Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Was this page helpful?
Após definir seus critérios de sucesso, o próximo passo é projetar avaliações para medir o desempenho do LLM em relação a esses critérios. Esta é uma parte vital do ciclo de engenharia de prompts.
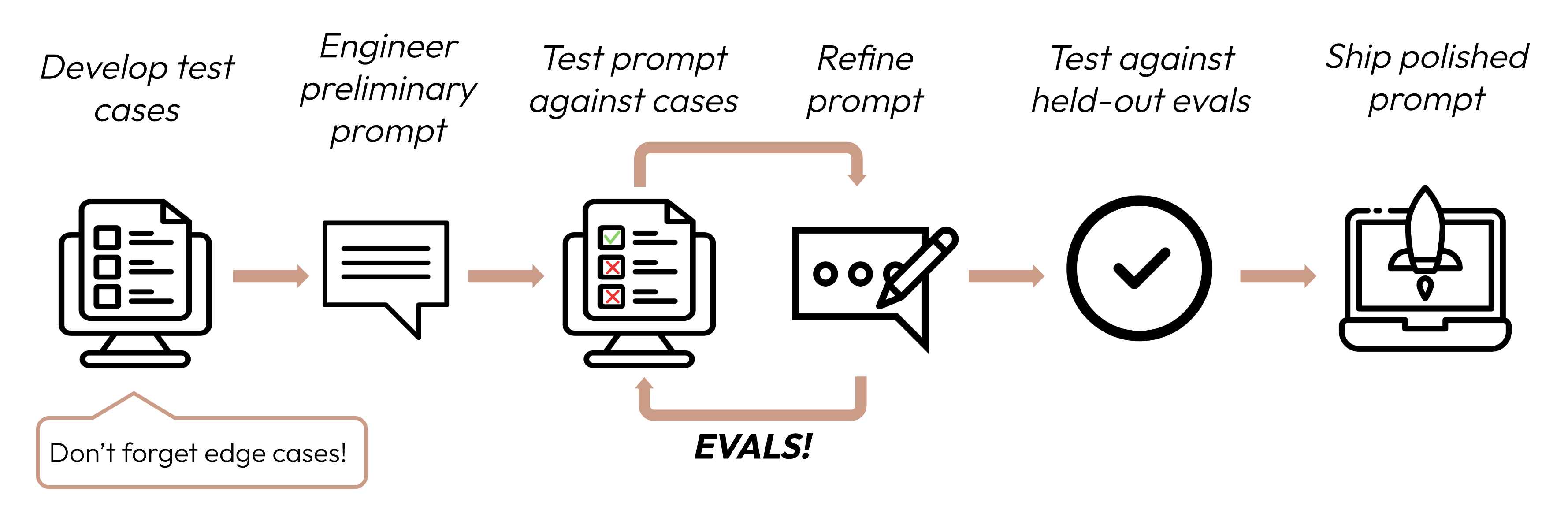
Este guia se concentra em como desenvolver seus casos de teste.
Ao decidir qual método usar para classificar evals, escolha o método mais rápido, mais confiável e mais escalável:
Classificação baseada em código: Mais rápida e confiável, extremamente escalável, mas também carece de nuances para julgamentos mais complexos que requerem menos rigidez baseada em regras.
output == golden_answerkey_phrase in outputClassificação humana: Mais flexível e de alta qualidade, mas lenta e cara. Evite se possível.
Classificação baseada em LLM: Rápida e flexível, escalável e adequada para julgamentos complexos. Teste para garantir confiabilidade primeiro e depois dimensione.
Mais exemplos de código de evals classificadas por humanos, código e LLM.