Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Construir una aplicación exitosa basada en LLM comienza por definir claramente tus criterios de éxito y luego diseñar evaluaciones para medir el rendimiento en función de ellos. Este ciclo es fundamental para la ingeniería de prompts.
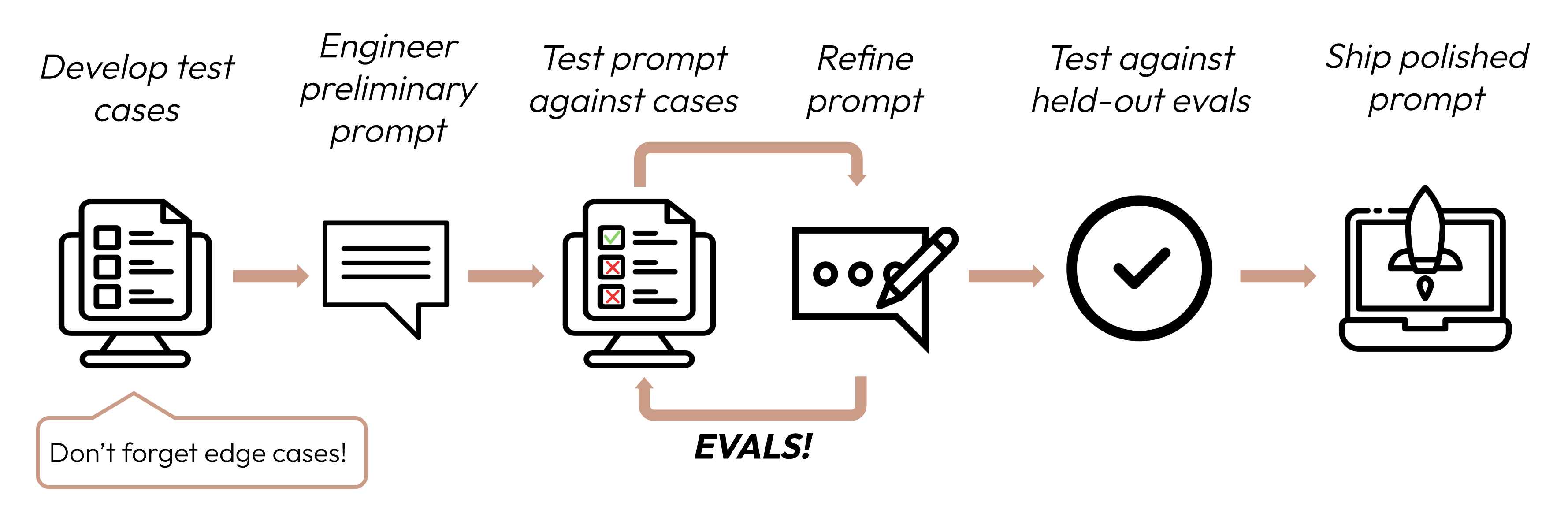
Los buenos criterios de éxito son:
Específicos: Define claramente lo que quieres lograr. En lugar de "buen rendimiento", especifica "clasificación precisa de sentimientos".
Medibles: Usa métricas cuantitativas o escalas cualitativas bien definidas. Los números proporcionan claridad y escalabilidad, pero las medidas cualitativas pueden ser valiosas si se aplican de manera consistente junto con medidas cuantitativas.
| Criterios de seguridad | |
|---|---|
| Malo | Salidas seguras |
| Bueno | Menos del 0.1% de las salidas de 10,000 pruebas marcadas por toxicidad por nuestro filtro de contenido. |
Alcanzables: Basa tus objetivos en puntos de referencia de la industria, experimentos previos, investigación en IA o conocimiento experto. Tus métricas de éxito no deben ser poco realistas respecto a las capacidades actuales de los modelos de vanguardia.
Relevantes: Alinea tus criterios con el propósito de tu aplicación y las necesidades de los usuarios. Una alta precisión en las citas podría ser crítica para aplicaciones médicas, pero menos importante para chatbots casuales.
Aquí hay algunos criterios que podrían ser importantes para tu caso de uso. Esta lista no es exhaustiva.
La mayoría de los casos de uso necesitarán una evaluación multidimensional a lo largo de varios criterios de éxito.
Al decidir qué método usar para calificar las evaluaciones, elige el método más rápido, más confiable y más escalable:
Calificación basada en código: La más rápida y confiable, extremadamente escalable, pero también carece de matices para juicios más complejos que requieren menos rigidez basada en reglas.
output == golden_answerkey_phrase in outputCalificación humana: La más flexible y de alta calidad, pero lenta y costosa. Evítala si es posible.
Calificación basada en LLM: Rápida y flexible, escalable y adecuada para juicios complejos. Prueba primero para garantizar la confiabilidad y luego escala.
Haz una lluvia de ideas sobre criterios de éxito para tu caso de uso con Claude en claude.ai.
Consejo: ¡Incluye esta página en el chat como guía para Claude!
Más ejemplos de código de evaluaciones calificadas por humanos, por código y por LLM.
Was this page helpful?