Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
建立成功的 LLM 應用程式,首先要清楚定義您的成功標準,然後設計評估來衡量相對於這些標準的表現。這個循環是提示工程的核心。
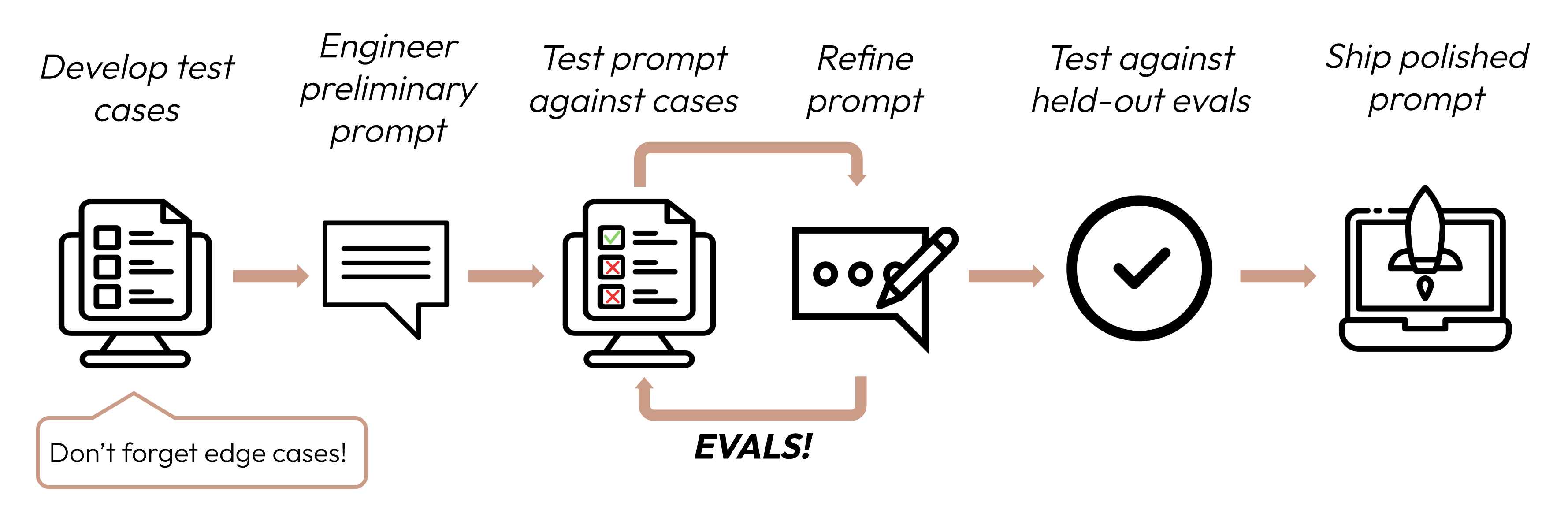
良好的成功標準應具備以下特性:
具體(Specific): 清楚定義您想要達成的目標。與其說「良好的表現」,不如具體說明「準確的情感分類」。
可衡量(Measurable): 使用量化指標或定義明確的質化量表。數字能提供清晰度和可擴展性,但如果能與量化指標一併持續應用,質化衡量也很有價值。
| 安全標準 | |
|---|---|
| 不佳 | 安全的輸出 |
| 良好 | 在 10,000 次試驗中,被我們的內容過濾器標記為有毒的輸出少於 0.1%。 |
可達成(Achievable): 根據產業基準、先前實驗、AI 研究或專家知識來設定目標。您的成功指標不應超出當前前沿模型能力的現實範圍。
相關(Relevant): 使您的標準與應用程式的目的和使用者需求保持一致。高度的引用準確性對醫療應用程式可能至關重要,但對休閒聊天機器人則不那麼重要。
以下是一些可能對您的使用案例很重要的標準。此清單並非詳盡無遺。
大多數使用案例都需要沿著多個成功標準進行多維度評估。
在決定使用哪種方法為評估評分時,請選擇最快速、最可靠、最具擴展性的方法:
基於程式碼的評分: 最快速且最可靠,極具擴展性,但對於需要較少規則剛性的複雜判斷,缺乏細緻度。
output == golden_answerkey_phrase in output人工評分: 最靈活且品質最高,但速度慢且成本高。盡可能避免。
基於 LLM 的評分: 快速且靈活,具擴展性且適合複雜判斷。請先測試以確保可靠性,然後再擴展。
在 claude.ai 上與 Claude 一起為您的使用案例腦力激盪成功標準。
提示:將此頁面放入對話中作為 Claude 的指引!
更多人工評分、程式碼評分和 LLM 評分評估的程式碼範例。
Was this page helpful?