Apprenez à concevoir des cas de test et des méthodes d'évaluation pour mesurer les performances des LLM.
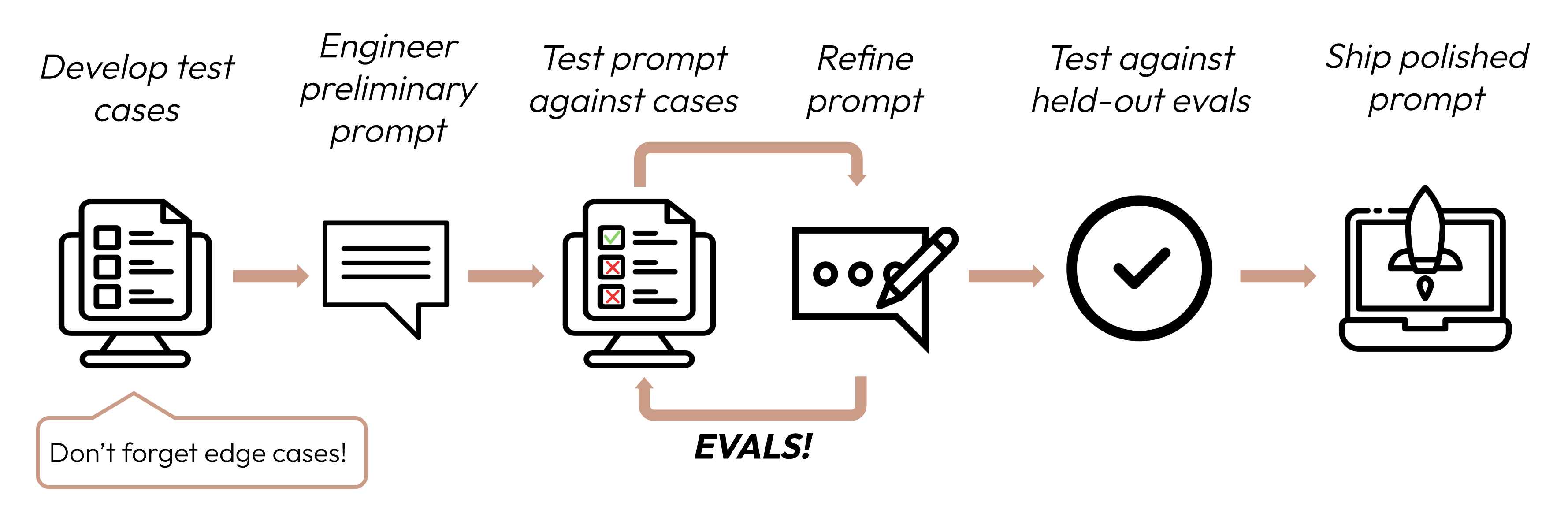
Après avoir défini vos critères de succès, l'étape suivante consiste à concevoir des évaluations pour mesurer les performances des LLM par rapport à ces critères. C'est une partie vitale du cycle d'ingénierie des invites.
Ce guide se concentre sur la façon de développer vos cas de test.
Construire des évaluations et des cas de test
Principes de conception des évaluations
Être spécifique à la tâche : Concevez des évaluations qui reflètent votre distribution de tâches réelle. N'oubliez pas de tenir compte des cas limites !
Automatiser si possible : Structurez les questions pour permettre une notation automatisée (par exemple, choix multiples, correspondance de chaîne, notation par code, notation par LLM).
Prioriser le volume à la qualité : Plus de questions avec une notation automatisée légèrement moins précise est mieux que moins de questions avec des évaluations de haute qualité notées manuellement par des humains.
Exemples d'évaluations
Écrire des centaines de cas de test à la main peut être difficile ! Demandez à Claude de vous aider à en générer d'autres à partir d'un ensemble de base de cas de test d'exemple.
Si vous ne savez pas quelles méthodes d'évaluation pourraient être utiles pour évaluer vos critères de succès, vous pouvez également faire un brainstorming avec Claude !
Notation des évaluations
Lors du choix de la méthode à utiliser pour noter les évaluations, choisissez la méthode la plus rapide, la plus fiable et la plus évolutive :
Notation basée sur le code : La plus rapide et la plus fiable, extrêmement évolutive, mais manque également de nuance pour les jugements plus complexes qui nécessitent une rigidité moins basée sur des règles.
Correspondance exacte : output == golden_answer
Correspondance de chaîne : key_phrase in output
Notation humaine : La plus flexible et de haute qualité, mais lente et coûteuse. À éviter si possible.
Notation basée sur LLM : Rapide et flexible, évolutive et adaptée aux jugements complexes. Testez d'abord pour assurer la fiabilité, puis mettez à l'échelle.
Conseils pour la notation basée sur LLM
Avoir des rubriques détaillées et claires : « La réponse doit toujours mentionner 'Acme Inc.' dans la première phrase. Si ce n'est pas le cas, la réponse est automatiquement notée comme 'incorrecte'. »
Un cas d'utilisation donné, ou même un critère de succès spécifique pour ce cas d'utilisation, pourrait nécessiter plusieurs rubriques pour une évaluation holistique.
Empirique ou spécifique : Par exemple, demandez au LLM de produire uniquement « correct » ou « incorrect », ou de juger sur une échelle de 1 à 5. Les évaluations purement qualitatives sont difficiles à évaluer rapidement et à grande échelle.
Encourager le raisonnement : Demandez au LLM de réfléchir d'abord avant de décider d'un score d'évaluation, puis jetez le raisonnement. Cela améliore les performances d'évaluation, en particulier pour les tâches nécessitant un jugement complexe.