Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Was this page helpful?
在定義成功標準之後,下一步是設計評估來衡量 LLM 相對於這些標準的表現。這是提示工程循環中至關重要的一部分。
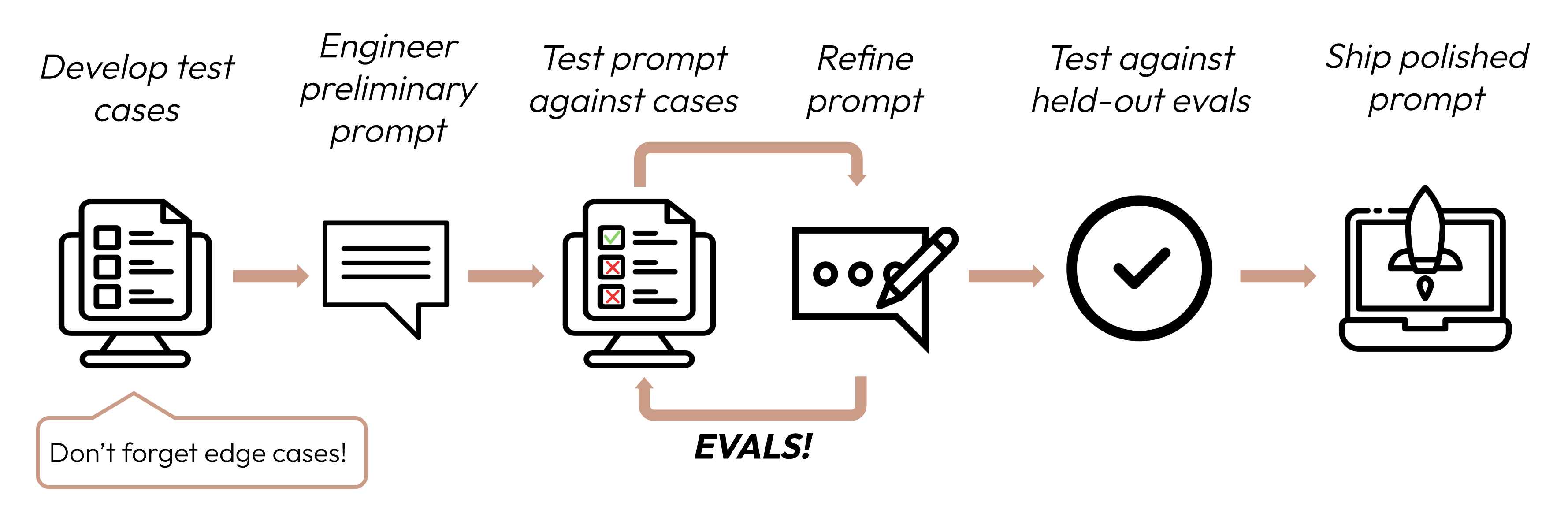
本指南著重於如何開發您的測試案例。
在決定使用哪種方法對評估進行評分時,選擇最快、最可靠、最具擴展性的方法:
基於程式碼的評分:最快且最可靠,極具擴展性,但對於需要較少基於規則的嚴格性的更複雜判斷缺乏細微差別。
output == golden_answerkey_phrase in output人工評分:最靈活且品質最高,但速度慢且成本高。盡可能避免使用。
基於 LLM 的評分:快速且靈活,具擴展性且適合複雜判斷。先測試以確保可靠性,然後再擴展規模。
更多人工、程式碼和 LLM 評分評估的程式碼範例。