Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Boas Skills são concisas, bem estruturadas e testadas com uso real. Este guia fornece decisões práticas de criação para ajudar você a escrever Skills que o Claude possa descobrir e usar de forma eficaz.
Para obter informações conceituais sobre como as Skills funcionam, consulte a visão geral de Skills.
A context window (janela de contexto) é um bem público. Sua Skill compartilha a janela de contexto com tudo o mais que o Claude precisa saber, incluindo:
Nem todo token na sua Skill tem um custo imediato. Na inicialização, apenas os metadados (nome e descrição) de todas as Skills são pré-carregados. O Claude lê o SKILL.md apenas quando a Skill se torna relevante e lê arquivos adicionais apenas conforme necessário. No entanto, ser conciso no SKILL.md ainda é importante: uma vez que o Claude o carrega, cada token compete com o histórico da conversa e outros contextos.
Premissa padrão: o Claude já é muito inteligente
Adicione apenas contexto que o Claude ainda não tenha. Questione cada informação:
Bom exemplo: Conciso (aproximadamente 50 tokens):
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```Mau exemplo: Muito verboso (aproximadamente 150 tokens):
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but
pdfplumber is recommended because it's easy to use and handles most cases well.
First, you'll need to install it using pip. Then you can use the code below...A versão concisa assume que o Claude sabe o que são PDFs e como bibliotecas funcionam.
Ajuste o nível de especificidade à fragilidade e variabilidade da tarefa.
Alta liberdade (instruções baseadas em texto):
Use quando:
Exemplo:
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventionsLiberdade média (pseudocódigo ou scripts com parâmetros):
Use quando:
Exemplo:
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```Baixa liberdade (scripts específicos, poucos ou nenhum parâmetro):
Use quando:
Exemplo:
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.Analogia: Pense no Claude como um robô explorando um caminho:
As Skills atuam como adições aos modelos, então a eficácia depende do modelo subjacente. Teste sua Skill com todos os modelos com os quais você planeja usá-la.
Considerações de teste por modelo:
O que funciona perfeitamente para o Opus pode precisar de mais detalhes para o Haiku. Se você planeja usar sua Skill em vários modelos, busque instruções que funcionem bem com todos eles.
Frontmatter YAML: O frontmatter do SKILL.md requer dois campos:
name:
description:
Para detalhes completos sobre a estrutura da Skill, consulte a visão geral de Skills.
Use padrões de nomenclatura consistentes para facilitar a referência e discussão das Skills. Considere usar a forma de gerúndio (verbo + -ing) para nomes de Skills, pois isso descreve claramente a atividade ou capacidade que a Skill fornece.
Lembre-se de que o campo name deve usar apenas letras minúsculas, números e hífens.
Bons exemplos de nomenclatura (forma de gerúndio):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentationAlternativas aceitáveis:
pdf-processing, spreadsheet-analysisprocess-pdfs, analyze-spreadsheetsEvite:
helper, utils, toolsdocuments, data, filesanthropic-helper, claude-toolsNomenclatura consistente facilita:
O campo description permite a descoberta da Skill e deve incluir tanto o que a Skill faz quanto quando usá-la.
Sempre escreva em terceira pessoa. A descrição é injetada no prompt do sistema, e um ponto de vista inconsistente pode causar problemas de descoberta.
Seja específico e inclua termos-chave. Inclua tanto o que a Skill faz quanto gatilhos/contextos específicos para quando usá-la.
Cada Skill tem exatamente um campo de descrição. A descrição é crítica para a seleção da Skill: o Claude a usa para escolher a Skill certa entre potencialmente mais de 100 Skills disponíveis. Sua descrição deve fornecer detalhes suficientes para que o Claude saiba quando selecionar esta Skill, enquanto o restante do SKILL.md fornece os detalhes de implementação.
Exemplos eficazes:
Skill de Processamento de PDF:
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.Skill de Análise de Excel:
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.Skill de Auxiliar de Commit do Git:
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.Evite descrições vagas como estas:
description: Helps with documentsdescription: Processes datadescription: Does stuff with filesO SKILL.md serve como uma visão geral que direciona o Claude para materiais detalhados conforme necessário, como um sumário em um guia de integração. Para uma explicação de como a divulgação progressiva funciona, consulte Como as Skills funcionam na visão geral.
Orientação prática:
Uma Skill básica começa com apenas um arquivo SKILL.md contendo metadados e instruções:
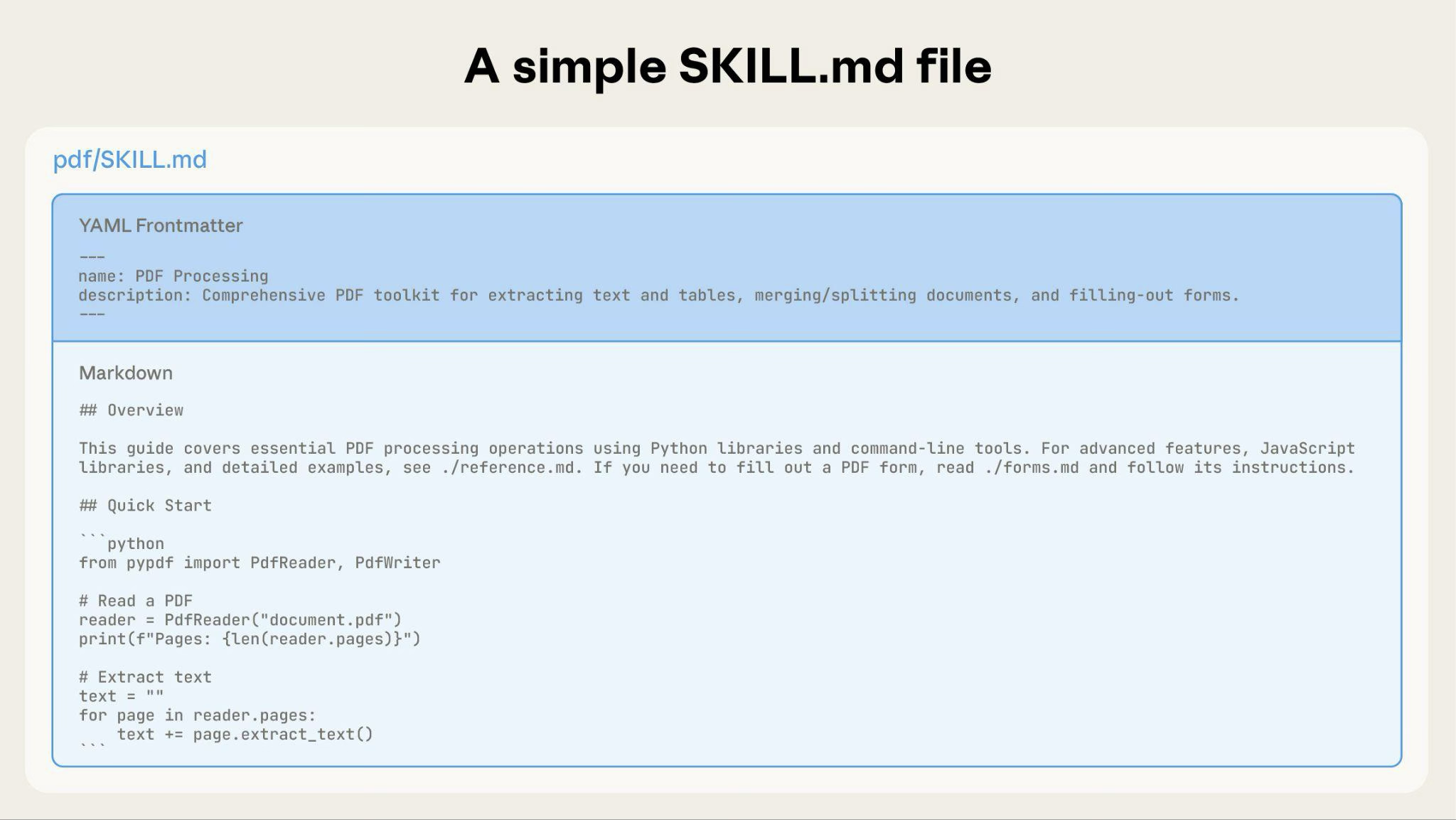
À medida que sua Skill cresce, você pode agrupar conteúdo adicional que o Claude carrega apenas quando necessário:

A estrutura completa do diretório da Skill pode ser assim:
pdf/
├── SKILL.md # Main instructions (loaded when triggered)
├── FORMS.md # Form-filling guide (loaded as needed)
├── reference.md # API reference (loaded as needed)
├── examples.md # Usage examples (loaded as needed)
└── scripts/
├── analyze_form.py # Utility script (executed, not loaded)
├── fill_form.py # Form filling script
└── validate.py # Validation script---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patternsO Claude carrega FORMS.md, REFERENCE.md ou EXAMPLES.md apenas quando necessário.
Para Skills com múltiplos domínios, organize o conteúdo por domínio para evitar carregar contexto irrelevante. Quando um usuário pergunta sobre métricas de vendas, o Claude só precisa ler esquemas relacionados a vendas, não dados de finanças ou marketing. Isso mantém o uso de tokens baixo e o contexto focado.
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)# BigQuery Data Analysis
## Available datasets
**Finance**: Revenue, ARR, billing → See [reference/finance.md](reference/finance.md)
**Sales**: Opportunities, pipeline, accounts → See [reference/sales.md](reference/sales.md)
**Product**: API usage, features, adoption → See [reference/product.md](reference/product.md)
**Marketing**: Campaigns, attribution, email → See [reference/marketing.md](reference/marketing.md)
## Quick search
Find specific metrics using grep:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```Mostre conteúdo básico, vincule a conteúdo avançado:
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)O Claude lê REDLINING.md ou OOXML.md apenas quando o usuário precisa desses recursos.
O Claude pode ler arquivos parcialmente quando eles são referenciados a partir de outros arquivos referenciados. Ao encontrar referências aninhadas, o Claude pode usar comandos como head -100 para visualizar o conteúdo em vez de ler arquivos inteiros, resultando em informações incompletas.
Mantenha as referências a um nível de profundidade a partir do SKILL.md. Todos os arquivos de referência devem ser vinculados diretamente do SKILL.md para garantir que o Claude leia arquivos completos quando necessário.
Mau exemplo: Muito profundo:
# SKILL.md
See [advanced.md](advanced.md)...
# advanced.md
See [details.md](details.md)...
# details.md
Here's the actual information...Bom exemplo: Um nível de profundidade:
# SKILL.md
**Basic usage**: [instructions in SKILL.md]
**Advanced features**: See [advanced.md](advanced.md)
**API reference**: See [reference.md](reference.md)
**Examples**: See [examples.md](examples.md)Para arquivos de referência com mais de 100 linhas, inclua um sumário no topo. Isso garante que o Claude possa ver o escopo completo das informações disponíveis mesmo ao visualizar com leituras parciais.
Exemplo:
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
## Authentication and setup
...
## Core methods
...O Claude pode então ler o arquivo completo ou pular para seções específicas conforme necessário.
Para detalhes sobre como essa arquitetura baseada em sistema de arquivos permite a divulgação progressiva, consulte a seção Ambiente de execução na seção Avançado abaixo.
Divida operações complexas em etapas claras e sequenciais. Para fluxos de trabalho particularmente complexos, forneça uma lista de verificação que o Claude possa copiar em sua resposta e marcar conforme avança.
Exemplo 1: Fluxo de trabalho de síntese de pesquisa (para Skills sem código):
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.Este exemplo mostra como fluxos de trabalho se aplicam a tarefas de análise que não requerem código. O padrão de lista de verificação funciona para qualquer processo complexo de múltiplas etapas.
Exemplo 2: Fluxo de trabalho de preenchimento de formulário PDF (para Skills com código):
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
```
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
```
**Step 1: Analyze the form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create field mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify output**
Run: `python scripts/verify_output.py output.pdf`
If verification fails, return to Step 2.Etapas claras evitam que o Claude pule validações críticas. A lista de verificação ajuda tanto o Claude quanto você a acompanhar o progresso em fluxos de trabalho de múltiplas etapas.
Padrão comum: Executar validador → corrigir erros → repetir
Esse padrão melhora muito a qualidade da saída.
Exemplo 1: Conformidade com guia de estilo (para Skills sem código):
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the documentIsso mostra o padrão de ciclo de validação usando documentos de referência em vez de scripts. O "validador" é o STYLE_GUIDE.md, e o Claude realiza a verificação lendo e comparando.
Exemplo 2: Processo de edição de documentos (para Skills com código):
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test the output documentO ciclo de validação detecta erros precocemente.
Não inclua informações que ficarão desatualizadas:
Mau exemplo: Sensível ao tempo (ficará incorreto):
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.Bom exemplo (use a seção "padrões antigos"):
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>A seção de padrões antigos fornece contexto histórico sem poluir o conteúdo principal.
Escolha um termo e use-o em toda a Skill:
Bom - Consistente:
Ruim - Inconsistente:
A consistência ajuda o Claude a entender e seguir instruções.
Forneça templates para o formato de saída. Ajuste o nível de rigor às suas necessidades.
Para requisitos rigorosos (como respostas de API ou formatos de dados):
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```Para orientação flexível (quando a adaptação é útil):
## Report structure
Here is a sensible default format, but use your best judgment based on the analysis:
```markdown
# [Analysis Title]
## Executive summary
[Overview]
## Key findings
[Adapt sections based on what you discover]
## Recommendations
[Tailor to the specific context]
```
Adjust sections as needed for the specific analysis type.Para Skills em que a qualidade da saída depende de ver exemplos, forneça pares de entrada/saída assim como em prompts regulares:
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
**Example 3:**
Input: Updated dependencies and refactored error handling
Output:
```
chore: update dependencies and refactor error handling
- Upgrade lodash to 4.17.21
- Standardize error response format across endpoints
```
Follow this style: type(scope): brief description, then detailed explanation.Exemplos ajudam o Claude a entender o estilo e nível de detalhe desejados com mais clareza do que apenas descrições.
Guie o Claude através de pontos de decisão:
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when completeSe os fluxos de trabalho se tornarem grandes ou complicados com muitas etapas, considere movê-los para arquivos separados e instrua o Claude a ler o arquivo apropriado com base na tarefa em questão.
Crie avaliações ANTES de escrever documentação extensa. Isso garante que sua Skill resolva problemas reais em vez de documentar problemas imaginados.
Desenvolvimento orientado por avaliação:
Essa abordagem garante que você esteja resolvendo problemas reais em vez de antecipar requisitos que podem nunca se materializar.
Estrutura de avaliação:
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF file and save it to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file using an appropriate PDF processing library or command-line tool",
"Extracts text content from all pages in the document without missing any pages",
"Saves the extracted text to a file named output.txt in a clear, readable format"
]
}Este exemplo demonstra uma avaliação orientada por dados com uma rubrica de teste simples. Atualmente não há uma forma integrada de executar essas avaliações. Os usuários podem criar seu próprio sistema de avaliação. As avaliações são sua fonte de verdade para medir a eficácia da Skill.
O processo de desenvolvimento de Skills mais eficaz envolve o próprio Claude. Trabalhe com uma instância do Claude ("Claude A") para criar uma Skill que é usada por outras instâncias ("Claude B"). O Claude A ajuda você a projetar e refinar instruções, enquanto o Claude B as testa em tarefas reais. Isso funciona porque os modelos Claude entendem tanto como escrever instruções eficazes para agentes quanto quais informações os agentes precisam.
Criando uma nova Skill:
Complete uma tarefa sem uma Skill: Trabalhe em um problema com o Claude A usando prompts normais. Conforme você trabalha, naturalmente fornecerá contexto, explicará preferências e compartilhará conhecimento procedimental. Observe quais informações você fornece repetidamente.
Identifique o padrão reutilizável: Após completar a tarefa, identifique qual contexto você forneceu que seria útil para tarefas futuras semelhantes.
Exemplo: Se você trabalhou em uma análise do BigQuery, pode ter fornecido nomes de tabelas, definições de campos, regras de filtragem (como "sempre excluir contas de teste") e padrões de consulta comuns.
Peça ao Claude A para criar uma Skill: "Crie uma Skill que capture esse padrão de análise do BigQuery que acabamos de usar. Inclua os esquemas de tabela, convenções de nomenclatura e a regra sobre filtrar contas de teste."
Os modelos Claude entendem o formato e a estrutura de Skills nativamente. Você não precisa de prompts do sistema especiais ou de uma Skill de "escrever skills" para fazer o Claude ajudar a criar Skills. Simplesmente peça ao Claude para criar uma Skill e ele gera conteúdo SKILL.md adequadamente estruturado com frontmatter e corpo apropriados.
Revise quanto à concisão: Verifique se o Claude A não adicionou explicações desnecessárias. Peça: "Remova a explicação sobre o que significa taxa de vitória - o Claude já sabe disso."
Melhore a arquitetura da informação: Peça ao Claude A para organizar o conteúdo de forma mais eficaz. Por exemplo: "Organize isso de forma que o esquema da tabela fique em um arquivo de referência separado. Podemos adicionar mais tabelas depois."
Teste em tarefas semelhantes: Use a Skill com o Claude B (uma instância nova com a Skill carregada) em casos de uso relacionados. Observe se o Claude B encontra as informações certas, aplica regras corretamente e lida com a tarefa com sucesso.
Itere com base na observação: Se o Claude B tiver dificuldades ou perder algo, retorne ao Claude A com detalhes específicos: "Quando o Claude usou esta Skill, ele esqueceu de filtrar por data para o Q4. Devemos adicionar uma seção sobre padrões de filtragem de data?"
Iterando em Skills existentes:
O mesmo padrão hierárquico continua ao melhorar Skills. Você alterna entre:
Use a Skill em fluxos de trabalho reais: Dê ao Claude B (com a Skill carregada) tarefas reais, não cenários de teste
Observe o comportamento do Claude B: Anote onde ele tem dificuldades, tem sucesso ou faz escolhas inesperadas
Exemplo de observação: "Quando pedi ao Claude B um relatório de vendas regional, ele escreveu a consulta mas esqueceu de filtrar contas de teste, mesmo que a Skill mencione essa regra."
Retorne ao Claude A para melhorias: Compartilhe o SKILL.md atual e descreva o que você observou. Pergunte: "Notei que o Claude B esqueceu de filtrar contas de teste quando pedi um relatório regional. A Skill menciona filtragem, mas talvez não esteja proeminente o suficiente?"
Revise as sugestões do Claude A: O Claude A pode sugerir reorganizar para tornar as regras mais proeminentes, usar linguagem mais forte como "DEVE filtrar" em vez de "sempre filtrar", ou reestruturar a seção de fluxo de trabalho.
Aplique e teste as mudanças: Atualize a Skill com os refinamentos do Claude A, depois teste novamente com o Claude B em solicitações semelhantes
Repita com base no uso: Continue esse ciclo de observar-refinar-testar conforme você encontra novos cenários. Cada iteração melhora a Skill com base no comportamento real do agente, não em suposições.
Coletando feedback da equipe:
Por que essa abordagem funciona: O Claude A entende as necessidades do agente, você fornece expertise de domínio, o Claude B revela lacunas através do uso real, e o refinamento iterativo melhora as Skills com base no comportamento observado em vez de suposições.
Conforme você itera nas Skills, preste atenção em como o Claude realmente as usa na prática. Observe:
Itere com base nessas observações em vez de suposições. O 'name' e a 'description' nos metadados da sua Skill são particularmente críticos. O Claude os usa ao decidir se deve acionar a Skill em resposta à tarefa atual. Certifique-se de que eles descrevam claramente o que a Skill faz e quando ela deve ser usada.
Sempre use barras normais em caminhos de arquivo, mesmo no Windows:
scripts/helper.py, reference/guide.mdscripts\helper.py, reference\guide.mdCaminhos no estilo Unix funcionam em todas as plataformas, enquanto caminhos no estilo Windows causam erros em sistemas Unix.
Não apresente múltiplas abordagens a menos que seja necessário:
**Bad example: Too many choices** (confusing):
"You can use pypdf, or pdfplumber, or PyMuPDF, or pdf2image, or..."
**Good example: Provide a default** (with escape hatch):
"Use pdfplumber for text extraction:
```python
import pdfplumber
```
For scanned PDFs requiring OCR, use pdf2image with pytesseract instead."As seções abaixo focam em Skills que incluem scripts executáveis. Se sua Skill usa apenas instruções em markdown, pule para Lista de verificação para Skills eficazes.
Ao escrever scripts para Skills, trate condições de erro em vez de delegar ao Claude.
Bom exemplo: Trate erros explicitamente:
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# Cria o arquivo com conteúdo padrão em vez de falhar
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# Fornece uma alternativa em vez de falhar
print(f"Cannot access {path}, using default")
return ""Mau exemplo: Delegar ao Claude:
def process_file(path):
# Apenas falhe e deixe o Claude descobrir
return open(path).read()Parâmetros de configuração também devem ser justificados e documentados para evitar "constantes vodu" (lei de Ousterhout). Se você não sabe o valor correto, como o Claude vai determiná-lo?
Bom exemplo: Autodocumentado:
# Requisições HTTP normalmente são concluídas em até 30 segundos
# Um timeout maior acomoda conexões lentas
REQUEST_TIMEOUT = 30
# Três tentativas equilibram confiabilidade e velocidade
# A maioria das falhas intermitentes se resolve até a segunda tentativa
MAX_RETRIES = 3Mau exemplo: Números mágicos:
TIMEOUT = 47 # Why 47?
RETRIES = 5 # Why 5?Mesmo que o Claude pudesse escrever um script, scripts pré-prontos oferecem vantagens:
Benefícios de scripts utilitários:

O diagrama acima mostra como scripts executáveis funcionam junto com arquivos de instrução. O arquivo de instrução (forms.md) referencia o script, e o Claude pode executá-lo sem carregar seu conteúdo no contexto.
Distinção importante: Deixe claro em suas instruções se o Claude deve:
analyze_form.py para extrair campos"analyze_form.py para o algoritmo de extração de campos"Para a maioria dos scripts utilitários, a execução é preferida porque é mais confiável e eficiente. Consulte a seção Ambiente de execução abaixo para detalhes sobre como a execução de scripts funciona.
Exemplo:
## Utility scripts
**analyze_form.py**: Extract all form fields from PDF
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
Output format:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**: Check for overlapping bounding boxes
```bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
```
**fill_form.py**: Apply field values to PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```Quando as entradas podem ser renderizadas como imagens, faça o Claude analisá-las:
## Form layout analysis
1. Convert PDF to images:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. Analyze each page image to identify form fields
3. Claude can see field locations and types visuallyNeste exemplo, você precisaria escrever o script pdf_to_images.py.
As capacidades de visão do Claude ajudam a entender layouts e estruturas.
Quando o Claude realiza tarefas complexas e abertas, ele pode cometer erros. O padrão "planejar-validar-executar" detecta erros precocemente fazendo o Claude primeiro criar um plano em formato estruturado, depois validar esse plano com um script antes de executá-lo.
Exemplo: Imagine pedir ao Claude para atualizar 50 campos de formulário em um PDF com base em uma planilha. Sem validação, o Claude pode referenciar campos inexistentes, criar valores conflitantes, perder campos obrigatórios ou aplicar atualizações incorretamente.
Solução: Use o padrão de fluxo de trabalho mostrado acima (preenchimento de formulário PDF), mas adicione um arquivo intermediário changes.json que é validado antes de aplicar as mudanças. O fluxo de trabalho se torna: analisar → criar arquivo de plano → validar plano → executar → verificar.
Por que esse padrão funciona:
Quando usar: Operações em lote, mudanças destrutivas, regras de validação complexas, operações de alto risco.
Dica de implementação: Torne os scripts de validação verbosos com mensagens de erro específicas como "Campo 'signature_date' não encontrado. Campos disponíveis: customer_name, order_total, signature_date_signed" para ajudar o Claude a corrigir problemas.
As Skills são executadas no ambiente de execução de código com limitações específicas da plataforma:
Liste os pacotes necessários no seu SKILL.md e verifique se estão disponíveis na documentação da ferramenta de execução de código.
As Skills são executadas em um ambiente de execução de código com acesso ao sistema de arquivos, comandos bash e capacidades de execução de código. Para a explicação conceitual dessa arquitetura, consulte A arquitetura de Skills na visão geral.
Como isso afeta sua criação:
Como o Claude acessa Skills:
reference/guide.md), não barras invertidasform_validation_rules.md, não doc2.mdreference/finance.md, reference/sales.mddocs/file1.md, docs/file2.mdvalidate_form.py em vez de pedir ao Claude para gerar código de validaçãoanalyze_form.py para extrair campos" (executar)analyze_form.py para o algoritmo de extração" (ler como referência)Exemplo:
bigquery-skill/
├── SKILL.md (overview, points to reference files)
└── reference/
├── finance.md (revenue metrics)
├── sales.md (pipeline data)
└── product.md (usage analytics)Quando o usuário pergunta sobre receita, o Claude lê o SKILL.md, vê a referência a reference/finance.md e invoca o bash para ler apenas esse arquivo. Os arquivos sales.md e product.md permanecem no sistema de arquivos, consumindo zero tokens de contexto até serem necessários. Esse modelo baseado em sistema de arquivos é o que permite a divulgação progressiva. O Claude pode navegar e carregar seletivamente exatamente o que cada tarefa requer.
Para detalhes completos sobre a arquitetura técnica, consulte Como as Skills funcionam na visão geral de Skills.
Se sua Skill usa ferramentas do "Model Context Protocol", ou MCP, sempre use nomes de ferramentas totalmente qualificados para evitar erros de "ferramenta não encontrada".
Formato: ServerName:tool_name
Exemplo:
Use the BigQuery:bigquery_schema tool to retrieve table schemas.
Use the GitHub:create_issue tool to create issues.Onde:
BigQuery e GitHub são nomes de servidores MCPbigquery_schema e create_issue são os nomes das ferramentas dentro desses servidoresSem o prefixo do servidor, o Claude pode falhar em localizar a ferramenta, especialmente quando múltiplos servidores MCP estão disponíveis.
Não assuma que pacotes estão disponíveis:
**Bad example: Assumes installation**:
"Use the pdf library to process the file."
**Good example: Explicit about dependencies**:
"Install required package: `pip install pypdf`
Then use it:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"O frontmatter do SKILL.md requer os campos name e description com regras de validação específicas:
name: Máximo de 64 caracteres, apenas letras minúsculas/números/hífens, sem tags XML, sem palavras reservadasdescription: Máximo de 1024 caracteres, não vazio, sem tags XMLConsulte a visão geral de Skills para detalhes completos da estrutura.
Mantenha o corpo do SKILL.md com menos de 500 linhas para desempenho ideal. Se seu conteúdo exceder isso, divida-o em arquivos separados usando os padrões de divulgação progressiva descritos anteriormente. Para detalhes arquiteturais, consulte a visão geral de Skills.
Antes de compartilhar uma Skill, verifique:
Crie sua primeira Skill
Crie e gerencie Skills no Claude Code
Faça upload e use Skills programaticamente
Was this page helpful?