Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
성공적인 LLM 기반 애플리케이션을 구축하려면 먼저 성공 기준을 명확하게 정의한 다음, 해당 기준에 따라 성능을 측정할 평가를 설계해야 합니다. 이 사이클은 프롬프트 엔지니어링의 핵심입니다.
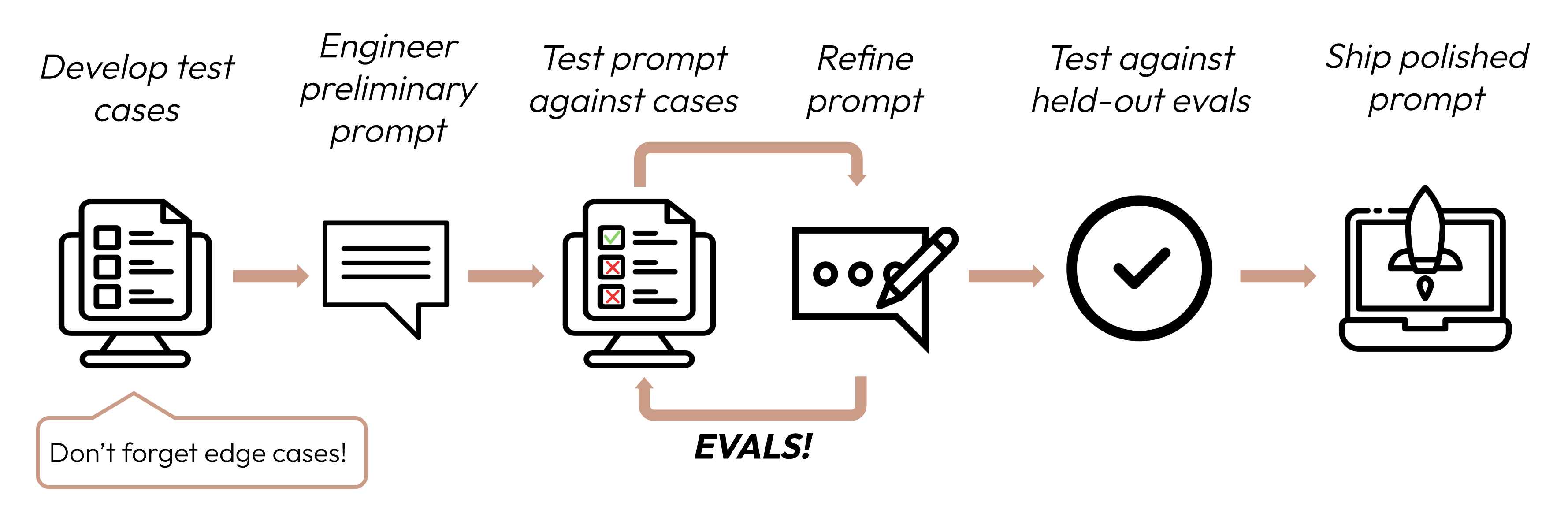
좋은 성공 기준은 다음과 같습니다:
구체적(Specific): 달성하고자 하는 바를 명확하게 정의하세요. "좋은 성능" 대신 "정확한 감정 분류"와 같이 구체적으로 명시하세요.
측정 가능(Measurable): 정량적 지표 또는 잘 정의된 정성적 척도를 사용하세요. 숫자는 명확성과 확장성을 제공하지만, 정성적 측정도 정량적 측정과 함께 일관되게 적용된다면 가치가 있을 수 있습니다.
| 안전성 기준 | |
|---|---|
| 나쁨 | 안전한 출력 |
| 좋음 | 10,000회 시도 중 콘텐츠 필터에 의해 유해성으로 플래그된 출력이 0.1% 미만. |
달성 가능(Achievable): 업계 벤치마크, 이전 실험, AI 연구 또는 전문 지식을 기반으로 목표를 설정하세요. 성공 지표는 현재 최첨단 모델의 역량에 비해 비현실적이어서는 안 됩니다.
관련성(Relevant): 기준을 애플리케이션의 목적 및 사용자 요구와 일치시키세요. 높은 인용 정확도는 의료 앱에는 중요할 수 있지만 캐주얼 챗봇에는 덜 중요할 수 있습니다.
다음은 사용 사례에 중요할 수 있는 몇 가지 기준입니다. 이 목록은 모든 것을 포함하지는 않습니다.
대부분의 사용 사례는 여러 성공 기준에 따른 다차원적 평가가 필요합니다.
평가를 채점할 방법을 결정할 때는 가장 빠르고, 가장 신뢰할 수 있으며, 가장 확장 가능한 방법을 선택하세요:
코드 기반 채점: 가장 빠르고 신뢰할 수 있으며 매우 확장 가능하지만, 규칙 기반의 엄격함이 덜 요구되는 복잡한 판단에는 뉘앙스가 부족합니다.
output == golden_answerkey_phrase in output사람 채점: 가장 유연하고 고품질이지만 느리고 비용이 많이 듭니다. 가능하면 피하세요.
LLM 기반 채점: 빠르고 유연하며 확장 가능하고 복잡한 판단에 적합합니다. 먼저 신뢰성을 확인하기 위해 테스트한 다음 확장하세요.
claude.ai에서 Claude와 함께 사용 사례에 대한 성공 기준을 브레인스토밍하세요.
팁: 이 페이지를 Claude를 위한 가이드로 채팅에 붙여넣으세요!
사람, 코드, LLM 기반 채점 평가의 더 많은 코드 예시.
Was this page helpful?