Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
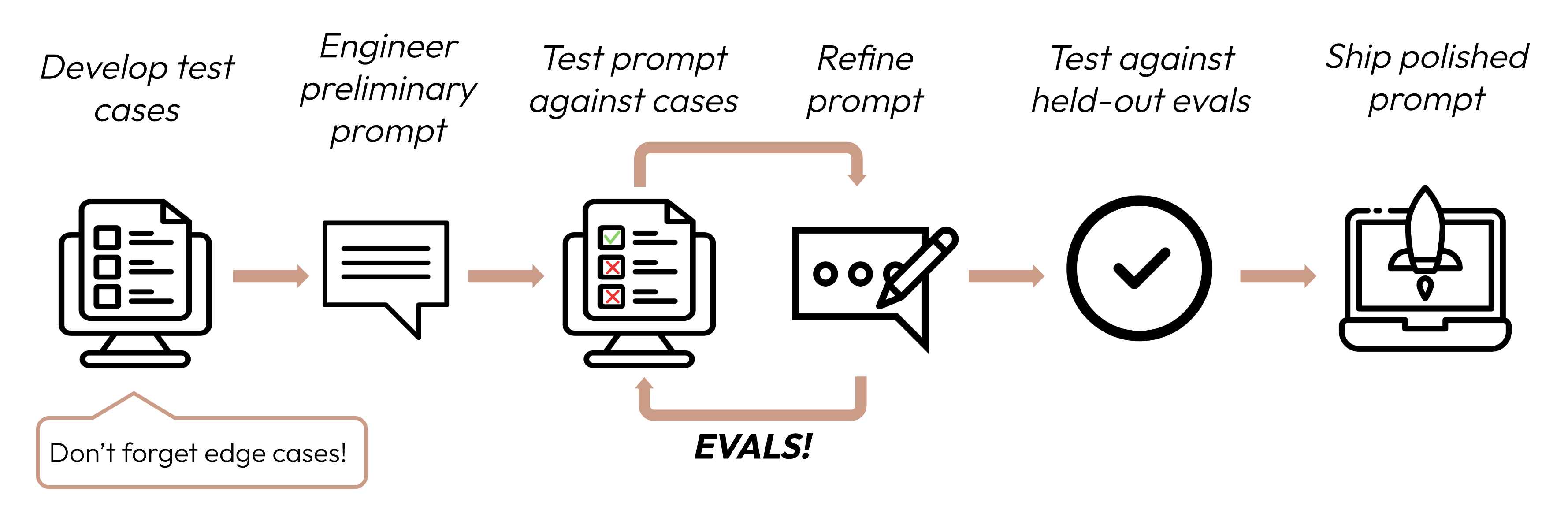
Building a successful LLM-based application starts with clearly defining your success criteria and then designing evaluations to measure performance against them. This cycle is central to prompt engineering.
Good success criteria are:
Specific: Clearly define what you want to achieve. Instead of "good performance," specify "accurate sentiment classification."
Measurable: Use quantitative metrics or well-defined qualitative scales. Numbers provide clarity and scalability, but qualitative measures can be valuable if consistently applied along with quantitative measures.
| Safety criteria | |
|---|---|
| Bad | Safe outputs |
| Good | Less than 0.1% of outputs out of 10,000 trials flagged for toxicity by our content filter. |
Achievable: Base your targets on industry benchmarks, prior experiments, AI research, or expert knowledge. Your success metrics should not be unrealistic to current frontier model capabilities.
Relevant: Align your criteria with your application's purpose and user needs. Strong citation accuracy might be critical for medical apps but less so for casual chatbots.
Here are some criteria that might be important for your use case. This list is non-exhaustive.
Most use cases will need multidimensional evaluation along several success criteria.
When deciding which method to use to grade evals, choose the fastest, most reliable, most scalable method:
Code-based grading: Fastest and most reliable, extremely scalable, but also lacks nuance for more complex judgements that require less rule-based rigidity.
output == golden_answerkey_phrase in outputHuman grading: Most flexible and high quality, but slow and expensive. Avoid if possible.
LLM-based grading: Fast and flexible, scalable and suitable for complex judgement. Test to ensure reliability first then scale.
Brainstorm success criteria for your use case with Claude on claude.ai.
Tip: Drop this page into the chat as guidance for Claude!
More code examples of human-, code-, and LLM-graded evals.
Was this page helpful?