Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Хорошие навыки лаконичны, хорошо структурированы и протестированы в реальных условиях. Это руководство содержит практические рекомендации по созданию навыков, которые Claude сможет эффективно обнаруживать и использовать.
Концептуальную информацию о том, как работают навыки, см. в обзоре навыков.
Контекстное окно — это общий ресурс. Ваш навык делит контекстное окно со всем остальным, что нужно знать Claude, включая:
Не каждый токен в вашем навыке имеет немедленную стоимость. При запуске предварительно загружаются только метаданные (имя и описание) всех навыков. Claude читает SKILL.md только тогда, когда навык становится релевантным, и читает дополнительные файлы только по мере необходимости. Однако лаконичность в SKILL.md всё равно важна: как только Claude загружает его, каждый токен конкурирует с историей разговора и другим контекстом.
Исходное предположение: Claude уже очень умён
Добавляйте только тот контекст, которого у Claude ещё нет. Подвергайте сомнению каждую часть информации:
Хороший пример: лаконичный (примерно 50 токенов):
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```Плохой пример: слишком многословный (примерно 150 токенов):
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but
pdfplumber is recommended because it's easy to use and handles most cases well.
First, you'll need to install it using pip. Then you can use the code below...Лаконичная версия предполагает, что Claude знает, что такое PDF и как работают библиотеки.
Соотносите уровень конкретности с хрупкостью и вариативностью задачи.
Высокая свобода (текстовые инструкции):
Используйте, когда:
Пример:
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventionsСредняя свобода (псевдокод или скрипты с параметрами):
Используйте, когда:
Пример:
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```Низкая свобода (конкретные скрипты, мало параметров или их отсутствие):
Используйте, когда:
Пример:
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.Аналогия: Представьте Claude как робота, исследующего путь:
Навыки действуют как дополнения к моделям, поэтому эффективность зависит от базовой модели. Тестируйте свой навык со всеми моделями, с которыми планируете его использовать.
Соображения по тестированию в зависимости от модели:
То, что идеально работает для Opus, может потребовать больше деталей для Haiku. Если вы планируете использовать свой навык с несколькими моделями, стремитесь к инструкциям, которые хорошо работают со всеми из них.
YAML Frontmatter: Frontmatter файла SKILL.md требует двух полей:
name:
description:
Полные сведения о структуре навыка см. в обзоре навыков.
Используйте согласованные шаблоны именования, чтобы на навыки было проще ссылаться и обсуждать их. Рассмотрите возможность использования герундиальной формы (глагол + -ing) для имён навыков, так как это чётко описывает деятельность или возможность, которую предоставляет навык.
Помните, что поле name должно использовать только строчные буквы, цифры и дефисы.
Хорошие примеры именования (герундиальная форма):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentationПриемлемые альтернативы:
pdf-processing, spreadsheet-analysisprocess-pdfs, analyze-spreadsheetsИзбегайте:
helper, utils, toolsdocuments, data, filesanthropic-helper, claude-toolsСогласованное именование облегчает:
Поле description обеспечивает обнаружение навыка и должно включать как то, что делает навык, так и то, когда его использовать.
Всегда пишите от третьего лица. Описание внедряется в системную подсказку, и несогласованная точка зрения может вызвать проблемы с обнаружением.
Будьте конкретны и включайте ключевые термины. Включайте как то, что делает навык, так и конкретные триггеры/контексты для его использования.
Каждый навык имеет ровно одно поле описания. Описание критически важно для выбора навыка: Claude использует его, чтобы выбрать правильный навык из потенциально 100+ доступных навыков. Ваше описание должно предоставлять достаточно деталей, чтобы Claude знал, когда выбрать этот навык, в то время как остальная часть SKILL.md предоставляет детали реализации.
Эффективные примеры:
Навык обработки PDF:
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.Навык анализа Excel:
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.Навык помощника Git-коммитов:
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.Избегайте расплывчатых описаний, подобных этим:
description: Helps with documentsdescription: Processes datadescription: Does stuff with filesSKILL.md служит обзором, который указывает Claude на подробные материалы по мере необходимости, подобно оглавлению в руководстве по адаптации. Объяснение того, как работает прогрессивное раскрытие, см. в разделе Как работают навыки в обзоре.
Практические рекомендации:
Базовый навык начинается с одного файла SKILL.md, содержащего метаданные и инструкции:
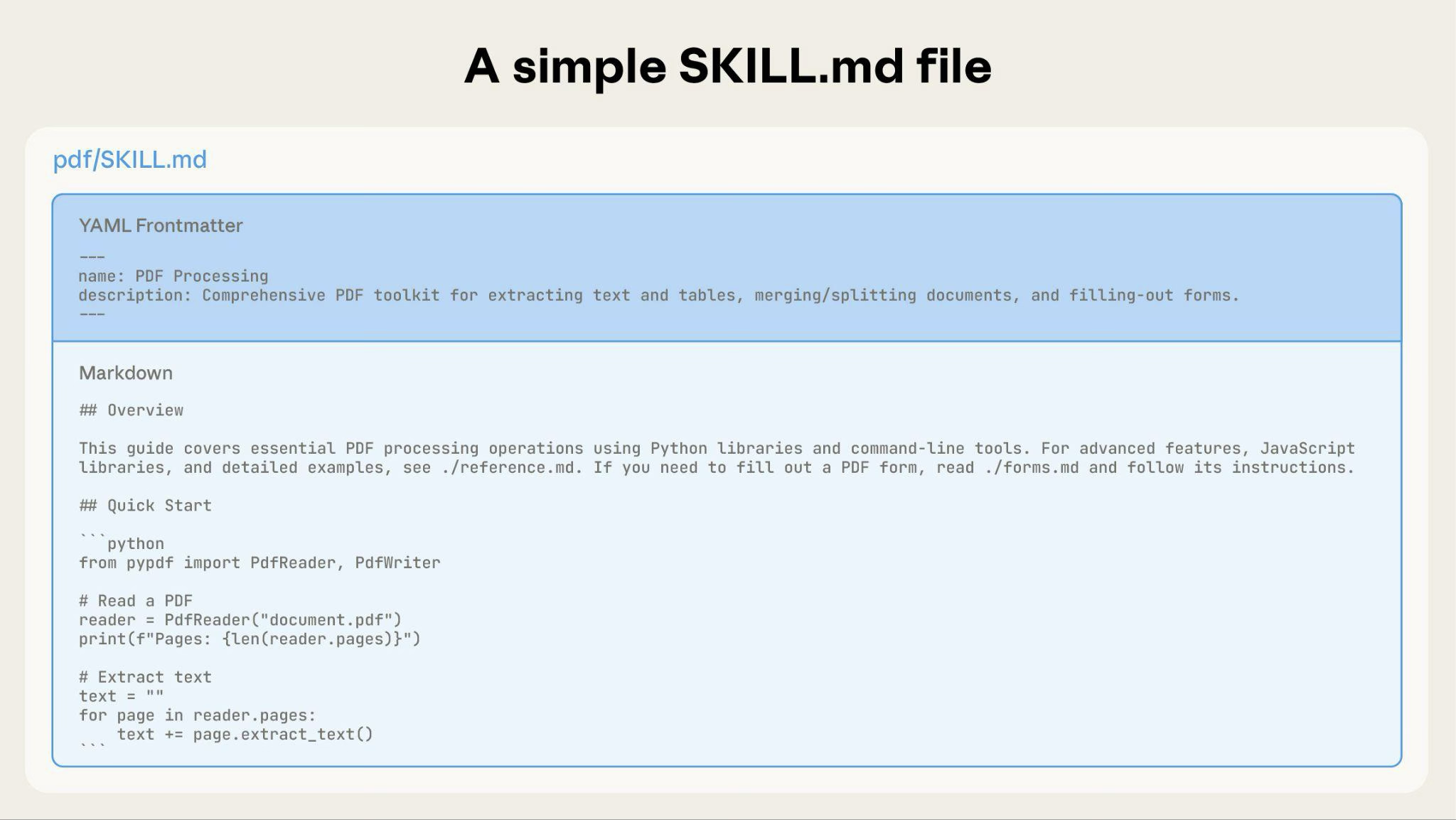
По мере роста вашего навыка вы можете включать дополнительное содержимое, которое Claude загружает только при необходимости:

Полная структура каталога навыка может выглядеть так:
pdf/
├── SKILL.md # Main instructions (loaded when triggered)
├── FORMS.md # Form-filling guide (loaded as needed)
├── reference.md # API reference (loaded as needed)
├── examples.md # Usage examples (loaded as needed)
└── scripts/
├── analyze_form.py # Utility script (executed, not loaded)
├── fill_form.py # Form filling script
└── validate.py # Validation script---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patternsClaude загружает FORMS.md, REFERENCE.md или EXAMPLES.md только при необходимости.
Для навыков с несколькими предметными областями организуйте содержимое по областям, чтобы избежать загрузки нерелевантного контекста. Когда пользователь спрашивает о метриках продаж, Claude нужно читать только схемы, связанные с продажами, а не данные о финансах или маркетинге. Это поддерживает низкое использование токенов и сфокусированный контекст.
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)# BigQuery Data Analysis
## Available datasets
**Finance**: Revenue, ARR, billing → See [reference/finance.md](reference/finance.md)
**Sales**: Opportunities, pipeline, accounts → See [reference/sales.md](reference/sales.md)
**Product**: API usage, features, adoption → See [reference/product.md](reference/product.md)
**Marketing**: Campaigns, attribution, email → See [reference/marketing.md](reference/marketing.md)
## Quick search
Find specific metrics using grep:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```Показывайте базовое содержимое, ссылайтесь на расширенное содержимое:
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)Claude читает REDLINING.md или OOXML.md только тогда, когда пользователю нужны эти функции.
Claude может частично читать файлы, когда на них ссылаются из других файлов, на которые есть ссылки. При обнаружении вложенных ссылок Claude может использовать команды вроде head -100 для предварительного просмотра содержимого вместо чтения целых файлов, что приводит к неполной информации.
Держите ссылки на глубине одного уровня от SKILL.md. Все справочные файлы должны ссылаться напрямую из SKILL.md, чтобы гарантировать, что Claude читает полные файлы при необходимости.
Плохой пример: слишком глубоко:
# SKILL.md
See [advanced.md](advanced.md)...
# advanced.md
See [details.md](details.md)...
# details.md
Here's the actual information...Хороший пример: один уровень глубины:
# SKILL.md
**Basic usage**: [instructions in SKILL.md]
**Advanced features**: See [advanced.md](advanced.md)
**API reference**: See [reference.md](reference.md)
**Examples**: See [examples.md](examples.md)Для справочных файлов длиннее 100 строк включайте оглавление в начале. Это гарантирует, что Claude сможет увидеть полный объём доступной информации даже при предварительном просмотре с частичным чтением.
Пример:
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
## Authentication and setup
...
## Core methods
...Затем Claude может прочитать полный файл или перейти к конкретным разделам по мере необходимости.
Подробности о том, как эта архитектура на основе файловой системы обеспечивает прогрессивное раскрытие, см. в разделе Среда выполнения в разделе «Дополнительно» ниже.
Разбивайте сложные операции на чёткие последовательные шаги. Для особенно сложных рабочих процессов предоставьте контрольный список, который Claude может скопировать в свой ответ и отмечать по мере выполнения.
Пример 1: Рабочий процесс синтеза исследований (для навыков без кода):
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.Этот пример показывает, как рабочие процессы применяются к аналитическим задачам, не требующим кода. Шаблон контрольного списка работает для любого сложного многоэтапного процесса.
Пример 2: Рабочий процесс заполнения PDF-форм (для навыков с кодом):
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
```
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
```
**Step 1: Analyze the form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create field mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify output**
Run: `python scripts/verify_output.py output.pdf`
If verification fails, return to Step 2.Чёткие шаги предотвращают пропуск Claude критической валидации. Контрольный список помогает и Claude, и вам отслеживать прогресс в многоэтапных рабочих процессах.
Распространённый шаблон: Запустить валидатор → исправить ошибки → повторить
Этот шаблон значительно улучшает качество вывода.
Пример 1: Соответствие руководству по стилю (для навыков без кода):
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the documentЭто показывает шаблон цикла валидации с использованием справочных документов вместо скриптов. «Валидатором» является STYLE_GUIDE.md, и Claude выполняет проверку путём чтения и сравнения.
Пример 2: Процесс редактирования документов (для навыков с кодом):
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test the output documentЦикл валидации выявляет ошибки на ранней стадии.
Не включайте информацию, которая устареет:
Плохой пример: зависящий от времени (станет неверным):
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.Хороший пример (используйте раздел «старые шаблоны»):
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>Раздел старых шаблонов предоставляет исторический контекст, не загромождая основное содержимое.
Выберите один термин и используйте его во всём навыке:
Хорошо — согласованно:
Плохо — несогласованно:
Согласованность помогает Claude понимать и следовать инструкциям.
Предоставляйте образцы для формата вывода. Соотносите уровень строгости с вашими потребностями.
Для строгих требований (например, ответы API или форматы данных):
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```Для гибких рекомендаций (когда адаптация полезна):
## Report structure
Here is a sensible default format, but use your best judgment based on the analysis:
```markdown
# [Analysis Title]
## Executive summary
[Overview]
## Key findings
[Adapt sections based on what you discover]
## Recommendations
[Tailor to the specific context]
```
Adjust sections as needed for the specific analysis type.Для навыков, где качество вывода зависит от наличия примеров, предоставляйте пары ввод/вывод так же, как в обычных подсказках:
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
**Example 3:**
Input: Updated dependencies and refactored error handling
Output:
```
chore: update dependencies and refactor error handling
- Upgrade lodash to 4.17.21
- Standardize error response format across endpoints
```
Follow this style: type(scope): brief description, then detailed explanation.Примеры помогают Claude понять желаемый стиль и уровень детализации более чётко, чем одни только описания.
Направляйте Claude через точки принятия решений:
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when completeЕсли рабочие процессы становятся большими или сложными с множеством шагов, рассмотрите возможность вынесения их в отдельные файлы и укажите Claude читать соответствующий файл в зависимости от текущей задачи.
Создавайте оценки ДО написания обширной документации. Это гарантирует, что ваш навык решает реальные проблемы, а не документирует воображаемые.
Разработка на основе оценок:
Этот подход гарантирует, что вы решаете реальные проблемы, а не предвосхищаете требования, которые могут никогда не материализоваться.
Структура оценки:
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF file and save it to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file using an appropriate PDF processing library or command-line tool",
"Extracts text content from all pages in the document without missing any pages",
"Saves the extracted text to a file named output.txt in a clear, readable format"
]
}Этот пример демонстрирует оценку на основе данных с простой рубрикой тестирования. В настоящее время нет встроенного способа запуска этих оценок. Пользователи могут создать собственную систему оценки. Оценки — это ваш источник истины для измерения эффективности навыка.
Наиболее эффективный процесс разработки навыков включает самого Claude. Работайте с одним экземпляром Claude («Claude A») для создания навыка, который используется другими экземплярами («Claude B»). Claude A помогает вам проектировать и уточнять инструкции, в то время как Claude B тестирует их на реальных задачах. Это работает, потому что модели Claude понимают как то, как писать эффективные инструкции для агентов, так и то, какая информация нужна агентам.
Создание нового навыка:
Выполните задачу без навыка: Проработайте проблему с Claude A, используя обычные подсказки. В процессе работы вы естественным образом будете предоставлять контекст, объяснять предпочтения и делиться процедурными знаниями. Обратите внимание, какую информацию вы предоставляете повторно.
Определите повторно используемый шаблон: После выполнения задачи определите, какой контекст вы предоставили, который был бы полезен для аналогичных будущих задач.
Пример: Если вы работали над анализом BigQuery, вы могли предоставить имена таблиц, определения полей, правила фильтрации (например, «всегда исключать тестовые аккаунты») и распространённые шаблоны запросов.
Попросите Claude A создать навык: «Создай навык, который фиксирует этот шаблон анализа BigQuery, который мы только что использовали. Включи схемы таблиц, соглашения об именовании и правило о фильтрации тестовых аккаунтов.»
Модели Claude изначально понимают формат и структуру навыков. Вам не нужны специальные системные подсказки или навык «написания навыков», чтобы Claude помог создать навыки. Просто попросите Claude создать навык, и он сгенерирует правильно структурированное содержимое SKILL.md с соответствующим frontmatter и телом.
Проверьте на лаконичность: Убедитесь, что Claude A не добавил ненужных объяснений. Попросите: «Удали объяснение о том, что означает коэффициент выигрыша — Claude уже это знает.»
Улучшите информационную архитектуру: Попросите Claude A организовать содержимое более эффективно. Например: «Организуй это так, чтобы схема таблицы была в отдельном справочном файле. Возможно, позже мы добавим больше таблиц.»
Протестируйте на аналогичных задачах: Используйте навык с Claude B (новый экземпляр с загруженным навыком) на связанных сценариях использования. Наблюдайте, находит ли Claude B правильную информацию, правильно ли применяет правила и успешно ли справляется с задачей.
Итерируйте на основе наблюдений: Если Claude B испытывает затруднения или что-то упускает, вернитесь к Claude A с конкретикой: «Когда Claude использовал этот навык, он забыл отфильтровать по дате для Q4. Стоит ли добавить раздел о шаблонах фильтрации по дате?»
Итерация существующих навыков:
Тот же иерархический шаблон продолжается при улучшении навыков. Вы чередуете:
Используйте навык в реальных рабочих процессах: Давайте Claude B (с загруженным навыком) реальные задачи, а не тестовые сценарии
Наблюдайте за поведением Claude B: Отмечайте, где он испытывает затруднения, преуспевает или делает неожиданный выбор
Пример наблюдения: «Когда я попросил Claude B региональный отчёт о продажах, он написал запрос, но забыл отфильтровать тестовые аккаунты, хотя навык упоминает это правило.»
Вернитесь к Claude A для улучшений: Поделитесь текущим SKILL.md и опишите, что вы наблюдали. Спросите: «Я заметил, что Claude B забыл отфильтровать тестовые аккаунты, когда я попросил региональный отчёт. Навык упоминает фильтрацию, но, возможно, это недостаточно заметно?»
Рассмотрите предложения Claude A: Claude A может предложить реорганизацию, чтобы сделать правила более заметными, использование более сильных формулировок вроде «ОБЯЗАТЕЛЬНО фильтровать» вместо «всегда фильтровать», или реструктуризацию раздела рабочего процесса.
Примените и протестируйте изменения: Обновите навык с уточнениями Claude A, затем снова протестируйте с Claude B на аналогичных запросах
Повторяйте на основе использования: Продолжайте этот цикл наблюдение-уточнение-тестирование по мере того, как вы сталкиваетесь с новыми сценариями. Каждая итерация улучшает навык на основе реального поведения агента, а не предположений.
Сбор обратной связи от команды:
Почему этот подход работает: Claude A понимает потребности агентов, вы предоставляете экспертизу в предметной области, Claude B выявляет пробелы через реальное использование, а итеративное уточнение улучшает навыки на основе наблюдаемого поведения, а не предположений.
По мере итерации навыков обращайте внимание на то, как Claude фактически использует их на практике. Следите за:
Итерируйте на основе этих наблюдений, а не предположений. Поля 'name' и 'description' в метаданных вашего навыка особенно критичны. Claude использует их при принятии решения о том, запускать ли навык в ответ на текущую задачу. Убедитесь, что они чётко описывают, что делает навык и когда его следует использовать.
Всегда используйте прямые слэши в путях к файлам, даже в Windows:
scripts/helper.py, reference/guide.mdscripts\helper.py, reference\guide.mdПути в стиле Unix работают на всех платформах, в то время как пути в стиле Windows вызывают ошибки в системах Unix.
Не представляйте несколько подходов, если это не необходимо:
**Bad example: Too many choices** (confusing):
"You can use pypdf, or pdfplumber, or PyMuPDF, or pdf2image, or..."
**Good example: Provide a default** (with escape hatch):
"Use pdfplumber for text extraction:
```python
import pdfplumber
```
For scanned PDFs requiring OCR, use pdf2image with pytesseract instead."Разделы ниже посвящены навыкам, которые включают исполняемые скрипты. Если ваш навык использует только инструкции в формате markdown, перейдите к разделу Контрольный список для эффективных навыков.
При написании скриптов для навыков обрабатывайте условия ошибок, а не перекладывайте их на Claude.
Хороший пример: явная обработка ошибок:
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# Создать файл с содержимым по умолчанию вместо завершения с ошибкой
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# Предоставить альтернативу вместо завершения с ошибкой
print(f"Cannot access {path}, using default")
return ""Плохой пример: перекладывание на Claude:
def process_file(path):
# Просто завершаемся с ошибкой и позволяем Claude разобраться
return open(path).read()Параметры конфигурации также должны быть обоснованы и задокументированы, чтобы избежать «магических констант» (закон Оустерхаута). Если вы не знаете правильное значение, как Claude его определит?
Хороший пример: самодокументирующийся:
# HTTP-запросы обычно завершаются в течение 30 секунд
# Увеличенный тайм-аут учитывает медленные соединения
REQUEST_TIMEOUT = 30
# Три повторные попытки — баланс между надёжностью и скоростью
# Большинство временных сбоев устраняются ко второй попытке
MAX_RETRIES = 3Плохой пример: магические числа:
TIMEOUT = 47 # Why 47?
RETRIES = 5 # Why 5?Даже если Claude мог бы написать скрипт, готовые скрипты предлагают преимущества:
Преимущества служебных скриптов:

Диаграмма выше показывает, как исполняемые скрипты работают вместе с файлами инструкций. Файл инструкций (forms.md) ссылается на скрипт, и Claude может выполнить его, не загружая его содержимое в контекст.
Важное различие: Чётко укажите в своих инструкциях, должен ли Claude:
analyze_form.py для извлечения полей»analyze_form.py для алгоритма извлечения полей»Для большинства служебных скриптов предпочтительно выполнение, потому что оно более надёжно и эффективно. См. раздел Среда выполнения ниже для подробностей о том, как работает выполнение скриптов.
Пример:
## Utility scripts
**analyze_form.py**: Extract all form fields from PDF
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
Output format:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**: Check for overlapping bounding boxes
```bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
```
**fill_form.py**: Apply field values to PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```Когда входные данные могут быть отрендерены как изображения, пусть Claude анализирует их:
## Form layout analysis
1. Convert PDF to images:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. Analyze each page image to identify form fields
3. Claude can see field locations and types visuallyВ этом примере вам нужно будет написать скрипт pdf_to_images.py.
Возможности зрения Claude помогают понимать макеты и структуры.
Когда Claude выполняет сложные открытые задачи, он может допускать ошибки. Шаблон «планировать-валидировать-выполнять» выявляет ошибки на ранней стадии, заставляя Claude сначала создать план в структурированном формате, затем валидировать этот план скриптом перед его выполнением.
Пример: Представьте, что вы просите Claude обновить 50 полей формы в PDF на основе электронной таблицы. Без валидации Claude может ссылаться на несуществующие поля, создавать конфликтующие значения, пропускать обязательные поля или неправильно применять обновления.
Решение: Используйте шаблон рабочего процесса, показанный выше (заполнение PDF-форм), но добавьте промежуточный файл changes.json, который валидируется перед применением изменений. Рабочий процесс становится: анализировать → создать файл плана → валидировать план → выполнить → проверить.
Почему этот шаблон работает:
Когда использовать: Пакетные операции, деструктивные изменения, сложные правила валидации, операции с высокими ставками.
Совет по реализации: Делайте скрипты валидации подробными с конкретными сообщениями об ошибках вроде «Поле 'signature_date' не найдено. Доступные поля: customer_name, order_total, signature_date_signed», чтобы помочь Claude исправить проблемы.
Навыки выполняются в среде выполнения кода с ограничениями, специфичными для платформы:
Перечислите необходимые пакеты в вашем SKILL.md и проверьте их доступность в документации инструмента выполнения кода.
Навыки выполняются в среде выполнения кода с доступом к файловой системе, командами bash и возможностями выполнения кода. Концептуальное объяснение этой архитектуры см. в разделе Архитектура навыков в обзоре.
Как это влияет на ваше создание навыков:
Как Claude получает доступ к навыкам:
reference/guide.md), а не обратныеform_validation_rules.md, а не doc2.mdreference/finance.md, reference/sales.mddocs/file1.md, docs/file2.mdvalidate_form.py вместо того, чтобы просить Claude сгенерировать код валидацииanalyze_form.py для извлечения полей» (выполнить)analyze_form.py для алгоритма извлечения» (прочитать как справочник)Пример:
bigquery-skill/
├── SKILL.md (overview, points to reference files)
└── reference/
├── finance.md (revenue metrics)
├── sales.md (pipeline data)
└── product.md (usage analytics)Когда пользователь спрашивает о выручке, Claude читает SKILL.md, видит ссылку на reference/finance.md и вызывает bash для чтения только этого файла. Файлы sales.md и product.md остаются в файловой системе, потребляя ноль токенов контекста, пока не понадобятся. Эта модель на основе файловой системы — то, что обеспечивает прогрессивное раскрытие. Claude может навигировать и выборочно загружать именно то, что требует каждая задача.
Полные сведения о технической архитектуре см. в разделе Как работают навыки в обзоре навыков.
Если ваш навык использует инструменты MCP (Model Context Protocol), всегда используйте полностью квалифицированные имена инструментов, чтобы избежать ошибок «инструмент не найден».
Формат: ServerName:tool_name
Пример:
Use the BigQuery:bigquery_schema tool to retrieve table schemas.
Use the GitHub:create_issue tool to create issues.Где:
BigQuery и GitHub — имена серверов MCPbigquery_schema и create_issue — имена инструментов внутри этих серверовБез префикса сервера Claude может не найти инструмент, особенно когда доступно несколько серверов MCP.
Не предполагайте, что пакеты доступны:
**Bad example: Assumes installation**:
"Use the pdf library to process the file."
**Good example: Explicit about dependencies**:
"Install required package: `pip install pypdf`
Then use it:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"Frontmatter файла SKILL.md требует полей name и description с конкретными правилами валидации:
name: Максимум 64 символа, только строчные буквы/цифры/дефисы, без XML-тегов, без зарезервированных словdescription: Максимум 1024 символа, непустое, без XML-теговСм. обзор навыков для полных сведений о структуре.
Держите тело SKILL.md в пределах 500 строк для оптимальной производительности. Если ваше содержимое превышает это, разделите его на отдельные файлы, используя шаблоны прогрессивного раскрытия, описанные ранее. Архитектурные детали см. в обзоре навыков.
Перед тем как поделиться навыком, проверьте:
Создайте свой первый навык
Создавайте навыки и управляйте ими в Claude Code
Загружайте и используйте навыки программно
Was this page helpful?