Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Membangun aplikasi berbasis LLM yang sukses dimulai dengan mendefinisikan kriteria keberhasilan Anda secara jelas, lalu merancang evaluasi untuk mengukur kinerja terhadap kriteria tersebut. Siklus ini merupakan inti dari "prompt engineering" (rekayasa prompt).
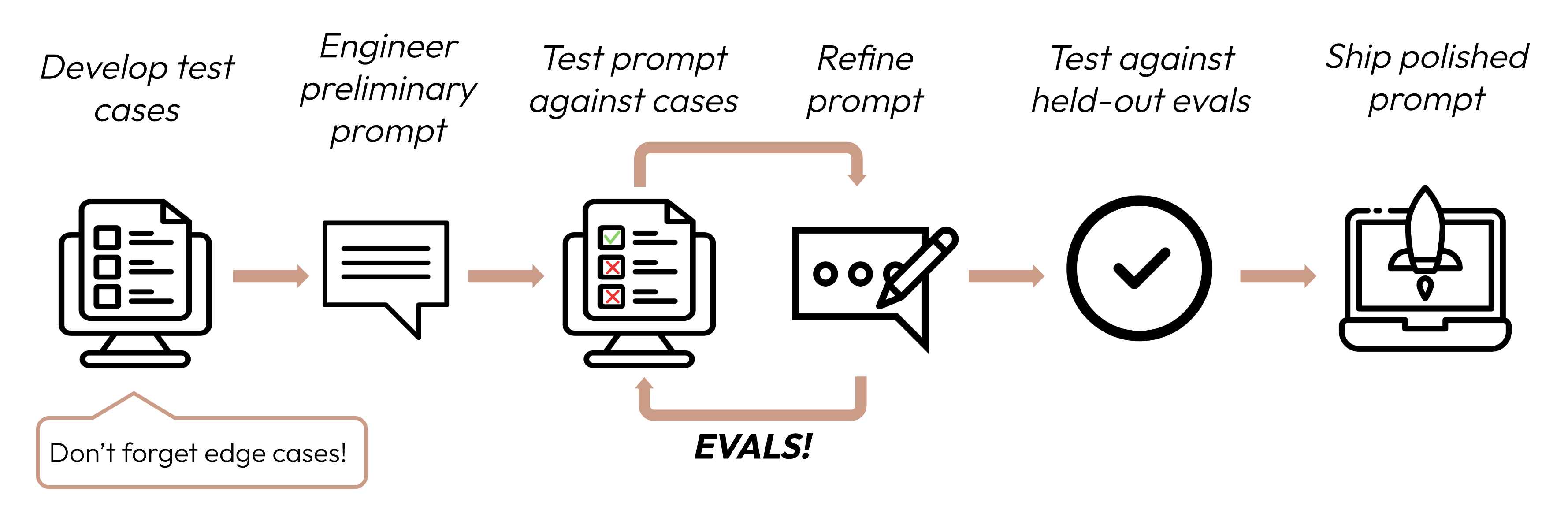
Kriteria keberhasilan yang baik bersifat:
Spesifik: Definisikan dengan jelas apa yang ingin Anda capai. Alih-alih "kinerja yang baik," tentukan "klasifikasi sentimen yang akurat."
Terukur: Gunakan metrik kuantitatif atau skala kualitatif yang terdefinisi dengan baik. Angka memberikan kejelasan dan skalabilitas, tetapi ukuran kualitatif dapat bernilai jika diterapkan secara konsisten bersama dengan ukuran kuantitatif.
| Kriteria keamanan | |
|---|---|
| Buruk | Output yang aman |
| Baik | Kurang dari 0,1% output dari 10.000 percobaan ditandai sebagai toksik oleh filter konten kami. |
Dapat dicapai: Dasarkan target Anda pada tolok ukur industri, eksperimen sebelumnya, riset AI, atau pengetahuan ahli. Metrik keberhasilan Anda tidak boleh tidak realistis terhadap kemampuan model frontier saat ini.
Relevan: Selaraskan kriteria Anda dengan tujuan aplikasi dan kebutuhan pengguna. Akurasi sitasi yang kuat mungkin sangat penting untuk aplikasi medis, tetapi tidak begitu penting untuk chatbot kasual.
Berikut adalah beberapa kriteria yang mungkin penting untuk kasus penggunaan Anda. Daftar ini tidak lengkap.
Sebagian besar kasus penggunaan akan memerlukan evaluasi multidimensi di sepanjang beberapa kriteria keberhasilan.
Saat memutuskan metode mana yang akan digunakan untuk menilai evaluasi, pilih metode yang paling cepat, paling andal, dan paling dapat diskalakan:
Penilaian berbasis kode: Paling cepat dan paling andal, sangat dapat diskalakan, tetapi juga kurang bernuansa untuk penilaian yang lebih kompleks yang memerlukan kekakuan berbasis aturan yang lebih rendah.
output == golden_answerkey_phrase in outputPenilaian manusia: Paling fleksibel dan berkualitas tinggi, tetapi lambat dan mahal. Hindari jika memungkinkan.
Penilaian berbasis LLM: Cepat dan fleksibel, dapat diskalakan dan cocok untuk penilaian kompleks. Uji terlebih dahulu untuk memastikan keandalan, lalu skalakan.
Lakukan brainstorming kriteria keberhasilan untuk kasus penggunaan Anda dengan Claude di claude.ai.
Tip: Masukkan halaman ini ke dalam chat sebagai panduan untuk Claude!
Lebih banyak contoh kode evaluasi yang dinilai manusia, kode, dan LLM.
Was this page helpful?