso l'uso reale, e il perfezionamento iterativo migliora le Skill in base al comportamento osservato invece che a supposizioni.
Mentre iteri sulle Skill, presta attenzione a come Claude le usa effettivamente nella pratica. Osserva:
Itera in base a queste osservazioni invece che a supposizioni. Il 'name' e la 'description' nei metadati della tua Skill sono particolarmente critici. Claude li usa quando decide se attivare la Skill in risposta al compito corrente. Assicurati che descrivano chiaramente cosa fa la Skill e quando dovrebbe essere usata.
Usa sempre barre oblique nei percorsi dei file, anche su Windows:
scripts/helper.py, reference/guide.mdscripts\helper.py, reference\guide.mdI percorsi in stile Unix funzionano su tutte le piattaforme, mentre i percorsi in stile Windows causano errori sui sistemi Unix.
Non presentare più approcci a meno che non sia necessario:
**Bad example: Too many choices** (confusing):
"You can use pypdf, or pdfplumber, or PyMuPDF, or pdf2image, or..."
**Good example: Provide a default** (with escape hatch):
"Use pdfplumber for text extraction:
```python
import pdfplumber
```
For scanned PDFs requiring OCR, use pdf2image with pytesseract instead."Le sezioni seguenti si concentrano sulle Skill che includono script eseguibili. Se la tua Skill usa solo istruzioni markdown, passa a Checklist per Skill efficaci.
Quando scrivi script per le Skill, gestisci le condizioni di errore invece di delegarle a Claude.
Buon esempio: Gestisci gli errori esplicitamente:
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# Crea il file con contenuto predefinito invece di fallire
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# Fornisci un'alternativa invece di fallire
print(f"Cannot access {path}, using default")
return ""Cattivo esempio: Delega a Claude:
def process_file(path):
# Fallisci semplicemente e lascia che Claude capisca da solo
return open(path).read()Anche i parametri di configurazione dovrebbero essere giustificati e documentati per evitare "costanti voodoo" (legge di Ousterhout). Se non conosci il valore giusto, come lo determinerà Claude?
Buon esempio: Auto-documentante:
# Le richieste HTTP si completano tipicamente entro 30 secondi
# Un timeout più lungo tiene conto delle connessioni lente
REQUEST_TIMEOUT = 30
# Tre tentativi bilanciano affidabilità e velocità
# La maggior parte dei fallimenti intermittenti si risolve al secondo tentativo
MAX_RETRIES = 3Cattivo esempio: Numeri magici:
TIMEOUT = 47 # Why 47?
RETRIES = 5 # Why 5?Anche se Claude potrebbe scrivere uno script, gli script predefiniti offrono vantaggi:
Vantaggi degli script di utilità:

Il diagramma sopra mostra come gli script eseguibili funzionano insieme ai file di istruzioni. Il file di istruzioni (forms.md) fa riferimento allo script, e Claude può eseguirlo senza caricare il suo contenuto nel contesto.
Distinzione importante: Chiarisci nelle tue istruzioni se Claude deve:
analyze_form.py per estrarre i campi"analyze_form.py per l'algoritmo di estrazione dei campi"Per la maggior parte degli script di utilità, l'esecuzione è preferita perché è più affidabile ed efficiente. Consulta la sezione Ambiente di runtime di seguito per i dettagli su come funziona l'esecuzione degli script.
Esempio:
## Utility scripts
**analyze_form.py**: Extract all form fields from PDF
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
Output format:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**: Check for overlapping bounding boxes
```bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
```
**fill_form.py**: Apply field values to PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```Quando gli input possono essere renderizzati come immagini, fai in modo che Claude li analizzi:
## Form layout analysis
1. Convert PDF to images:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. Analyze each page image to identify form fields
3. Claude can see field locations and types visuallyIn questo esempio, dovresti scrivere lo script pdf_to_images.py.
Le capacità visive di Claude aiutano a comprendere layout e strutture.
Quando Claude esegue compiti complessi e aperti, può commettere errori. Il pattern "pianifica-valida-esegui" rileva gli errori in anticipo facendo prima creare a Claude un piano in un formato strutturato, poi validando quel piano con uno script prima di eseguirlo.
Esempio: Immagina di chiedere a Claude di aggiornare 50 campi di un modulo in un PDF basandosi su un foglio di calcolo. Senza validazione, Claude potrebbe fare riferimento a campi inesistenti, creare valori in conflitto, perdere campi obbligatori o applicare aggiornamenti in modo errato.
Soluzione: Usa il pattern di workflow mostrato sopra (compilazione moduli PDF), ma aggiungi un file intermedio changes.json che viene validato prima di applicare le modifiche. Il workflow diventa: analizza → crea file del piano → valida il piano → esegui → verifica.
Perché questo pattern funziona:
Quando usarlo: Operazioni batch, modifiche distruttive, regole di validazione complesse, operazioni ad alto rischio.
Suggerimento di implementazione: Rendi gli script di validazione dettagliati con messaggi di errore specifici come "Campo 'signature_date' non trovato. Campi disponibili: customer_name, order_total, signature_date_signed" per aiutare Claude a risolvere i problemi.
Le Skill vengono eseguite nell'ambiente di esecuzione del codice con limitazioni specifiche per piattaforma:
Elenca i pacchetti richiesti nel tuo SKILL.md e verifica che siano disponibili nella documentazione dello strumento di esecuzione del codice.
Le Skill vengono eseguite in un ambiente di esecuzione del codice con accesso al filesystem, comandi bash e capacità di esecuzione del codice. Per la spiegazione concettuale di questa architettura, consulta L'architettura delle Skill nella panoramica.
Come questo influenza il tuo authoring:
Come Claude accede alle Skill:
reference/guide.md), non barre rovesciateform_validation_rules.md, non doc2.mdreference/finance.md, reference/sales.mddocs/file1.md, docs/file2.mdvalidate_form.py invece di chiedere a Claude di generare codice di validazioneanalyze_form.py per estrarre i campi" (esegui)analyze_form.py per l'algoritmo di estrazione" (leggi come riferimento)Esempio:
bigquery-skill/
├── SKILL.md (overview, points to reference files)
└── reference/
├── finance.md (revenue metrics)
├── sales.md (pipeline data)
└── product.md (usage analytics)Quando l'utente chiede informazioni sui ricavi, Claude legge SKILL.md, vede il riferimento a reference/finance.md e invoca bash per leggere solo quel file. I file sales.md e product.md rimangono sul filesystem, consumando zero token di contesto finché non sono necessari. Questo modello basato su filesystem è ciò che consente la divulgazione progressiva. Claude può navigare e caricare selettivamente esattamente ciò che ogni compito richiede.
Per i dettagli completi sull'architettura tecnica, consulta Come funzionano le Skill nella panoramica delle Skill.
Se la tua Skill usa strumenti MCP (Model Context Protocol), usa sempre nomi di strumenti completamente qualificati per evitare errori "strumento non trovato".
Formato: ServerName:tool_name
Esempio:
Use the BigQuery:bigquery_schema tool to retrieve table schemas.
Use the GitHub:create_issue tool to create issues.Dove:
BigQuery e GitHub sono nomi di server MCPbigquery_schema e create_issue sono i nomi degli strumenti all'interno di quei serverSenza il prefisso del server, Claude potrebbe non riuscire a localizzare lo strumento, specialmente quando sono disponibili più server MCP.
Non presumere che i pacchetti siano disponibili:
**Bad example: Assumes installation**:
"Use the pdf library to process the file."
**Good example: Explicit about dependencies**:
"Install required package: `pip install pypdf`
Then use it:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"Il frontmatter di SKILL.md richiede i campi name e description con regole di validazione specifiche:
name: Massimo 64 caratteri, solo lettere minuscole/numeri/trattini, nessun tag XML, nessuna parola riservatadescription: Massimo 1024 caratteri, non vuoto, nessun tag XMLConsulta la panoramica delle Skill per i dettagli completi sulla struttura.
Mantieni il corpo di SKILL.md sotto le 500 righe per prestazioni ottimali. Se il tuo contenuto supera questo limite, dividilo in file separati usando i pattern di divulgazione progressiva descritti in precedenza. Per i dettagli architetturali, consulta la panoramica delle Skill.
Prima di condividere una Skill, verifica:
Crea la tua prima Skill
Crea e gestisci le Skill in Claude Code
Carica e usa le Skill in modo programmatico
Was this page helpful?