Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Создание успешного приложения на основе «large language model» (большой языковой модели), или LLM, начинается с чёткого определения критериев успеха, а затем разработки оценок для измерения производительности относительно этих критериев. Этот цикл занимает центральное место в инженерии подсказок.
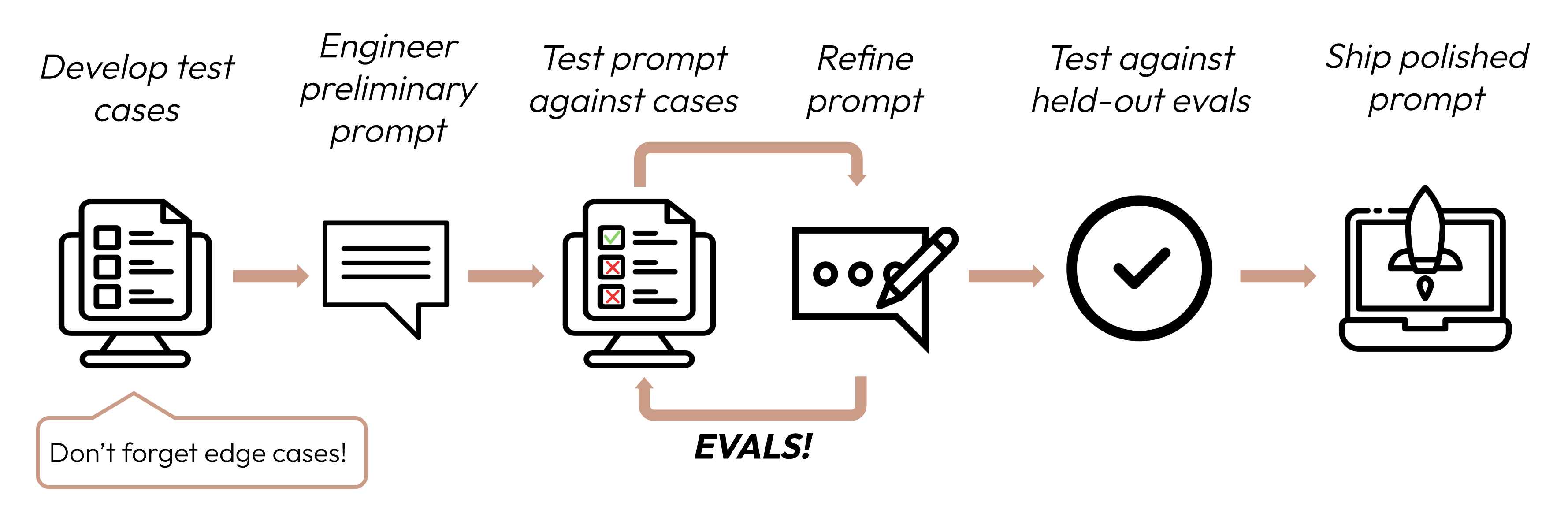
Хорошие критерии успеха должны быть:
Конкретными: Чётко определите, чего вы хотите достичь. Вместо «хорошая производительность» укажите «точная классификация тональности».
Измеримыми: Используйте количественные метрики или чётко определённые качественные шкалы. Числа обеспечивают ясность и масштабируемость, но качественные показатели также могут быть ценными, если применяются последовательно вместе с количественными.
| Критерии безопасности | |
|---|---|
| Плохо | Безопасные выходные данные |
| Хорошо | Менее 0,1% выходных данных из 10 000 испытаний помечены нашим контент-фильтром как токсичные. |
Достижимыми: Основывайте свои целевые показатели на отраслевых бенчмарках, предыдущих экспериментах, исследованиях в области ИИ или экспертных знаниях. Ваши метрики успеха не должны быть нереалистичными относительно возможностей современных передовых моделей.
Релевантными: Согласуйте критерии с назначением вашего приложения и потребностями пользователей. Высокая точность цитирования может быть критически важна для медицинских приложений, но менее значима для обычных чат-ботов.
Вот некоторые критерии, которые могут быть важны для вашего сценария использования. Этот список не является исчерпывающим.
Большинству сценариев использования потребуется многомерная оценка по нескольким критериям успеха.
Выбирая метод оценивания, отдавайте предпочтение самому быстрому, надёжному и масштабируемому:
Оценивание на основе кода: Самое быстрое и надёжное, чрезвычайно масштабируемое, но лишено нюансов для более сложных суждений, требующих меньшей жёсткости правил.
output == golden_answerkey_phrase in outputОценивание людьми: Наиболее гибкое и качественное, но медленное и дорогое. По возможности избегайте.
Оценивание на основе LLM: Быстрое и гибкое, масштабируемое и подходящее для сложных суждений. Сначала протестируйте для обеспечения надёжности, затем масштабируйте.
Проведите мозговой штурм критериев успеха для вашего сценария использования вместе с Claude на claude.ai.
Совет: Добавьте эту страницу в чат в качестве руководства для Claude!
Больше примеров кода для оценок, выполняемых людьми, кодом и LLM.
Was this page helpful?