Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Les bons Skills sont concis, bien structurés et testés avec une utilisation réelle. Ce guide fournit des décisions pratiques de création pour vous aider à écrire des Skills que Claude peut découvrir et utiliser efficacement.
Pour un contexte conceptuel sur le fonctionnement des Skills, consultez la vue d'ensemble des Skills.
La « context window » (fenêtre de contexte) est un bien public. Votre Skill partage la fenêtre de contexte avec tout ce que Claude doit savoir par ailleurs, notamment :
Chaque token de votre Skill n'a pas un coût immédiat. Au démarrage, seules les métadonnées (nom et description) de tous les Skills sont préchargées. Claude lit SKILL.md uniquement lorsque le Skill devient pertinent, et lit les fichiers supplémentaires uniquement selon les besoins. Cependant, être concis dans SKILL.md reste important : une fois que Claude le charge, chaque token entre en concurrence avec l'historique de conversation et le reste du contexte.
Hypothèse par défaut : Claude est déjà très intelligent
Ajoutez uniquement le contexte que Claude ne possède pas déjà. Remettez en question chaque élément d'information :
Bon exemple : Concis (environ 50 tokens) :
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```Mauvais exemple : Trop verbeux (environ 150 tokens) :
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but
pdfplumber is recommended because it's easy to use and handles most cases well.
First, you'll need to install it using pip. Then you can use the code below...La version concise suppose que Claude sait ce que sont les PDF et comment fonctionnent les bibliothèques.
Adaptez le niveau de spécificité à la fragilité et à la variabilité de la tâche.
Liberté élevée (instructions textuelles) :
À utiliser lorsque :
Exemple :
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventionsLiberté moyenne (pseudocode ou scripts avec paramètres) :
À utiliser lorsque :
Exemple :
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```Liberté faible (scripts spécifiques, peu ou pas de paramètres) :
À utiliser lorsque :
Exemple :
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.Analogie : Pensez à Claude comme à un robot explorant un chemin :
Les Skills agissent comme des ajouts aux modèles, donc leur efficacité dépend du modèle sous-jacent. Testez votre Skill avec tous les modèles avec lesquels vous prévoyez de l'utiliser.
Considérations de test par modèle :
Ce qui fonctionne parfaitement pour Opus pourrait nécessiter plus de détails pour Haiku. Si vous prévoyez d'utiliser votre Skill avec plusieurs modèles, visez des instructions qui fonctionnent bien avec tous.
Frontmatter YAML : Le frontmatter de SKILL.md nécessite deux champs :
name :
description :
Pour les détails complets sur la structure d'un Skill, consultez la vue d'ensemble des Skills.
Utilisez des modèles de nommage cohérents pour faciliter la référence et la discussion des Skills. Envisagez d'utiliser la forme gérondive (verbe + -ing) pour les noms de Skills, car elle décrit clairement l'activité ou la capacité que le Skill fournit.
N'oubliez pas que le champ name doit utiliser uniquement des lettres minuscules, des chiffres et des traits d'union.
Bons exemples de nommage (forme gérondive) :
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentationAlternatives acceptables :
pdf-processing, spreadsheet-analysisprocess-pdfs, analyze-spreadsheetsÀ éviter :
helper, utils, toolsdocuments, data, filesanthropic-helper, claude-toolsUn nommage cohérent facilite :
Le champ description permet la découverte du Skill et doit inclure à la fois ce que fait le Skill et quand l'utiliser.
Écrivez toujours à la troisième personne. La description est injectée dans l'invite système, et un point de vue incohérent peut causer des problèmes de découverte.
Soyez spécifique et incluez des termes clés. Incluez à la fois ce que fait le Skill et les déclencheurs/contextes spécifiques pour savoir quand l'utiliser.
Chaque Skill possède exactement un champ de description. La description est critique pour la sélection du skill : Claude l'utilise pour choisir le bon Skill parmi potentiellement plus de 100 Skills disponibles. Votre description doit fournir suffisamment de détails pour que Claude sache quand sélectionner ce Skill, tandis que le reste de SKILL.md fournit les détails d'implémentation.
Exemples efficaces :
Skill de traitement de PDF :
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.Skill d'analyse Excel :
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.Skill d'aide aux commits Git :
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.Évitez les descriptions vagues comme celles-ci :
description: Helps with documentsdescription: Processes datadescription: Does stuff with filesSKILL.md sert de vue d'ensemble qui oriente Claude vers des documents détaillés selon les besoins, comme une table des matières dans un guide d'intégration. Pour une explication du fonctionnement de la divulgation progressive, consultez Comment fonctionnent les Skills dans la vue d'ensemble.
Conseils pratiques :
Un Skill de base commence avec un simple fichier SKILL.md contenant des métadonnées et des instructions :
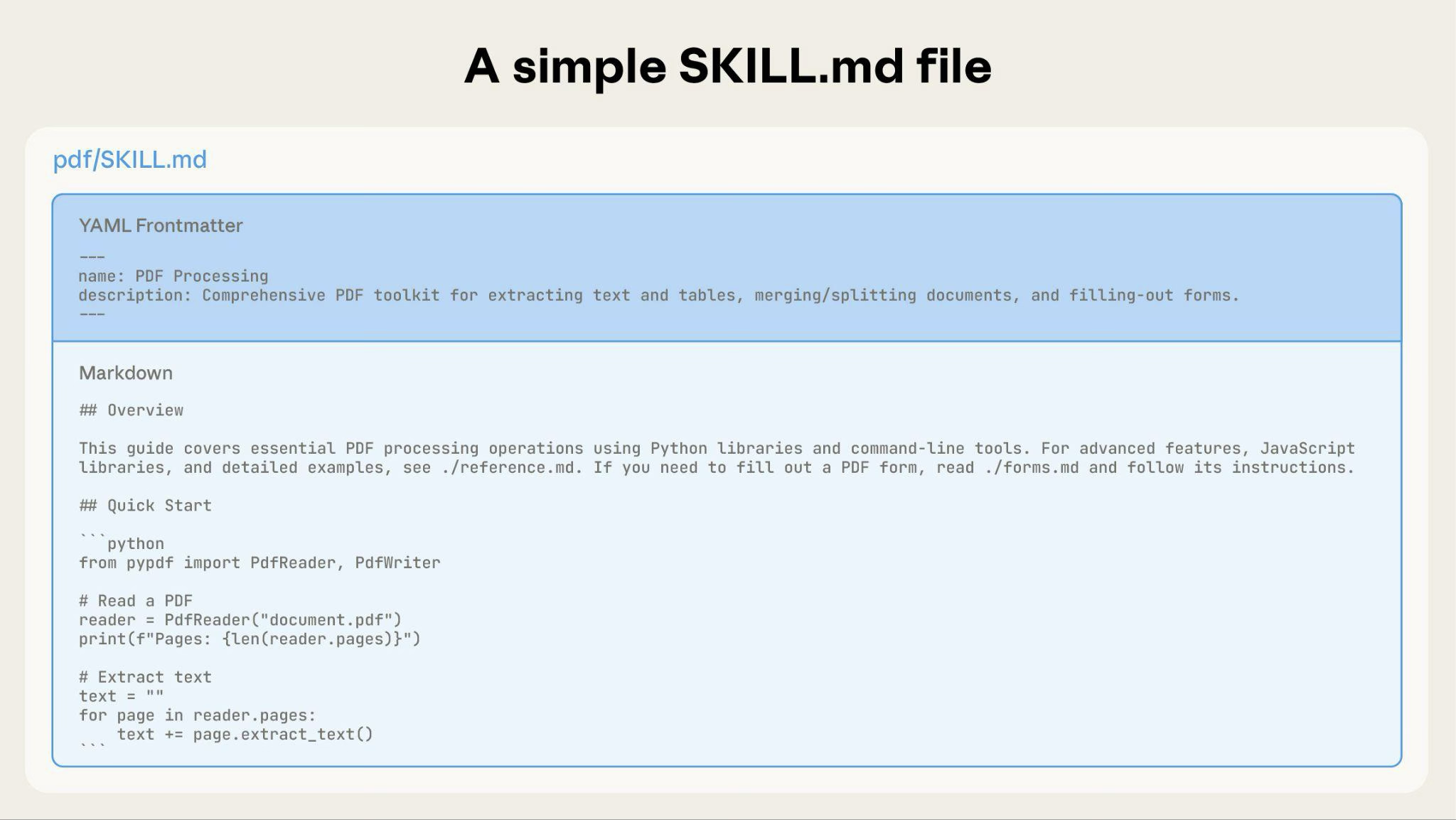
À mesure que votre Skill grandit, vous pouvez regrouper du contenu supplémentaire que Claude charge uniquement en cas de besoin :

La structure complète du répertoire du Skill pourrait ressembler à ceci :
pdf/
├── SKILL.md # Main instructions (loaded when triggered)
├── FORMS.md # Form-filling guide (loaded as needed)
├── reference.md # API reference (loaded as needed)
├── examples.md # Usage examples (loaded as needed)
└── scripts/
├── analyze_form.py # Utility script (executed, not loaded)
├── fill_form.py # Form filling script
└── validate.py # Validation script---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patternsClaude charge FORMS.md, REFERENCE.md ou EXAMPLES.md uniquement en cas de besoin.
Pour les Skills couvrant plusieurs domaines, organisez le contenu par domaine pour éviter de charger du contexte non pertinent. Lorsqu'un utilisateur pose une question sur les métriques de ventes, Claude n'a besoin de lire que les schémas liés aux ventes, pas les données financières ou marketing. Cela maintient une faible utilisation de tokens et un contexte ciblé.
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)# BigQuery Data Analysis
## Available datasets
**Finance**: Revenue, ARR, billing → See [reference/finance.md](reference/finance.md)
**Sales**: Opportunities, pipeline, accounts → See [reference/sales.md](reference/sales.md)
**Product**: API usage, features, adoption → See [reference/product.md](reference/product.md)
**Marketing**: Campaigns, attribution, email → See [reference/marketing.md](reference/marketing.md)
## Quick search
Find specific metrics using grep:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```Affichez le contenu de base, créez des liens vers le contenu avancé :
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)Claude lit REDLINING.md ou OOXML.md uniquement lorsque l'utilisateur a besoin de ces fonctionnalités.
Claude peut lire partiellement les fichiers lorsqu'ils sont référencés depuis d'autres fichiers référencés. Lorsqu'il rencontre des références imbriquées, Claude peut utiliser des commandes comme head -100 pour prévisualiser le contenu plutôt que de lire des fichiers entiers, ce qui entraîne des informations incomplètes.
Gardez les références à un seul niveau de profondeur depuis SKILL.md. Tous les fichiers de référence doivent être liés directement depuis SKILL.md pour garantir que Claude lit les fichiers complets en cas de besoin.
Mauvais exemple : Trop profond :
# SKILL.md
See [advanced.md](advanced.md)...
# advanced.md
See [details.md](details.md)...
# details.md
Here's the actual information...Bon exemple : Un seul niveau de profondeur :
# SKILL.md
**Basic usage**: [instructions in SKILL.md]
**Advanced features**: See [advanced.md](advanced.md)
**API reference**: See [reference.md](reference.md)
**Examples**: See [examples.md](examples.md)Pour les fichiers de référence de plus de 100 lignes, incluez une table des matières en haut. Cela garantit que Claude peut voir l'étendue complète des informations disponibles même lors d'une prévisualisation avec des lectures partielles.
Exemple :
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
## Authentication and setup
...
## Core methods
...Claude peut alors lire le fichier complet ou accéder directement à des sections spécifiques selon les besoins.
Pour plus de détails sur la façon dont cette architecture basée sur le système de fichiers permet la divulgation progressive, consultez la section Environnement d'exécution dans la section Avancé ci-dessous.
Décomposez les opérations complexes en étapes claires et séquentielles. Pour les workflows particulièrement complexes, fournissez une liste de contrôle que Claude peut copier dans sa réponse et cocher au fur et à mesure de sa progression.
Exemple 1 : Workflow de synthèse de recherche (pour les Skills sans code) :
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.Cet exemple montre comment les workflows s'appliquent aux tâches d'analyse qui ne nécessitent pas de code. Le modèle de liste de contrôle fonctionne pour tout processus complexe en plusieurs étapes.
Exemple 2 : Workflow de remplissage de formulaire PDF (pour les Skills avec code) :
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
```
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
```
**Step 1: Analyze the form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create field mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify output**
Run: `python scripts/verify_output.py output.pdf`
If verification fails, return to Step 2.Des étapes claires empêchent Claude de sauter des validations critiques. La liste de contrôle aide à la fois Claude et vous à suivre la progression à travers les workflows en plusieurs étapes.
Modèle courant : Exécuter le validateur → corriger les erreurs → répéter
Ce modèle améliore considérablement la qualité des résultats.
Exemple 1 : Conformité au guide de style (pour les Skills sans code) :
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the documentCeci montre le modèle de boucle de validation utilisant des documents de référence au lieu de scripts. Le « validateur » est STYLE_GUIDE.md, et Claude effectue la vérification en lisant et en comparant.
Exemple 2 : Processus d'édition de document (pour les Skills avec code) :
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test the output documentLa boucle de validation détecte les erreurs tôt.
N'incluez pas d'informations qui deviendront obsolètes :
Mauvais exemple : Sensible au temps (deviendra incorrect) :
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.Bon exemple (utilisez une section « anciens modèles ») :
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>La section des anciens modèles fournit un contexte historique sans encombrer le contenu principal.
Choisissez un terme et utilisez-le dans tout le Skill :
Bon - Cohérent :
Mauvais - Incohérent :
La cohérence aide Claude à comprendre et à suivre les instructions.
Fournissez des gabarits pour le format de sortie. Adaptez le niveau de rigueur à vos besoins.
Pour des exigences strictes (comme les réponses d'API ou les formats de données) :
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```Pour des conseils flexibles (lorsque l'adaptation est utile) :
## Report structure
Here is a sensible default format, but use your best judgment based on the analysis:
```markdown
# [Analysis Title]
## Executive summary
[Overview]
## Key findings
[Adapt sections based on what you discover]
## Recommendations
[Tailor to the specific context]
```
Adjust sections as needed for the specific analysis type.Pour les Skills où la qualité de la sortie dépend de la visualisation d'exemples, fournissez des paires entrée/sortie comme dans le prompting habituel :
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
**Example 3:**
Input: Updated dependencies and refactored error handling
Output:
```
chore: update dependencies and refactor error handling
- Upgrade lodash to 4.17.21
- Standardize error response format across endpoints
```
Follow this style: type(scope): brief description, then detailed explanation.Les exemples aident Claude à comprendre le style et le niveau de détail souhaités plus clairement que les descriptions seules.
Guidez Claude à travers les points de décision :
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when completeSi les workflows deviennent volumineux ou compliqués avec de nombreuses étapes, envisagez de les déplacer dans des fichiers séparés et dites à Claude de lire le fichier approprié en fonction de la tâche en cours.
Créez des évaluations AVANT d'écrire une documentation extensive. Cela garantit que votre Skill résout de vrais problèmes plutôt que de documenter des problèmes imaginés.
Développement piloté par l'évaluation :
Cette approche garantit que vous résolvez des problèmes réels plutôt que d'anticiper des exigences qui pourraient ne jamais se matérialiser.
Structure d'évaluation :
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF file and save it to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file using an appropriate PDF processing library or command-line tool",
"Extracts text content from all pages in the document without missing any pages",
"Saves the extracted text to a file named output.txt in a clear, readable format"
]
}Cet exemple démontre une évaluation pilotée par les données avec une grille de test simple. Il n'existe actuellement pas de moyen intégré d'exécuter ces évaluations. Les utilisateurs peuvent créer leur propre système d'évaluation. Les évaluations sont votre source de vérité pour mesurer l'efficacité d'un Skill.
Le processus de développement de Skills le plus efficace implique Claude lui-même. Travaillez avec une instance de Claude (« Claude A ») pour créer un Skill qui est utilisé par d'autres instances (« Claude B »). Claude A vous aide à concevoir et affiner les instructions, tandis que Claude B les teste dans des tâches réelles. Cela fonctionne parce que les modèles Claude comprennent à la fois comment écrire des instructions d'agent efficaces et quelles informations les agents ont besoin.
Créer un nouveau Skill :
Accomplissez une tâche sans Skill : Travaillez sur un problème avec Claude A en utilisant le prompting habituel. En travaillant, vous fournirez naturellement du contexte, expliquerez vos préférences et partagerez des connaissances procédurales. Remarquez quelles informations vous fournissez de manière répétée.
Identifiez le modèle réutilisable : Après avoir terminé la tâche, identifiez quel contexte vous avez fourni qui serait utile pour des tâches futures similaires.
Exemple : Si vous avez travaillé sur une analyse BigQuery, vous avez peut-être fourni des noms de tables, des définitions de champs, des règles de filtrage (comme « toujours exclure les comptes de test ») et des modèles de requêtes courants.
Demandez à Claude A de créer un Skill : « Crée un Skill qui capture ce modèle d'analyse BigQuery que nous venons d'utiliser. Inclus les schémas de tables, les conventions de nommage et la règle sur le filtrage des comptes de test. »
Les modèles Claude comprennent nativement le format et la structure des Skills. Vous n'avez pas besoin d'invites système spéciales ou d'un skill « d'écriture de skills » pour que Claude aide à créer des Skills. Demandez simplement à Claude de créer un Skill et il génère un contenu SKILL.md correctement structuré avec un frontmatter et un corps de contenu appropriés.
Vérifiez la concision : Vérifiez que Claude A n'a pas ajouté d'explications inutiles. Demandez : « Supprime l'explication sur ce que signifie le taux de réussite - Claude le sait déjà. »
Améliorez l'architecture de l'information : Demandez à Claude A d'organiser le contenu plus efficacement. Par exemple : « Organise ceci pour que le schéma de table soit dans un fichier de référence séparé. Nous pourrions ajouter d'autres tables plus tard. »
Testez sur des tâches similaires : Utilisez le Skill avec Claude B (une nouvelle instance avec le Skill chargé) sur des cas d'usage connexes. Observez si Claude B trouve les bonnes informations, applique correctement les règles et gère la tâche avec succès.
Itérez en fonction de l'observation : Si Claude B rencontre des difficultés ou manque quelque chose, retournez vers Claude A avec des détails : « Quand Claude a utilisé ce Skill, il a oublié de filtrer par date pour le T4. Devrions-nous ajouter une section sur les modèles de filtrage par date ? »
Itérer sur des Skills existants :
Le même modèle hiérarchique continue lors de l'amélioration des Skills. Vous alternez entre :
Utilisez le Skill dans des workflows réels : Donnez à Claude B (avec le Skill chargé) des tâches réelles, pas des scénarios de test
Observez le comportement de Claude B : Notez où il rencontre des difficultés, réussit ou fait des choix inattendus
Exemple d'observation : « Quand j'ai demandé à Claude B un rapport de ventes régional, il a écrit la requête mais a oublié de filtrer les comptes de test, même si le Skill mentionne cette règle. »
Retournez vers Claude A pour des améliorations : Partagez le SKILL.md actuel et décrivez ce que vous avez observé. Demandez : « J'ai remarqué que Claude B a oublié de filtrer les comptes de test quand j'ai demandé un rapport régional. Le Skill mentionne le filtrage, mais peut-être n'est-il pas assez visible ? »
Examinez les suggestions de Claude A : Claude A pourrait suggérer de réorganiser pour rendre les règles plus visibles, d'utiliser un langage plus fort comme « DOIT filtrer » au lieu de « toujours filtrer », ou de restructurer la section workflow.
Appliquez et testez les changements : Mettez à jour le Skill avec les améliorations de Claude A, puis testez à nouveau avec Claude B sur des demandes similaires
Répétez en fonction de l'utilisation : Continuez ce cycle observer-affiner-tester à mesure que vous rencontrez de nouveaux scénarios. Chaque itération améliore le Skill en fonction du comportement réel de l'agent, pas d'hypothèses.
Recueillir les retours de l'équipe :
Pourquoi cette approche fonctionne : Claude A comprend les besoins des agents, vous fournissez l'expertise du domaine, Claude B révèle les lacunes par une utilisation réelle, et l'affinement itératif améliore les Skills en fonction du comportement observé plutôt que d'hypothèses.
À mesure que vous itérez sur les Skills, prêtez attention à la façon dont Claude les utilise réellement en pratique. Surveillez :
Itérez en fonction de ces observations plutôt que d'hypothèses. Les champs « name » et « description » dans les métadonnées de votre Skill sont particulièrement critiques. Claude les utilise pour décider s'il doit déclencher le Skill en réponse à la tâche en cours. Assurez-vous qu'ils décrivent clairement ce que fait le Skill et quand il doit être utilisé.
Utilisez toujours des barres obliques dans les chemins de fichiers, même sous Windows :
scripts/helper.py, reference/guide.mdscripts\helper.py, reference\guide.mdLes chemins de style Unix fonctionnent sur toutes les plateformes, tandis que les chemins de style Windows provoquent des erreurs sur les systèmes Unix.
Ne présentez pas plusieurs approches sauf si nécessaire :
**Bad example: Too many choices** (confusing):
"You can use pypdf, or pdfplumber, or PyMuPDF, or pdf2image, or..."
**Good example: Provide a default** (with escape hatch):
"Use pdfplumber for text extraction:
```python
import pdfplumber
```
For scanned PDFs requiring OCR, use pdf2image with pytesseract instead."Les sections ci-dessous se concentrent sur les Skills qui incluent des scripts exécutables. Si votre Skill utilise uniquement des instructions markdown, passez à la Liste de contrôle pour des Skills efficaces.
Lorsque vous écrivez des scripts pour des Skills, gérez les conditions d'erreur plutôt que de les déléguer à Claude.
Bon exemple : Gérer les erreurs explicitement :
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# Créer le fichier avec un contenu par défaut au lieu d'échouer
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# Fournir une alternative au lieu d'échouer
print(f"Cannot access {path}, using default")
return ""Mauvais exemple : Déléguer à Claude :
def process_file(path):
# Échouer simplement et laisser Claude se débrouiller
return open(path).read()Les paramètres de configuration doivent également être justifiés et documentés pour éviter les « constantes vaudou » (loi d'Ousterhout). Si vous ne connaissez pas la bonne valeur, comment Claude la déterminera-t-il ?
Bon exemple : Auto-documenté :
# Les requêtes HTTP se terminent généralement en moins de 30 secondes
# Un délai d'attente plus long tient compte des connexions lentes
REQUEST_TIMEOUT = 30
# Trois tentatives équilibrent fiabilité et rapidité
# La plupart des échecs intermittents se résolvent à la deuxième tentative
MAX_RETRIES = 3Mauvais exemple : Nombres magiques :
TIMEOUT = 47 # Why 47?
RETRIES = 5 # Why 5?Même si Claude pourrait écrire un script, les scripts préfabriqués offrent des avantages :
Avantages des scripts utilitaires :

Le diagramme ci-dessus montre comment les scripts exécutables fonctionnent aux côtés des fichiers d'instructions. Le fichier d'instructions (forms.md) référence le script, et Claude peut l'exécuter sans charger son contenu dans le contexte.
Distinction importante : Indiquez clairement dans vos instructions si Claude doit :
analyze_form.py pour extraire les champs »analyze_form.py pour l'algorithme d'extraction de champs »Pour la plupart des scripts utilitaires, l'exécution est préférable car elle est plus fiable et efficace. Consultez la section Environnement d'exécution ci-dessous pour plus de détails sur le fonctionnement de l'exécution de scripts.
Exemple :
## Utility scripts
**analyze_form.py**: Extract all form fields from PDF
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
Output format:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**: Check for overlapping bounding boxes
```bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
```
**fill_form.py**: Apply field values to PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```Lorsque les entrées peuvent être rendues sous forme d'images, faites-les analyser par Claude :
## Form layout analysis
1. Convert PDF to images:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. Analyze each page image to identify form fields
3. Claude can see field locations and types visuallyDans cet exemple, vous devriez écrire le script pdf_to_images.py.
Les capacités de vision de Claude aident à comprendre les mises en page et les structures.
Lorsque Claude effectue des tâches complexes et ouvertes, il peut faire des erreurs. Le modèle « planifier-valider-exécuter » détecte les erreurs tôt en demandant à Claude de créer d'abord un plan dans un format structuré, puis de valider ce plan avec un script avant de l'exécuter.
Exemple : Imaginez demander à Claude de mettre à jour 50 champs de formulaire dans un PDF à partir d'une feuille de calcul. Sans validation, Claude pourrait référencer des champs inexistants, créer des valeurs conflictuelles, manquer des champs obligatoires ou appliquer des mises à jour incorrectement.
Solution : Utilisez le modèle de workflow présenté ci-dessus (remplissage de formulaire PDF), mais ajoutez un fichier intermédiaire changes.json qui est validé avant d'appliquer les changements. Le workflow devient : analyser → créer le fichier de plan → valider le plan → exécuter → vérifier.
Pourquoi ce modèle fonctionne :
Quand l'utiliser : Opérations par lots, changements destructifs, règles de validation complexes, opérations à enjeux élevés.
Conseil d'implémentation : Rendez les scripts de validation verbeux avec des messages d'erreur spécifiques comme « Field 'signature_date' not found. Available fields: customer_name, order_total, signature_date_signed » pour aider Claude à corriger les problèmes.
Les Skills s'exécutent dans l'environnement d'exécution de code avec des limitations spécifiques à la plateforme :
Listez les packages requis dans votre SKILL.md et vérifiez qu'ils sont disponibles dans la documentation de l'outil d'exécution de code.
Les Skills s'exécutent dans un environnement d'exécution de code avec accès au système de fichiers, commandes bash et capacités d'exécution de code. Pour l'explication conceptuelle de cette architecture, consultez L'architecture des Skills dans la vue d'ensemble.
Comment cela affecte votre création :
Comment Claude accède aux Skills :
reference/guide.md), pas des barres obliques inverséesform_validation_rules.md, pas doc2.mdreference/finance.md, reference/sales.mddocs/file1.md, docs/file2.mdvalidate_form.py plutôt que de demander à Claude de générer du code de validationanalyze_form.py pour extraire les champs » (exécuter)analyze_form.py pour l'algorithme d'extraction » (lire comme référence)Exemple :
bigquery-skill/
├── SKILL.md (overview, points to reference files)
└── reference/
├── finance.md (revenue metrics)
├── sales.md (pipeline data)
└── product.md (usage analytics)Lorsque l'utilisateur pose une question sur le chiffre d'affaires, Claude lit SKILL.md, voit la référence à reference/finance.md et invoque bash pour lire uniquement ce fichier. Les fichiers sales.md et product.md restent sur le système de fichiers, ne consommant aucun token de contexte jusqu'à ce qu'ils soient nécessaires. Ce modèle basé sur le système de fichiers est ce qui permet la divulgation progressive. Claude peut naviguer et charger sélectivement exactement ce dont chaque tâche a besoin.
Pour les détails complets sur l'architecture technique, consultez Comment fonctionnent les Skills dans la vue d'ensemble des Skills.
Si votre Skill utilise des outils MCP (Model Context Protocol), utilisez toujours des noms d'outils entièrement qualifiés pour éviter les erreurs « tool not found ».
Format : ServerName:tool_name
Exemple :
Use the BigQuery:bigquery_schema tool to retrieve table schemas.
Use the GitHub:create_issue tool to create issues.Où :
BigQuery et GitHub sont des noms de serveurs MCPbigquery_schema et create_issue sont les noms d'outils au sein de ces serveursSans le préfixe du serveur, Claude peut échouer à localiser l'outil, en particulier lorsque plusieurs serveurs MCP sont disponibles.
Ne supposez pas que des packages sont disponibles :
**Bad example: Assumes installation**:
"Use the pdf library to process the file."
**Good example: Explicit about dependencies**:
"Install required package: `pip install pypdf`
Then use it:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"Le frontmatter de SKILL.md nécessite les champs name et description avec des règles de validation spécifiques :
name : Maximum 64 caractères, lettres minuscules/chiffres/traits d'union uniquement, pas de balises XML, pas de mots réservésdescription : Maximum 1024 caractères, non vide, pas de balises XMLConsultez la vue d'ensemble des Skills pour les détails complets de la structure.
Gardez le corps de SKILL.md sous 500 lignes pour des performances optimales. Si votre contenu dépasse cette limite, divisez-le en fichiers séparés en utilisant les modèles de divulgation progressive décrits précédemment. Pour les détails architecturaux, consultez la vue d'ensemble des Skills.
Avant de partager un Skill, vérifiez :
Créez votre premier Skill
Créez et gérez des Skills dans Claude Code
Téléversez et utilisez des Skills par programmation
Was this page helpful?