Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Construir uma aplicação bem-sucedida baseada em LLM começa com a definição clara dos seus critérios de sucesso e, em seguida, com o design de avaliações para medir o desempenho em relação a eles. Esse ciclo é central para a engenharia de prompts.
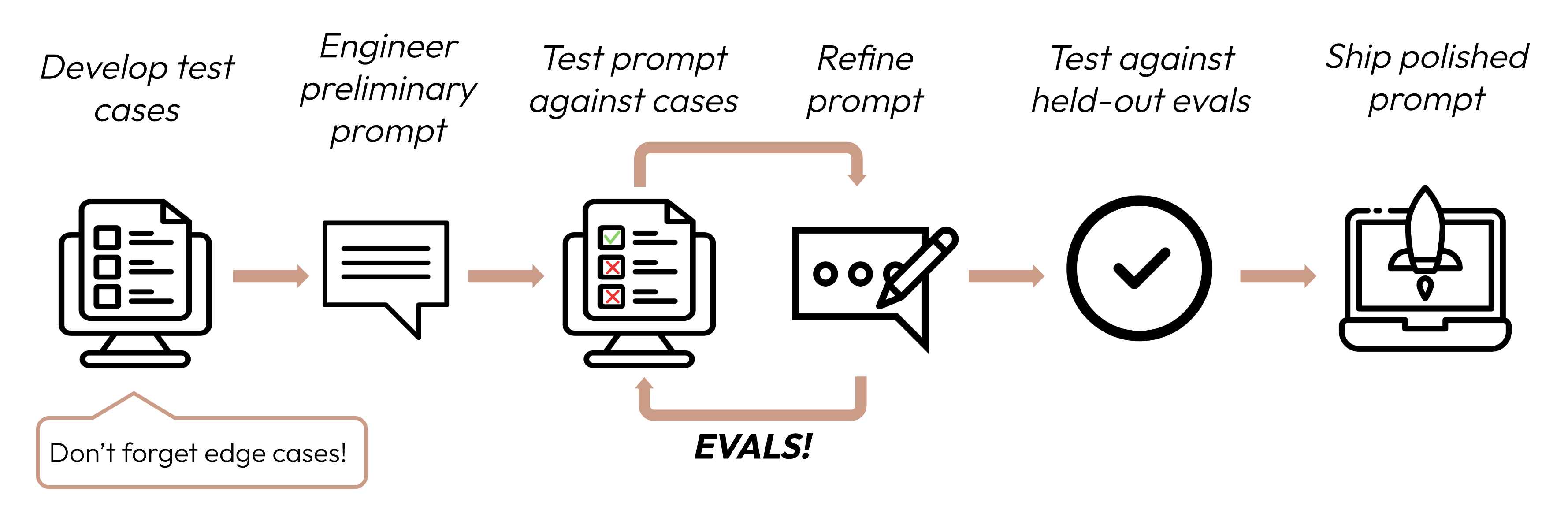
Bons critérios de sucesso são:
Específicos: Defina claramente o que você quer alcançar. Em vez de "bom desempenho", especifique "classificação precisa de sentimento".
Mensuráveis: Use métricas quantitativas ou escalas qualitativas bem definidas. Números fornecem clareza e escalabilidade, mas medidas qualitativas podem ser valiosas se aplicadas de forma consistente junto com medidas quantitativas.
| Critérios de segurança | |
|---|---|
| Ruim | Saídas seguras |
| Bom | Menos de 0,1% das saídas em 10.000 testes sinalizadas como tóxicas pelo nosso filtro de conteúdo. |
Alcançáveis: Baseie suas metas em benchmarks do setor, experimentos anteriores, pesquisas de IA ou conhecimento de especialistas. Suas métricas de sucesso não devem ser irrealistas em relação às capacidades atuais dos modelos de fronteira.
Relevantes: Alinhe seus critérios com o propósito da sua aplicação e as necessidades dos usuários. Alta precisão de citações pode ser crítica para aplicativos médicos, mas menos importante para chatbots casuais.
Aqui estão alguns critérios que podem ser importantes para o seu caso de uso. Esta lista não é exaustiva.
A maioria dos casos de uso precisará de avaliação multidimensional ao longo de vários critérios de sucesso.
Ao decidir qual método usar para avaliar as avaliações, escolha o método mais rápido, mais confiável e mais escalável:
Avaliação baseada em código: Mais rápida e confiável, extremamente escalável, mas também carece de nuances para julgamentos mais complexos que exigem menos rigidez baseada em regras.
output == golden_answerkey_phrase in outputAvaliação humana: Mais flexível e de alta qualidade, mas lenta e cara. Evite se possível.
Avaliação baseada em LLM: Rápida e flexível, escalável e adequada para julgamentos complexos. Teste primeiro para garantir confiabilidade e depois escale.
Faça brainstorm de critérios de sucesso para o seu caso de uso com o Claude no claude.ai.
Dica: Cole esta página no chat como orientação para o Claude!
Mais exemplos de código de avaliações por humanos, por código e por LLM.
Was this page helpful?