Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
La création d'une application réussie basée sur un LLM commence par une définition claire de vos critères de réussite, puis par la conception d'évaluations permettant de mesurer les performances par rapport à ces critères. Ce cycle est au cœur de l'ingénierie de prompts.
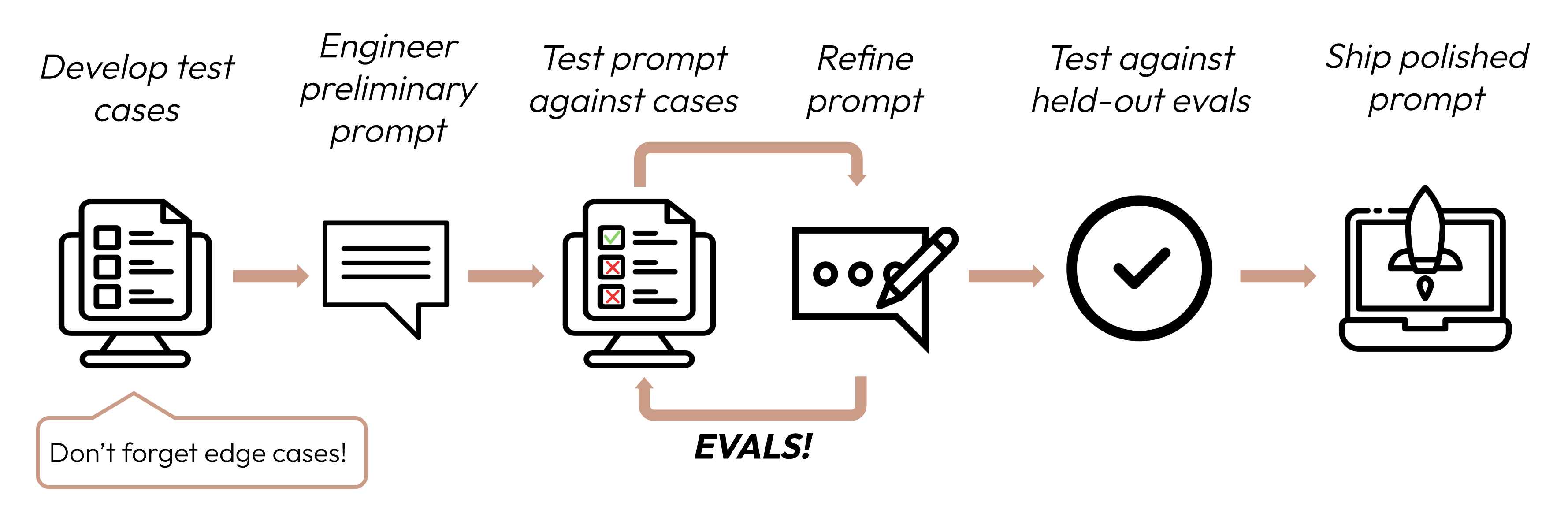
De bons critères de réussite sont :
Spécifiques : Définissez clairement ce que vous souhaitez accomplir. Au lieu de « bonnes performances », précisez « classification précise des sentiments ».
Mesurables : Utilisez des métriques quantitatives ou des échelles qualitatives bien définies. Les chiffres apportent clarté et évolutivité, mais les mesures qualitatives peuvent être précieuses si elles sont appliquées de manière cohérente en complément des mesures quantitatives.
| Critères de sécurité | |
|---|---|
| Mauvais | Sorties sûres |
| Bon | Moins de 0,1 % des sorties sur 10 000 essais signalées comme toxiques par notre filtre de contenu. |
Atteignables : Basez vos objectifs sur des références du secteur, des expériences antérieures, la recherche en IA ou des connaissances d'experts. Vos métriques de réussite ne doivent pas être irréalistes par rapport aux capacités actuelles des modèles de pointe.
Pertinents : Alignez vos critères sur l'objectif de votre application et les besoins des utilisateurs. Une grande précision des citations peut être essentielle pour les applications médicales, mais moins pour les chatbots informels.
Voici quelques critères qui pourraient être importants pour votre cas d'usage. Cette liste n'est pas exhaustive.
La plupart des cas d'usage nécessiteront une évaluation multidimensionnelle selon plusieurs critères de réussite.
Lorsque vous décidez quelle méthode utiliser pour noter les évaluations, choisissez la méthode la plus rapide, la plus fiable et la plus évolutive :
Notation par code : La plus rapide et la plus fiable, extrêmement évolutive, mais manque également de nuance pour les jugements plus complexes qui nécessitent moins de rigidité basée sur des règles.
output == golden_answerkey_phrase in outputNotation humaine : La plus flexible et de haute qualité, mais lente et coûteuse. À éviter si possible.
Notation par LLM : Rapide et flexible, évolutive et adaptée aux jugements complexes. Testez d'abord pour garantir la fiabilité, puis passez à l'échelle.
Réfléchissez aux critères de réussite pour votre cas d'usage avec Claude sur claude.ai.
Conseil : Déposez cette page dans le chat comme guide pour Claude !
Plus d'exemples de code d'évaluations notées par des humains, par code et par LLM.
Was this page helpful?