Pelajari cara merancang evaluasi untuk mengukur kinerja LLM terhadap kriteria kesuksesan Anda.
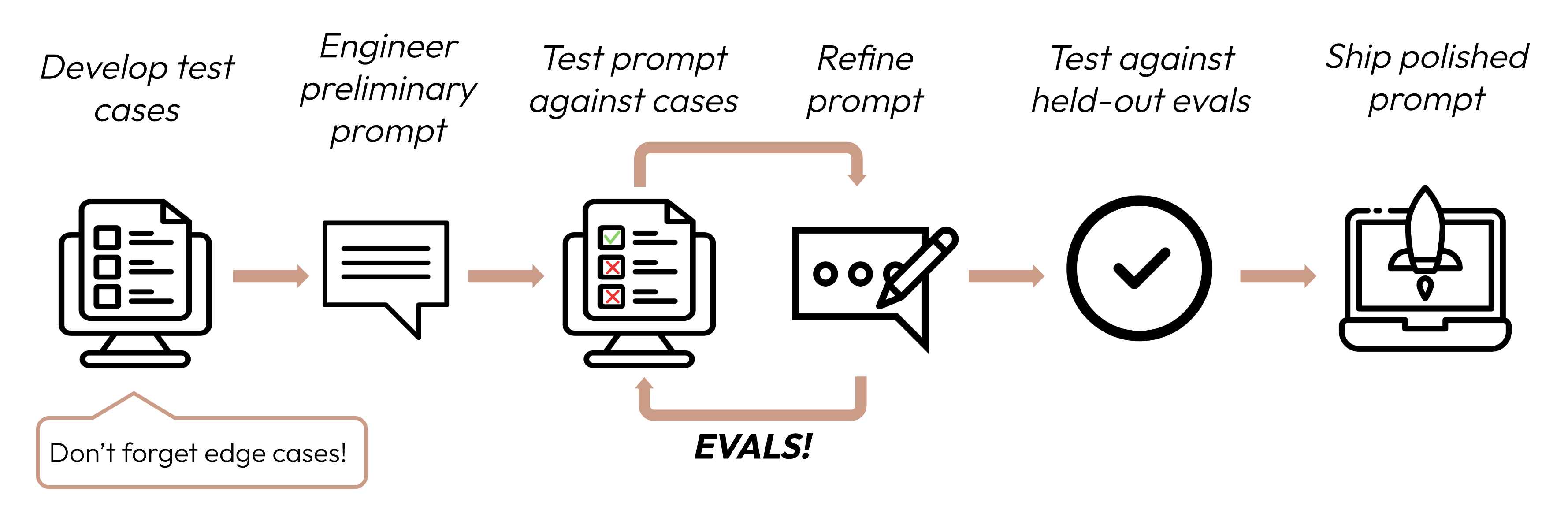
Setelah menentukan kriteria kesuksesan Anda, langkah berikutnya adalah merancang evaluasi untuk mengukur kinerja LLM terhadap kriteria tersebut. Ini adalah bagian penting dari siklus prompt engineering.
Panduan ini berfokus pada cara mengembangkan test case Anda.
Membangun evals dan test case
Prinsip desain eval
Spesifik untuk tugas: Rancang evals yang mencerminkan distribusi tugas dunia nyata Anda. Jangan lupa untuk mempertimbangkan edge case!
Otomatisasi jika memungkinkan: Struktur pertanyaan untuk memungkinkan penilaian otomatis (misalnya, pilihan ganda, string match, code-graded, LLM-graded).
Prioritaskan volume daripada kualitas: Lebih banyak pertanyaan dengan penilaian otomatis sinyal yang sedikit lebih rendah lebih baik daripada lebih sedikit pertanyaan dengan evals hand-graded berkualitas tinggi oleh manusia.
Contoh evals
Menulis ratusan test case bisa sulit dilakukan dengan tangan! Minta Claude untuk membantu Anda menghasilkan lebih banyak dari satu set test case contoh baseline.
Jika Anda tidak tahu metode eval apa yang mungkin berguna untuk menilai kriteria kesuksesan Anda, Anda juga dapat brainstorm dengan Claude!
Penilaian evals
Saat memutuskan metode mana yang digunakan untuk menilai evals, pilih metode yang tercepat, paling andal, dan paling dapat diskalakan:
Penilaian berbasis kode: Tercepat dan paling andal, sangat dapat diskalakan, tetapi juga kurang bernuansa untuk penilaian yang lebih kompleks yang memerlukan kekakuan berbasis aturan yang lebih sedikit.
Exact match: output == golden_answer
String match: key_phrase in output
Penilaian manusia: Paling fleksibel dan berkualitas tinggi, tetapi lambat dan mahal. Hindari jika memungkinkan.
Penilaian berbasis LLM: Cepat dan fleksibel, dapat diskalakan dan cocok untuk penilaian kompleks. Uji untuk memastikan keandalan terlebih dahulu kemudian skalakan.
Tips untuk penilaian berbasis LLM
Miliki rubrik yang terperinci dan jelas: "Jawaban harus selalu menyebutkan 'Acme Inc.' di kalimat pertama. Jika tidak, jawaban secara otomatis dinilai sebagai 'tidak benar.'"
Kasus penggunaan tertentu, atau bahkan kriteria kesuksesan spesifik untuk kasus penggunaan itu, mungkin memerlukan beberapa rubrik untuk evaluasi holistik.
Empiris atau spesifik: Misalnya, instruksikan LLM untuk hanya mengeluarkan 'benar' atau 'tidak benar', atau untuk menilai dari skala 1-5. Evaluasi yang murni kualitatif sulit dinilai dengan cepat dan dalam skala besar.
Dorong penalaran: Minta LLM untuk berpikir terlebih dahulu sebelum memutuskan skor evaluasi, kemudian buang penalarannya. Ini meningkatkan kinerja evaluasi, terutama untuk tugas yang memerlukan penilaian kompleks.