Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
좋은 Skill은 간결하고, 잘 구조화되어 있으며, 실제 사용을 통해 테스트됩니다. 이 가이드는 Claude가 효과적으로 발견하고 사용할 수 있는 Skill을 작성하는 데 도움이 되는 실용적인 작성 결정 사항을 제공합니다.
Skill이 작동하는 방식에 대한 개념적 배경은 Skill 개요를 참조하세요.
컨텍스트 윈도우는 공공재입니다. 여러분의 Skill은 Claude가 알아야 하는 다른 모든 것과 컨텍스트 윈도우를 공유합니다. 여기에는 다음이 포함됩니다:
Skill의 모든 토큰이 즉각적인 비용을 발생시키는 것은 아닙니다. 시작 시에는 모든 Skill의 메타데이터(name 및 description)만 미리 로드됩니다. Claude는 Skill이 관련성을 갖게 될 때만 SKILL.md를 읽고, 필요할 때만 추가 파일을 읽습니다. 그러나 SKILL.md에서 간결함을 유지하는 것은 여전히 중요합니다. Claude가 이를 로드하면 모든 토큰이 대화 기록 및 기타 컨텍스트와 경쟁하기 때문입니다.
기본 가정: Claude는 이미 매우 똑똑합니다
Claude가 아직 가지고 있지 않은 컨텍스트만 추가하세요. 각 정보에 대해 다음과 같이 질문해 보세요:
좋은 예: 간결함 (약 50 토큰):
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```나쁜 예: 너무 장황함 (약 150 토큰):
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but
pdfplumber is recommended because it's easy to use and handles most cases well.
First, you'll need to install it using pip. Then you can use the code below...간결한 버전은 Claude가 PDF가 무엇인지, 라이브러리가 어떻게 작동하는지 알고 있다고 가정합니다.
구체성의 수준을 작업의 취약성과 가변성에 맞추세요.
높은 자유도 (텍스트 기반 지침):
다음과 같은 경우에 사용하세요:
예시:
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventions중간 자유도 (의사 코드 또는 매개변수가 있는 스크립트):
다음과 같은 경우에 사용하세요:
예시:
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```낮은 자유도 (특정 스크립트, 매개변수가 거의 없거나 없음):
다음과 같은 경우에 사용하세요:
예시:
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.비유: Claude를 경로를 탐색하는 로봇이라고 생각해 보세요:
Skill은 모델에 대한 추가 기능으로 작동하므로 효과는 기본 모델에 따라 달라집니다. 사용하려는 모든 모델로 Skill을 테스트하세요.
모델별 테스트 고려 사항:
Opus에서 완벽하게 작동하는 것이 Haiku에서는 더 많은 세부 정보가 필요할 수 있습니다. 여러 모델에서 Skill을 사용할 계획이라면 모든 모델에서 잘 작동하는 지침을 목표로 하세요.
YAML Frontmatter: SKILL.md frontmatter에는 두 개의 필드가 필요합니다:
name:
description:
전체 Skill 구조 세부 정보는 Skill 개요를 참조하세요.
Skill을 참조하고 논의하기 쉽도록 일관된 명명 패턴을 사용하세요. Skill 이름에는 동명사 형태(동사 + -ing)를 사용하는 것을 고려하세요. 이는 Skill이 제공하는 활동이나 기능을 명확하게 설명합니다.
name 필드는 소문자, 숫자, 하이픈만 사용해야 한다는 점을 기억하세요.
좋은 명명 예시 (동명사 형태):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation허용 가능한 대안:
pdf-processing, spreadsheet-analysisprocess-pdfs, analyze-spreadsheets피해야 할 것:
helper, utils, toolsdocuments, data, filesanthropic-helper, claude-tools일관된 명명은 다음을 더 쉽게 만듭니다:
description 필드는 Skill 발견을 가능하게 하며, Skill이 무엇을 하는지와 언제 사용하는지를 모두 포함해야 합니다.
항상 3인칭으로 작성하세요. description은 시스템 프롬프트에 주입되며, 일관되지 않은 시점은 발견 문제를 일으킬 수 있습니다.
구체적으로 작성하고 핵심 용어를 포함하세요. Skill이 무엇을 하는지와 언제 사용하는지에 대한 구체적인 트리거/컨텍스트를 모두 포함하세요.
각 Skill에는 정확히 하나의 description 필드가 있습니다. description은 Skill 선택에 매우 중요합니다. Claude는 이를 사용하여 잠재적으로 100개 이상의 사용 가능한 Skill 중에서 올바른 Skill을 선택합니다. description은 Claude가 이 Skill을 언제 선택해야 하는지 알 수 있도록 충분한 세부 정보를 제공해야 하며, SKILL.md의 나머지 부분은 구현 세부 정보를 제공합니다.
효과적인 예시:
PDF 처리 Skill:
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.Excel 분석 Skill:
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.Git 커밋 도우미 Skill:
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.다음과 같은 모호한 description은 피하세요:
description: Helps with documentsdescription: Processes datadescription: Does stuff with filesSKILL.md는 온보딩 가이드의 목차처럼 필요에 따라 Claude를 상세 자료로 안내하는 개요 역할을 합니다. 점진적 공개가 작동하는 방식에 대한 설명은 개요의 Skill 작동 방식을 참조하세요.
실용적인 지침:
기본 Skill은 메타데이터와 지침이 포함된 SKILL.md 파일 하나로 시작합니다:
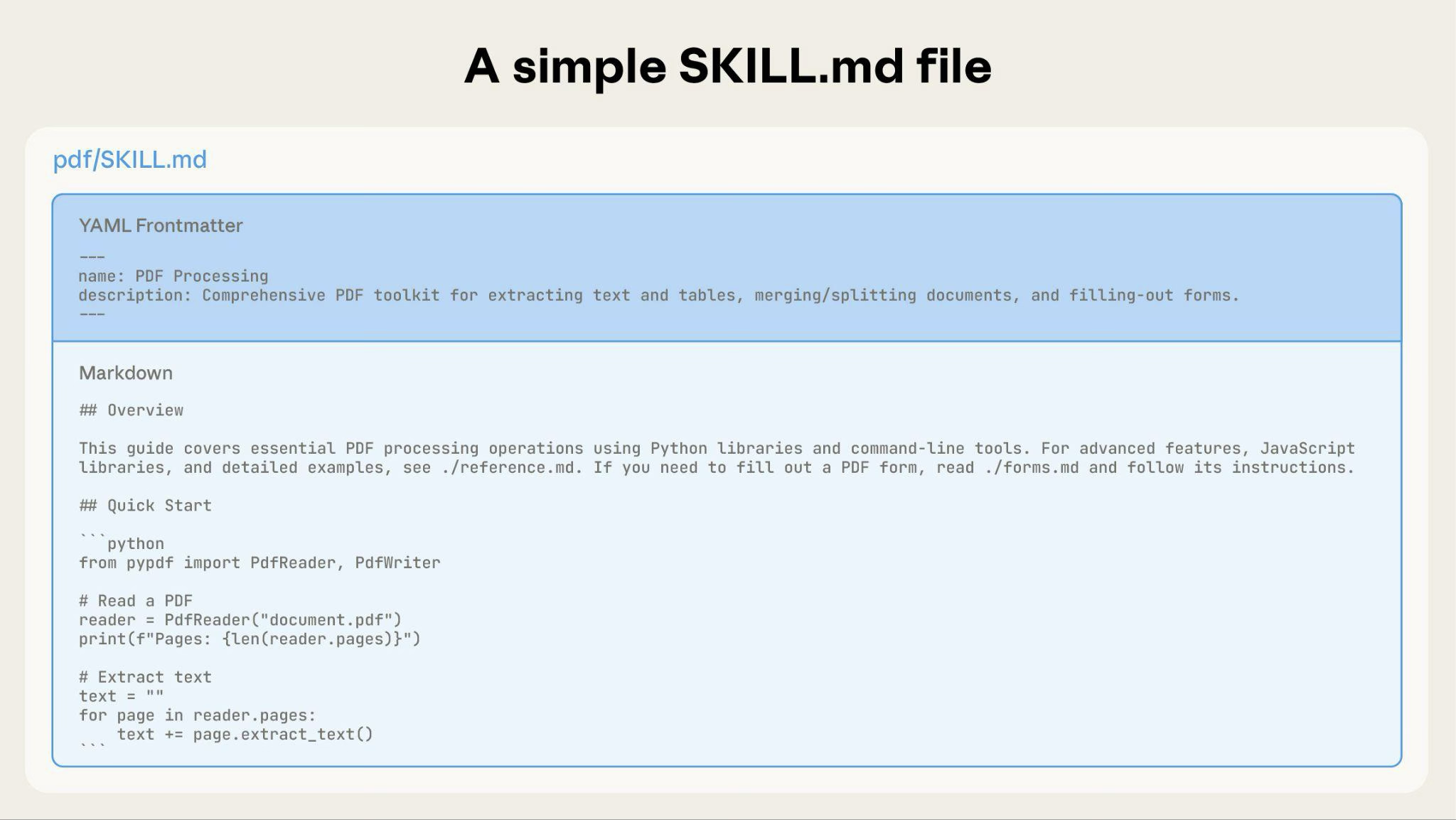
Skill이 성장함에 따라 Claude가 필요할 때만 로드하는 추가 콘텐츠를 번들로 묶을 수 있습니다:

전체 Skill 디렉터리 구조는 다음과 같을 수 있습니다:
pdf/
├── SKILL.md # Main instructions (loaded when triggered)
├── FORMS.md # Form-filling guide (loaded as needed)
├── reference.md # API reference (loaded as needed)
├── examples.md # Usage examples (loaded as needed)
└── scripts/
├── analyze_form.py # Utility script (executed, not loaded)
├── fill_form.py # Form filling script
└── validate.py # Validation script---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patternsClaude는 필요할 때만 FORMS.md, REFERENCE.md 또는 EXAMPLES.md를 로드합니다.
여러 도메인이 있는 Skill의 경우, 관련 없는 컨텍스트를 로드하지 않도록 도메인별로 콘텐츠를 구성하세요. 사용자가 영업 지표에 대해 질문할 때 Claude는 재무나 마케팅 데이터가 아닌 영업 관련 스키마만 읽으면 됩니다. 이렇게 하면 토큰 사용량이 낮게 유지되고 컨텍스트가 집중됩니다.
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)# BigQuery Data Analysis
## Available datasets
**Finance**: Revenue, ARR, billing → See [reference/finance.md](reference/finance.md)
**Sales**: Opportunities, pipeline, accounts → See [reference/sales.md](reference/sales.md)
**Product**: API usage, features, adoption → See [reference/product.md](reference/product.md)
**Marketing**: Campaigns, attribution, email → See [reference/marketing.md](reference/marketing.md)
## Quick search
Find specific metrics using grep:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```기본 콘텐츠를 표시하고 고급 콘텐츠로 링크하세요:
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)Claude는 사용자가 해당 기능이 필요할 때만 REDLINING.md 또는 OOXML.md를 읽습니다.
Claude는 다른 참조 파일에서 참조된 파일을 부분적으로 읽을 수 있습니다. 중첩된 참조를 만나면 Claude는 전체 파일을 읽는 대신 head -100과 같은 명령을 사용하여 콘텐츠를 미리 볼 수 있으며, 이로 인해 불완전한 정보가 발생할 수 있습니다.
참조는 SKILL.md에서 한 단계 깊이로 유지하세요. 모든 참조 파일은 SKILL.md에서 직접 링크되어야 Claude가 필요할 때 전체 파일을 읽을 수 있습니다.
나쁜 예: 너무 깊음:
# SKILL.md
See [advanced.md](advanced.md)...
# advanced.md
See [details.md](details.md)...
# details.md
Here's the actual information...좋은 예: 한 단계 깊이:
# SKILL.md
**Basic usage**: [instructions in SKILL.md]
**Advanced features**: See [advanced.md](advanced.md)
**API reference**: See [reference.md](reference.md)
**Examples**: See [examples.md](examples.md)100줄보다 긴 참조 파일의 경우 상단에 목차를 포함하세요. 이렇게 하면 Claude가 부분 읽기로 미리 볼 때도 사용 가능한 정보의 전체 범위를 볼 수 있습니다.
예시:
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
## Authentication and setup
...
## Core methods
...그러면 Claude는 필요에 따라 전체 파일을 읽거나 특정 섹션으로 이동할 수 있습니다.
이 파일 시스템 기반 아키텍처가 점진적 공개를 가능하게 하는 방법에 대한 자세한 내용은 아래 고급 섹션의 런타임 환경 섹션을 참조하세요.
복잡한 작업을 명확하고 순차적인 단계로 나누세요. 특히 복잡한 워크플로의 경우, Claude가 응답에 복사하여 진행하면서 체크할 수 있는 체크리스트를 제공하세요.
예시 1: 연구 종합 워크플로 (코드가 없는 Skill용):
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.이 예시는 코드가 필요하지 않은 분석 작업에 워크플로가 어떻게 적용되는지 보여줍니다. 체크리스트 패턴은 복잡한 다단계 프로세스에 모두 적용됩니다.
예시 2: PDF 양식 작성 워크플로 (코드가 있는 Skill용):
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
```
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
```
**Step 1: Analyze the form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create field mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify output**
Run: `python scripts/verify_output.py output.pdf`
If verification fails, return to Step 2.명확한 단계는 Claude가 중요한 검증을 건너뛰는 것을 방지합니다. 체크리스트는 Claude와 여러분 모두가 다단계 워크플로의 진행 상황을 추적하는 데 도움이 됩니다.
일반적인 패턴: 검증기 실행 → 오류 수정 → 반복
이 패턴은 출력 품질을 크게 향상시킵니다.
예시 1: 스타일 가이드 준수 (코드가 없는 Skill용):
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the document이는 스크립트 대신 참조 문서를 사용하는 검증 루프 패턴을 보여줍니다. "검증기"는 STYLE_GUIDE.md이며, Claude는 읽고 비교하여 확인을 수행합니다.
예시 2: 문서 편집 프로세스 (코드가 있는 Skill용):
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test the output document검증 루프는 오류를 조기에 포착합니다.
오래될 정보는 포함하지 마세요:
나쁜 예: 시간에 민감함 (잘못된 정보가 될 것임):
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.좋은 예 ("이전 패턴" 섹션 사용):
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>이전 패턴 섹션은 주요 콘텐츠를 어지럽히지 않고 역사적 컨텍스트를 제공합니다.
하나의 용어를 선택하고 Skill 전체에서 사용하세요:
좋음 - 일관됨:
나쁨 - 일관되지 않음:
일관성은 Claude가 지침을 이해하고 따르는 데 도움이 됩니다.
출력 형식에 대한 템플릿을 제공하세요. 엄격함의 수준을 필요에 맞추세요.
엄격한 요구 사항의 경우 (API 응답 또는 데이터 형식과 같은):
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```유연한 지침의 경우 (적응이 유용할 때):
## Report structure
Here is a sensible default format, but use your best judgment based on the analysis:
```markdown
# [Analysis Title]
## Executive summary
[Overview]
## Key findings
[Adapt sections based on what you discover]
## Recommendations
[Tailor to the specific context]
```
Adjust sections as needed for the specific analysis type.출력 품질이 예시를 보는 것에 의존하는 Skill의 경우, 일반 프롬프팅과 마찬가지로 입력/출력 쌍을 제공하세요:
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
**Example 3:**
Input: Updated dependencies and refactored error handling
Output:
```
chore: update dependencies and refactor error handling
- Upgrade lodash to 4.17.21
- Standardize error response format across endpoints
```
Follow this style: type(scope): brief description, then detailed explanation.예시는 설명만으로는 전달하기 어려운 원하는 스타일과 세부 수준을 Claude가 더 명확하게 이해하는 데 도움이 됩니다.
의사 결정 지점을 통해 Claude를 안내하세요:
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when complete워크플로가 많은 단계로 커지거나 복잡해지면 별도의 파일로 분리하고 Claude에게 현재 작업에 따라 적절한 파일을 읽도록 지시하는 것을 고려하세요.
광범위한 문서를 작성하기 전에 평가를 만드세요. 이렇게 하면 Skill이 상상한 문제가 아닌 실제 문제를 해결하도록 보장합니다.
평가 주도 개발:
이 접근 방식은 실현되지 않을 수도 있는 요구 사항을 예상하는 대신 실제 문제를 해결하도록 보장합니다.
평가 구조:
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF file and save it to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file using an appropriate PDF processing library or command-line tool",
"Extracts text content from all pages in the document without missing any pages",
"Saves the extracted text to a file named output.txt in a clear, readable format"
]
}이 예시는 간단한 테스트 루브릭을 사용한 데이터 기반 평가를 보여줍니다. 현재 이러한 평가를 실행하는 내장 방법은 없습니다. 사용자는 자체 평가 시스템을 만들 수 있습니다. 평가는 Skill 효과를 측정하기 위한 진실의 원천입니다.
가장 효과적인 Skill 개발 프로세스는 Claude 자체를 포함합니다. 하나의 Claude 인스턴스("Claude A")와 협력하여 다른 인스턴스("Claude B")가 사용하는 Skill을 만드세요. Claude A는 지침을 설계하고 개선하는 데 도움을 주고, Claude B는 실제 작업에서 이를 테스트합니다. 이것이 작동하는 이유는 Claude 모델이 효과적인 에이전트 지침을 작성하는 방법과 에이전트가 필요로 하는 정보를 모두 이해하기 때문입니다.
새 Skill 만들기:
Skill 없이 작업 완료하기: 일반 프롬프팅을 사용하여 Claude A와 함께 문제를 해결하세요. 작업하면서 자연스럽게 컨텍스트를 제공하고, 선호 사항을 설명하고, 절차적 지식을 공유하게 됩니다. 반복적으로 제공하는 정보가 무엇인지 주목하세요.
재사용 가능한 패턴 식별하기: 작업을 완료한 후, 유사한 향후 작업에 유용할 컨텍스트가 무엇인지 식별하세요.
예시: BigQuery 분석을 진행했다면 테이블 이름, 필드 정의, 필터링 규칙(예: "항상 테스트 계정 제외"), 일반적인 쿼리 패턴을 제공했을 수 있습니다.
Claude A에게 Skill 생성 요청하기: "방금 사용한 이 BigQuery 분석 패턴을 캡처하는 Skill을 만들어 주세요. 테이블 스키마, 명명 규칙, 테스트 계정 필터링에 대한 규칙을 포함하세요."
Claude 모델은 Skill 형식과 구조를 기본적으로 이해합니다. Claude가 Skill 생성을 돕도록 하기 위해 특별한 시스템 프롬프트나 "Skill 작성" Skill이 필요하지 않습니다. 단순히 Claude에게 Skill을 만들어 달라고 요청하면 적절한 frontmatter와 본문 콘텐츠가 포함된 올바르게 구조화된 SKILL.md 콘텐츠를 생성합니다.
간결성 검토하기: Claude A가 불필요한 설명을 추가하지 않았는지 확인하세요. 다음과 같이 요청하세요: "승률이 무엇을 의미하는지에 대한 설명을 제거하세요 - Claude는 이미 그것을 알고 있습니다."
정보 아키텍처 개선하기: Claude A에게 콘텐츠를 더 효과적으로 구성하도록 요청하세요. 예를 들어: "테이블 스키마가 별도의 참조 파일에 있도록 구성하세요. 나중에 더 많은 테이블을 추가할 수 있습니다."
유사한 작업에서 테스트하기: 관련 사용 사례에서 Claude B(Skill이 로드된 새 인스턴스)와 함께 Skill을 사용하세요. Claude B가 올바른 정보를 찾고, 규칙을 올바르게 적용하고, 작업을 성공적으로 처리하는지 관찰하세요.
관찰을 기반으로 반복하기: Claude B가 어려움을 겪거나 무언가를 놓치면 구체적인 내용과 함께 Claude A로 돌아가세요: "Claude가 이 Skill을 사용했을 때 Q4에 대한 날짜 필터링을 잊었습니다. 날짜 필터링 패턴에 대한 섹션을 추가해야 할까요?"
기존 Skill 반복하기:
Skill을 개선할 때도 동일한 계층적 패턴이 계속됩니다. 다음을 번갈아 수행합니다:
실제 워크플로에서 Skill 사용하기: Claude B(Skill이 로드된)에게 테스트 시나리오가 아닌 실제 작업을 제공하세요
Claude B의 동작 관찰하기: 어려움을 겪거나, 성공하거나, 예상치 못한 선택을 하는 부분을 기록하세요
관찰 예시: "Claude B에게 지역별 영업 보고서를 요청했을 때, Skill에서 이 규칙을 언급했음에도 불구하고 쿼리를 작성했지만 테스트 계정을 필터링하는 것을 잊었습니다."
개선을 위해 Claude A로 돌아가기: 현재 SKILL.md를 공유하고 관찰한 내용을 설명하세요. 다음과 같이 질문하세요: "지역 보고서를 요청했을 때 Claude B가 테스트 계정 필터링을 잊었다는 것을 알았습니다. Skill에서 필터링을 언급하지만, 충분히 눈에 띄지 않는 것 같습니다."
Claude A의 제안 검토하기: Claude A는 규칙을 더 눈에 띄게 만들기 위해 재구성하거나, "always filter" 대신 "MUST filter"와 같은 더 강한 언어를 사용하거나, 워크플로 섹션을 재구성하는 것을 제안할 수 있습니다.
변경 사항 적용 및 테스트하기: Claude A의 개선 사항으로 Skill을 업데이트한 다음 유사한 요청에서 Claude B로 다시 테스트하세요
사용을 기반으로 반복하기: 새로운 시나리오를 만날 때마다 이 관찰-개선-테스트 주기를 계속하세요. 각 반복은 가정이 아닌 실제 에이전트 동작을 기반으로 Skill을 개선합니다.
팀 피드백 수집하기:
이 접근 방식이 작동하는 이유: Claude A는 에이전트의 요구 사항을 이해하고, 여러분은 도메인 전문 지식을 제공하며, Claude B는 실제 사용을 통해 격차를 드러내고, 반복적인 개선은 가정이 아닌 관찰된 동작을 기반으로 Skill을 개선합니다.
Skill을 반복하면서 Claude가 실제로 어떻게 사용하는지 주의 깊게 살펴보세요. 다음을 확인하세요:
가정이 아닌 이러한 관찰을 기반으로 반복하세요. Skill 메타데이터의 'name'과 'description'은 특히 중요합니다. Claude는 현재 작업에 대한 응답으로 Skill을 트리거할지 결정할 때 이를 사용합니다. Skill이 무엇을 하는지와 언제 사용해야 하는지를 명확하게 설명하는지 확인하세요.
Windows에서도 파일 경로에는 항상 슬래시를 사용하세요:
scripts/helper.py, reference/guide.mdscripts\helper.py, reference\guide.mdUnix 스타일 경로는 모든 플랫폼에서 작동하지만, Windows 스타일 경로는 Unix 시스템에서 오류를 발생시킵니다.
필요하지 않은 한 여러 접근 방식을 제시하지 마세요:
**Bad example: Too many choices** (confusing):
"You can use pypdf, or pdfplumber, or PyMuPDF, or pdf2image, or..."
**Good example: Provide a default** (with escape hatch):
"Use pdfplumber for text extraction:
```python
import pdfplumber
```
For scanned PDFs requiring OCR, use pdf2image with pytesseract instead."아래 섹션은 실행 가능한 스크립트를 포함하는 Skill에 중점을 둡니다. Skill이 마크다운 지침만 사용하는 경우 효과적인 Skill을 위한 체크리스트로 건너뛰세요.
Skill용 스크립트를 작성할 때 오류 조건을 Claude에게 떠넘기지 말고 직접 처리하세요.
좋은 예: 오류를 명시적으로 처리:
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# 실패하는 대신 기본 콘텐츠로 파일 생성
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# 실패하는 대신 대안 제공
print(f"Cannot access {path}, using default")
return ""나쁜 예: Claude에게 떠넘기기:
def process_file(path):
# 그냥 실패시키고 Claude가 알아서 처리하도록 합니다
return open(path).read()구성 매개변수도 "부두 상수"(Ousterhout의 법칙)를 피하기 위해 정당화되고 문서화되어야 합니다. 올바른 값을 모른다면 Claude가 어떻게 결정할 수 있을까요?
좋은 예: 자체 문서화:
# HTTP 요청은 일반적으로 30초 이내에 완료됩니다
# 더 긴 타임아웃은 느린 연결을 고려한 것입니다
REQUEST_TIMEOUT = 30
# 세 번의 재시도는 안정성과 속도 간의 균형을 맞춥니다
# 대부분의 간헐적 실패는 두 번째 재시도에서 해결됩니다
MAX_RETRIES = 3나쁜 예: 매직 넘버:
TIMEOUT = 47 # Why 47?
RETRIES = 5 # Why 5?Claude가 스크립트를 작성할 수 있더라도 미리 만들어진 스크립트는 다음과 같은 이점을 제공합니다:
유틸리티 스크립트의 이점:

위 다이어그램은 실행 가능한 스크립트가 지침 파일과 함께 작동하는 방식을 보여줍니다. 지침 파일(forms.md)은 스크립트를 참조하며, Claude는 콘텐츠를 컨텍스트에 로드하지 않고 실행할 수 있습니다.
중요한 구분: 지침에서 Claude가 다음 중 무엇을 해야 하는지 명확히 하세요:
analyze_form.py를 실행하세요"analyze_form.py를 참조하세요"대부분의 유틸리티 스크립트의 경우 실행이 더 안정적이고 효율적이므로 선호됩니다. 스크립트 실행이 작동하는 방식에 대한 자세한 내용은 아래 런타임 환경 섹션을 참조하세요.
예시:
## Utility scripts
**analyze_form.py**: Extract all form fields from PDF
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
Output format:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**: Check for overlapping bounding boxes
```bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
```
**fill_form.py**: Apply field values to PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```입력을 이미지로 렌더링할 수 있는 경우 Claude가 분석하도록 하세요:
## Form layout analysis
1. Convert PDF to images:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. Analyze each page image to identify form fields
3. Claude can see field locations and types visually이 예시에서는 pdf_to_images.py 스크립트를 작성해야 합니다.
Claude의 비전 기능은 레이아웃과 구조를 이해하는 데 도움이 됩니다.
Claude가 복잡하고 개방형 작업을 수행할 때 실수를 할 수 있습니다. "계획-검증-실행" 패턴은 Claude가 먼저 구조화된 형식으로 계획을 만든 다음 실행하기 전에 스크립트로 해당 계획을 검증하도록 하여 오류를 조기에 포착합니다.
예시: 스프레드시트를 기반으로 PDF의 50개 양식 필드를 업데이트하도록 Claude에게 요청한다고 상상해 보세요. 검증 없이 Claude는 존재하지 않는 필드를 참조하거나, 충돌하는 값을 생성하거나, 필수 필드를 놓치거나, 업데이트를 잘못 적용할 수 있습니다.
해결책: 위에 표시된 워크플로 패턴(PDF 양식 작성)을 사용하되, 변경 사항을 적용하기 전에 검증되는 중간 changes.json 파일을 추가하세요. 워크플로는 다음과 같이 됩니다: 분석 → 계획 파일 생성 → 계획 검증 → 실행 → 확인.
이 패턴이 작동하는 이유:
사용 시기: 일괄 작업, 파괴적 변경, 복잡한 검증 규칙, 고위험 작업.
구현 팁: Claude가 문제를 해결하는 데 도움이 되도록 "Field 'signature_date' not found. Available fields: customer_name, order_total, signature_date_signed"와 같은 구체적인 오류 메시지로 검증 스크립트를 상세하게 만드세요.
Skill은 플랫폼별 제한이 있는 코드 실행 환경에서 실행됩니다:
SKILL.md에 필요한 패키지를 나열하고 코드 실행 도구 문서에서 사용 가능한지 확인하세요.
Skill은 파일 시스템 액세스, bash 명령 및 코드 실행 기능이 있는 코드 실행 환경에서 실행됩니다. 이 아키텍처에 대한 개념적 설명은 개요의 Skill 아키텍처를 참조하세요.
이것이 작성에 미치는 영향:
Claude가 Skill에 접근하는 방법:
reference/guide.md)를 사용하세요doc2.md가 아닌 form_validation_rules.mdreference/finance.md, reference/sales.mddocs/file1.md, docs/file2.mdvalidate_form.py를 작성하세요analyze_form.py를 실행하세요" (실행)analyze_form.py를 참조하세요" (참조로 읽기)예시:
bigquery-skill/
├── SKILL.md (overview, points to reference files)
└── reference/
├── finance.md (revenue metrics)
├── sales.md (pipeline data)
└── product.md (usage analytics)사용자가 수익에 대해 질문하면 Claude는 SKILL.md를 읽고, reference/finance.md에 대한 참조를 확인한 다음, bash를 호출하여 해당 파일만 읽습니다. sales.md 및 product.md 파일은 필요할 때까지 파일 시스템에 남아 있으며 컨텍스트 토큰을 전혀 소비하지 않습니다. 이 파일 시스템 기반 모델이 점진적 공개를 가능하게 합니다. Claude는 각 작업에 필요한 것을 정확히 탐색하고 선택적으로 로드할 수 있습니다.
기술 아키텍처에 대한 전체 세부 정보는 Skill 개요의 Skill 작동 방식을 참조하세요.
Skill이 MCP(Model Context Protocol) 도구를 사용하는 경우 "tool not found" 오류를 방지하기 위해 항상 정규화된 도구 이름을 사용하세요.
형식: ServerName:tool_name
예시:
Use the BigQuery:bigquery_schema tool to retrieve table schemas.
Use the GitHub:create_issue tool to create issues.여기서:
BigQuery와 GitHub는 MCP 서버 이름입니다bigquery_schema와 create_issue는 해당 서버 내의 도구 이름입니다서버 접두사가 없으면 특히 여러 MCP 서버를 사용할 수 있는 경우 Claude가 도구를 찾지 못할 수 있습니다.
패키지가 사용 가능하다고 가정하지 마세요:
**Bad example: Assumes installation**:
"Use the pdf library to process the file."
**Good example: Explicit about dependencies**:
"Install required package: `pip install pypdf`
Then use it:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"SKILL.md frontmatter에는 특정 검증 규칙이 있는 name 및 description 필드가 필요합니다:
name: 최대 64자, 소문자/숫자/하이픈만, XML 태그 없음, 예약어 없음description: 최대 1024자, 비어 있지 않음, XML 태그 없음전체 구조 세부 정보는 Skill 개요를 참조하세요.
최적의 성능을 위해 SKILL.md 본문을 500줄 미만으로 유지하세요. 콘텐츠가 이를 초과하면 앞서 설명한 점진적 공개 패턴을 사용하여 별도의 파일로 분할하세요. 아키텍처 세부 정보는 Skill 개요를 참조하세요.
Skill을 공유하기 전에 다음을 확인하세요:
첫 번째 Skill 만들기
Claude Code에서 Skill 생성 및 관리
프로그래밍 방식으로 Skill 업로드 및 사용
Was this page helpful?