Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
好的 Skills 是簡潔、結構良好且經過實際使用測試的。本指南提供實用的撰寫決策,幫助您撰寫 Claude 能夠有效發現和使用的 Skills。
有關 Skills 運作方式的概念背景,請參閱 Skills 概覽。
「Context window」(上下文視窗)是一種公共資源。您的 Skill 與 Claude 需要知道的所有其他內容共享上下文視窗,包括:
並非您 Skill 中的每個 token 都有立即的成本。在啟動時,只有所有 Skills 的元數據(名稱和描述)會被預先載入。Claude 只有在 Skill 變得相關時才會讀取 SKILL.md,並且只在需要時讀取額外的檔案。然而,在 SKILL.md 中保持簡潔仍然很重要:一旦 Claude 載入它,每個 token 都會與對話歷史和其他上下文競爭。
預設假設: Claude 已經非常聰明
只添加 Claude 尚未擁有的上下文。質疑每一條資訊:
好的範例:簡潔(約 50 個 tokens):
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```壞的範例:過於冗長(約 150 個 tokens):
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but
pdfplumber is recommended because it's easy to use and handles most cases well.
First, you'll need to install it using pip. Then you can use the code below...簡潔版本假設 Claude 知道什麼是 PDF 以及函式庫如何運作。
將具體程度與任務的脆弱性和變異性相匹配。
高自由度(基於文字的指示):
適用於:
範例:
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventions中等自由度(偽代碼或帶參數的腳本):
適用於:
範例:
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```低自由度(特定腳本,少量或無參數):
適用於:
範例:
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.類比: 將 Claude 想像成一個探索路徑的機器人:
Skills 作為模型的附加功能,因此有效性取決於底層模型。使用您計劃搭配使用的所有模型測試您的 Skill。
按模型的測試考量:
對 Opus 完美有效的內容可能需要為 Haiku 提供更多細節。如果您計劃在多個模型中使用您的 Skill,請力求撰寫對所有模型都有效的指示。
YAML Frontmatter: SKILL.md 的 frontmatter 需要兩個欄位:
name:
description:
有關完整的 Skill 結構詳細資訊,請參閱 Skills 概覽。
使用一致的命名模式,使 Skills 更容易引用和討論。考慮為 Skill 名稱使用動名詞形式(動詞 + -ing),因為這清楚地描述了 Skill 提供的活動或能力。
請記住,name 欄位只能使用小寫字母、數字和連字號。
好的命名範例(動名詞形式):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation可接受的替代方案:
pdf-processing、spreadsheet-analysisprocess-pdfs、analyze-spreadsheets避免:
helper、utils、toolsdocuments、data、filesanthropic-helper、claude-tools一致的命名使以下事項更容易:
description 欄位使 Skill 能夠被發現,應同時包含 Skill 的功能以及何時使用它。
始終使用第三人稱撰寫。描述會被注入到系統提示中,不一致的視角可能會導致發現問題。
要具體並包含關鍵詞。同時包含 Skill 的功能以及使用它的具體觸發條件/情境。
每個 Skill 只有一個 description 欄位。描述對於 skill 選擇至關重要:Claude 使用它從可能超過 100 個可用的 Skills 中選擇正確的 Skill。您的描述必須提供足夠的細節,讓 Claude 知道何時選擇這個 Skill,而 SKILL.md 的其餘部分則提供實作細節。
有效的範例:
PDF 處理 skill:
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.Excel 分析 skill:
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.Git Commit 助手 skill:
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.避免像這樣模糊的描述:
description: Helps with documentsdescription: Processes datadescription: Does stuff with filesSKILL.md 作為一個概覽,在需要時將 Claude 指向詳細的材料,就像入職指南中的目錄一樣。有關漸進式揭露如何運作的說明,請參閱概覽中的 Skills 如何運作。
實用指引:
一個基本的 Skill 從只包含元數據和指示的 SKILL.md 檔案開始:
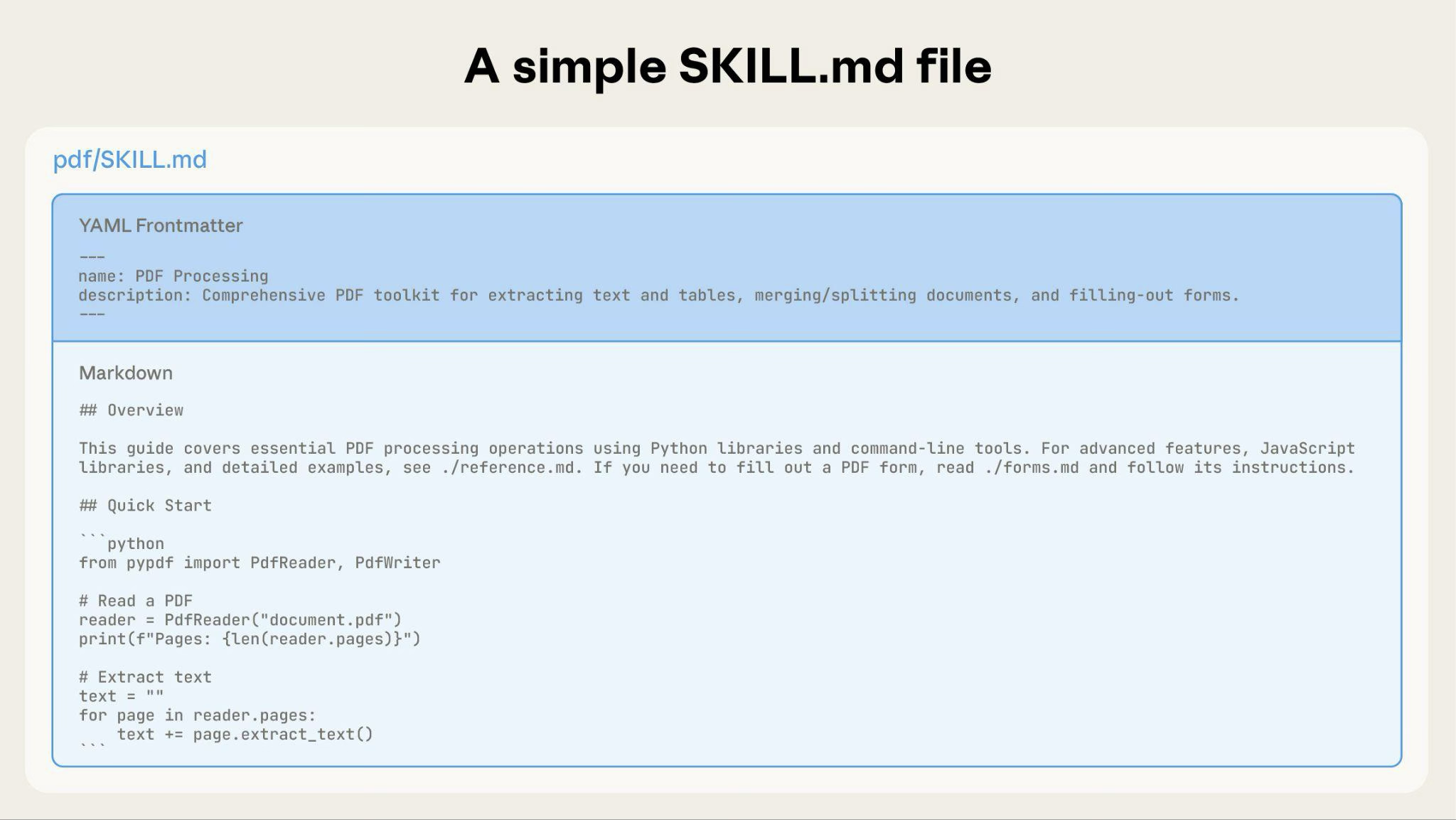
隨著您的 Skill 成長,您可以捆綁 Claude 只在需要時載入的額外內容:

完整的 Skill 目錄結構可能如下所示:
pdf/
├── SKILL.md # Main instructions (loaded when triggered)
├── FORMS.md # Form-filling guide (loaded as needed)
├── reference.md # API reference (loaded as needed)
├── examples.md # Usage examples (loaded as needed)
└── scripts/
├── analyze_form.py # Utility script (executed, not loaded)
├── fill_form.py # Form filling script
└── validate.py # Validation script---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patternsClaude 只在需要時載入 FORMS.md、REFERENCE.md 或 EXAMPLES.md。
對於具有多個領域的 Skills,按領域組織內容以避免載入不相關的上下文。當使用者詢問銷售指標時,Claude 只需要讀取與銷售相關的架構,而不是財務或行銷數據。這可以保持低 token 使用量和專注的上下文。
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)# BigQuery Data Analysis
## Available datasets
**Finance**: Revenue, ARR, billing → See [reference/finance.md](reference/finance.md)
**Sales**: Opportunities, pipeline, accounts → See [reference/sales.md](reference/sales.md)
**Product**: API usage, features, adoption → See [reference/product.md](reference/product.md)
**Marketing**: Campaigns, attribution, email → See [reference/marketing.md](reference/marketing.md)
## Quick search
Find specific metrics using grep:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```顯示基本內容,連結到進階內容:
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)Claude 只在使用者需要這些功能時才讀取 REDLINING.md 或 OOXML.md。
當檔案從其他被引用的檔案中被引用時,Claude 可能會部分讀取檔案。遇到巢狀引用時,Claude 可能會使用像 head -100 這樣的命令來預覽內容,而不是讀取整個檔案,導致資訊不完整。
保持引用距離 SKILL.md 只有一層深度。所有參考檔案都應直接從 SKILL.md 連結,以確保 Claude 在需要時讀取完整的檔案。
壞的範例:太深:
# SKILL.md
See [advanced.md](advanced.md)...
# advanced.md
See [details.md](details.md)...
# details.md
Here's the actual information...好的範例:一層深度:
# SKILL.md
**Basic usage**: [instructions in SKILL.md]
**Advanced features**: See [advanced.md](advanced.md)
**API reference**: See [reference.md](reference.md)
**Examples**: See [examples.md](examples.md)對於超過 100 行的參考檔案,在頂部包含目錄。這確保 Claude 即使在部分讀取預覽時也能看到可用資訊的完整範圍。
範例:
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
## Authentication and setup
...
## Core methods
...然後 Claude 可以讀取完整的檔案或根據需要跳到特定章節。
有關這種基於檔案系統的架構如何實現漸進式揭露的詳細資訊,請參閱下面進階章節中的執行環境章節。
將複雜的操作分解為清晰、循序的步驟。對於特別複雜的工作流程,提供一個檢查清單,讓 Claude 可以複製到其回應中並在進展時勾選。
範例 1:研究綜合工作流程(適用於不含程式碼的 Skills):
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.這個範例展示了工作流程如何應用於不需要程式碼的分析任務。檢查清單模式適用於任何複雜的多步驟流程。
範例 2:PDF 表單填寫工作流程(適用於含程式碼的 Skills):
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
```
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
```
**Step 1: Analyze the form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create field mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify output**
Run: `python scripts/verify_output.py output.pdf`
If verification fails, return to Step 2.清晰的步驟可以防止 Claude 跳過關鍵的驗證。檢查清單幫助 Claude 和您追蹤多步驟工作流程的進度。
常見模式: 執行驗證器 → 修復錯誤 → 重複
這種模式大大提高了輸出品質。
範例 1:風格指南合規性(適用於不含程式碼的 Skills):
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the document這展示了使用參考文件而非腳本的驗證循環模式。「驗證器」是 STYLE_GUIDE.md,Claude 透過閱讀和比較來執行檢查。
範例 2:文件編輯流程(適用於含程式碼的 Skills):
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test the output document驗證循環可以及早發現錯誤。
不要包含會過時的資訊:
壞的範例:時效性(將會變得錯誤):
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.好的範例(使用「舊模式」章節):
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>舊模式章節提供歷史背景,而不會使主要內容雜亂。
選擇一個術語並在整個 Skill 中使用它:
好 - 一致:
壞 - 不一致:
一致性幫助 Claude 理解和遵循指示。
為輸出格式提供範本。將嚴格程度與您的需求相匹配。
對於嚴格的要求(如 API 回應或數據格式):
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```對於靈活的指引(當調整有用時):
## Report structure
Here is a sensible default format, but use your best judgment based on the analysis:
```markdown
# [Analysis Title]
## Executive summary
[Overview]
## Key findings
[Adapt sections based on what you discover]
## Recommendations
[Tailor to the specific context]
```
Adjust sections as needed for the specific analysis type.對於輸出品質取決於看到範例的 Skills,就像在常規提示中一樣提供輸入/輸出配對:
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
**Example 3:**
Input: Updated dependencies and refactored error handling
Output:
```
chore: update dependencies and refactor error handling
- Upgrade lodash to 4.17.21
- Standardize error response format across endpoints
```
Follow this style: type(scope): brief description, then detailed explanation.範例比單純的描述更能幫助 Claude 清楚地理解所需的風格和細節程度。
引導 Claude 通過決策點:
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when complete如果工作流程變得龐大或複雜且包含許多步驟,請考慮將它們推送到單獨的檔案中,並告訴 Claude 根據手頭的任務讀取適當的檔案。
在撰寫大量文件之前先建立評估。 這確保您的 Skill 解決真實的問題,而不是記錄想像中的問題。
評估驅動的開發:
這種方法確保您解決的是實際問題,而不是預測可能永遠不會出現的需求。
評估結構:
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF file and save it to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file using an appropriate PDF processing library or command-line tool",
"Extracts text content from all pages in the document without missing any pages",
"Saves the extracted text to a file named output.txt in a clear, readable format"
]
}這個範例展示了一個帶有簡單測試評分標準的數據驅動評估。目前沒有內建的方式來執行這些評估。使用者可以建立自己的評估系統。評估是您衡量 Skill 有效性的真實來源。
最有效的 Skill 開發流程涉及 Claude 本身。與一個 Claude 實例(「Claude A」)合作建立一個由其他實例(「Claude B」)使用的 Skill。Claude A 幫助您設計和改進指示,而 Claude B 在真實任務中測試它們。這之所以有效,是因為 Claude 模型既理解如何撰寫有效的代理指示,也理解代理需要什麼資訊。
建立新的 Skill:
在沒有 Skill 的情況下完成任務: 使用正常提示與 Claude A 一起解決問題。在工作過程中,您會自然地提供上下文、解釋偏好並分享程序性知識。注意您重複提供的資訊。
識別可重複使用的模式: 完成任務後,識別您提供的哪些上下文對類似的未來任務有用。
範例: 如果您完成了一個 BigQuery 分析,您可能提供了資料表名稱、欄位定義、過濾規則(如「始終排除測試帳戶」)和常見的查詢模式。
要求 Claude A 建立 Skill:「建立一個 Skill 來捕捉我們剛剛使用的這個 BigQuery 分析模式。包括資料表架構、命名慣例和過濾測試帳戶的規則。」
Claude 模型原生理解 Skill 的格式和結構。您不需要特殊的系統提示或「撰寫 skills」的 skill 來讓 Claude 幫助建立 Skills。只需要求 Claude 建立一個 Skill,它就會生成結構正確的 SKILL.md 內容,包含適當的 frontmatter 和正文內容。
審查簡潔性: 檢查 Claude A 是否添加了不必要的解釋。詢問:「移除關於勝率含義的解釋 - Claude 已經知道了。」
改進資訊架構: 要求 Claude A 更有效地組織內容。例如:「組織這個內容,讓資料表架構放在單獨的參考檔案中。我們以後可能會添加更多資料表。」
在類似任務上測試: 在相關的使用案例上與 Claude B(載入了 Skill 的全新實例)一起使用該 Skill。觀察 Claude B 是否找到正確的資訊、正確應用規則並成功處理任務。
根據觀察進行迭代: 如果 Claude B 遇到困難或遺漏了某些內容,帶著具體細節回到 Claude A:「當 Claude 使用這個 Skill 時,它忘記了按 Q4 的日期進行過濾。我們應該添加一個關於日期過濾模式的章節嗎?」
迭代現有的 Skills:
改進 Skills 時,同樣的階層模式會持續。您在以下之間交替:
在真實工作流程中使用 Skill: 給 Claude B(載入了 Skill)實際的任務,而不是測試情境
觀察 Claude B 的行為: 注意它在哪裡遇到困難、成功或做出意外的選擇
範例觀察:「當我要求 Claude B 提供區域銷售報告時,它寫了查詢但忘記過濾掉測試帳戶,即使 Skill 提到了這個規則。」
回到 Claude A 進行改進: 分享目前的 SKILL.md 並描述您觀察到的情況。詢問:「我注意到當我要求區域報告時,Claude B 忘記過濾測試帳戶。Skill 提到了過濾,但也許它不夠顯眼?」
審查 Claude A 的建議: Claude A 可能會建議重新組織以使規則更顯眼,使用更強烈的語言如「必須過濾」而不是「始終過濾」,或重組工作流程章節。
應用並測試變更: 使用 Claude A 的改進更新 Skill,然後在類似的請求上再次與 Claude B 測試
根據使用情況重複: 在遇到新情境時繼續這個觀察-改進-測試的循環。每次迭代都根據真實的代理行為而非假設來改進 Skill。
收集團隊回饋:
為什麼這種方法有效: Claude A 理解代理的需求,您提供領域專業知識,Claude B 透過真實使用揭示差距,而迭代改進根據觀察到的行為而非假設來改進 Skills。
在迭代 Skills 時,注意 Claude 在實踐中實際如何使用它們。留意:
根據這些觀察而非假設進行迭代。您 Skill 元數據中的「name」和「description」尤其關鍵。Claude 在決定是否針對目前任務觸發 Skill 時會使用它們。確保它們清楚地描述 Skill 的功能以及何時應該使用它。
始終在檔案路徑中使用正斜線,即使在 Windows 上也是如此:
scripts/helper.py、reference/guide.mdscripts\helper.py、reference\guide.mdUnix 風格的路徑適用於所有平台,而 Windows 風格的路徑會在 Unix 系統上導致錯誤。
除非必要,否則不要呈現多種方法:
**Bad example: Too many choices** (confusing):
"You can use pypdf, or pdfplumber, or PyMuPDF, or pdf2image, or..."
**Good example: Provide a default** (with escape hatch):
"Use pdfplumber for text extraction:
```python
import pdfplumber
```
For scanned PDFs requiring OCR, use pdf2image with pytesseract instead."以下章節專注於包含可執行腳本的 Skills。如果您的 Skill 只使用 markdown 指示,請跳到有效 Skills 的檢查清單。
為 Skills 撰寫腳本時,要處理錯誤情況,而不是推給 Claude。
好的範例:明確處理錯誤:
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# 建立含預設內容的檔案,而非直接失敗
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# 提供替代方案,而非直接失敗
print(f"Cannot access {path}, using default")
return ""壞的範例:推給 Claude:
def process_file(path):
# 直接讓它失敗,交給 Claude 自行解決
return open(path).read()配置參數也應該有正當理由並記錄在案,以避免「巫毒常數」(Ousterhout 定律)。如果您不知道正確的值,Claude 要如何確定它?
好的範例:自我記錄:
# HTTP 請求通常在 30 秒內完成
# 較長的逾時時間可因應緩慢的連線
REQUEST_TIMEOUT = 30
# 重試三次可在可靠性與速度之間取得平衡
# 大多數間歇性失敗在第二次重試時即可解決
MAX_RETRIES = 3壞的範例:魔術數字:
TIMEOUT = 47 # Why 47?
RETRIES = 5 # Why 5?即使 Claude 可以撰寫腳本,預先製作的腳本也有優勢:
實用腳本的好處:

上圖顯示了可執行腳本如何與指示檔案一起運作。指示檔案(forms.md)引用腳本,Claude 可以執行它而無需將其內容載入到上下文中。
重要區別: 在您的指示中明確說明 Claude 應該:
analyze_form.py 來提取欄位」analyze_form.py 了解欄位提取演算法」對於大多數實用腳本,執行是首選,因為它更可靠且更高效。有關腳本執行如何運作的詳細資訊,請參閱下面的執行環境章節。
範例:
## Utility scripts
**analyze_form.py**: Extract all form fields from PDF
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
Output format:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**: Check for overlapping bounding boxes
```bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
```
**fill_form.py**: Apply field values to PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```當輸入可以渲染為圖像時,讓 Claude 分析它們:
## Form layout analysis
1. Convert PDF to images:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. Analyze each page image to identify form fields
3. Claude can see field locations and types visually在這個範例中,您需要撰寫 pdf_to_images.py 腳本。
Claude 的視覺能力有助於理解版面配置和結構。
當 Claude 執行複雜、開放式的任務時,它可能會犯錯。「計劃-驗證-執行」模式透過讓 Claude 先以結構化格式建立計劃,然後在執行之前用腳本驗證該計劃,來及早發現錯誤。
範例: 想像要求 Claude 根據試算表更新 PDF 中的 50 個表單欄位。如果沒有驗證,Claude 可能會引用不存在的欄位、建立衝突的值、遺漏必填欄位或錯誤地應用更新。
解決方案: 使用上面顯示的工作流程模式(PDF 表單填寫),但添加一個中間的 changes.json 檔案,在應用變更之前進行驗證。工作流程變成:分析 → 建立計劃檔案 → 驗證計劃 → 執行 → 驗證。
為什麼這種模式有效:
何時使用: 批次操作、破壞性變更、複雜的驗證規則、高風險操作。
實作提示: 讓驗證腳本提供詳細且具體的錯誤訊息,例如「找不到欄位 'signature_date'。可用欄位:customer_name、order_total、signature_date_signed」,以幫助 Claude 修復問題。
Skills 在程式碼執行環境中運行,具有平台特定的限制:
在您的 SKILL.md 中列出所需的套件,並在程式碼執行工具文件中驗證它們是否可用。
Skills 在具有檔案系統存取、bash 命令和程式碼執行能力的程式碼執行環境中運行。有關此架構的概念說明,請參閱概覽中的 Skills 架構。
這如何影響您的撰寫:
Claude 如何存取 Skills:
reference/guide.md),而不是反斜線form_validation_rules.md,而不是 doc2.mdreference/finance.md、reference/sales.mddocs/file1.md、docs/file2.mdvalidate_form.py,而不是要求 Claude 生成驗證程式碼analyze_form.py 來提取欄位」(執行)analyze_form.py 了解提取演算法」(作為參考閱讀)範例:
bigquery-skill/
├── SKILL.md (overview, points to reference files)
└── reference/
├── finance.md (revenue metrics)
├── sales.md (pipeline data)
└── product.md (usage analytics)當使用者詢問營收時,Claude 讀取 SKILL.md,看到對 reference/finance.md 的引用,並呼叫 bash 只讀取該檔案。sales.md 和 product.md 檔案保留在檔案系統上,在需要之前消耗零上下文 tokens。這種基於檔案系統的模型正是實現漸進式揭露的關鍵。Claude 可以導航並選擇性地載入每個任務所需的確切內容。
有關技術架構的完整詳細資訊,請參閱 Skills 概覽中的 Skills 如何運作。
如果您的 Skill 使用 MCP(Model Context Protocol)工具,請始終使用完全限定的工具名稱,以避免「找不到工具」的錯誤。
格式: ServerName:tool_name
範例:
Use the BigQuery:bigquery_schema tool to retrieve table schemas.
Use the GitHub:create_issue tool to create issues.其中:
BigQuery 和 GitHub 是 MCP 伺服器名稱bigquery_schema 和 create_issue 是這些伺服器中的工具名稱如果沒有伺服器前綴,Claude 可能無法找到工具,尤其是當有多個 MCP 伺服器可用時。
不要假設套件可用:
**Bad example: Assumes installation**:
"Use the pdf library to process the file."
**Good example: Explicit about dependencies**:
"Install required package: `pip install pypdf`
Then use it:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"SKILL.md 的 frontmatter 需要 name 和 description 欄位,並有特定的驗證規則:
name:最多 64 個字元,只能使用小寫字母/數字/連字號,不能有 XML 標籤,不能有保留字description:最多 1024 個字元,非空,不能有 XML 標籤有關完整的結構詳細資訊,請參閱 Skills 概覽。
將 SKILL.md 正文保持在 500 行以下以獲得最佳效能。如果您的內容超過此限制,請使用前面描述的漸進式揭露模式將其拆分為單獨的檔案。有關架構詳細資訊,請參閱 Skills 概覽。
在分享 Skill 之前,請驗證:
建立您的第一個 Skill
在 Claude Code 中建立和管理 Skills
以程式化方式上傳和使用 Skills
Was this page helpful?