Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Las buenas Skills son concisas, bien estructuradas y probadas con uso real. Esta guía proporciona decisiones prácticas de creación para ayudarte a escribir Skills que Claude pueda descubrir y usar de manera efectiva.
Para obtener información conceptual sobre cómo funcionan las Skills, consulta la descripción general de Skills.
La ventana de contexto es un bien público. Tu Skill comparte la ventana de contexto con todo lo demás que Claude necesita saber, incluyendo:
No todos los tokens de tu Skill tienen un costo inmediato. Al inicio, solo se precargan los metadatos (nombre y descripción) de todas las Skills. Claude lee SKILL.md únicamente cuando la Skill se vuelve relevante, y lee archivos adicionales solo según sea necesario. Sin embargo, ser conciso en SKILL.md sigue siendo importante: una vez que Claude lo carga, cada token compite con el historial de la conversación y otro contexto.
Suposición predeterminada: Claude ya es muy inteligente
Solo agrega contexto que Claude no tenga ya. Cuestiona cada pieza de información:
Buen ejemplo: Conciso (aproximadamente 50 tokens):
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```Mal ejemplo: Demasiado extenso (aproximadamente 150 tokens):
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but
pdfplumber is recommended because it's easy to use and handles most cases well.
First, you'll need to install it using pip. Then you can use the code below...La versión concisa asume que Claude sabe qué son los PDFs y cómo funcionan las bibliotecas.
Ajusta el nivel de especificidad a la fragilidad y variabilidad de la tarea.
Libertad alta (instrucciones basadas en texto):
Úsala cuando:
Ejemplo:
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventionsLibertad media (pseudocódigo o scripts con parámetros):
Úsala cuando:
Ejemplo:
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```Libertad baja (scripts específicos, pocos o ningún parámetro):
Úsala cuando:
Ejemplo:
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.Analogía: Piensa en Claude como un robot explorando un camino:
Las Skills actúan como complementos de los modelos, por lo que su efectividad depende del modelo subyacente. Prueba tu Skill con todos los modelos con los que planeas usarla.
Consideraciones de prueba por modelo:
Lo que funciona perfectamente para Opus podría necesitar más detalle para Haiku. Si planeas usar tu Skill con múltiples modelos, busca instrucciones que funcionen bien con todos ellos.
Frontmatter YAML: El frontmatter de SKILL.md requiere dos campos:
name:
description:
Para obtener detalles completos sobre la estructura de las Skills, consulta la descripción general de Skills.
Usa patrones de nomenclatura consistentes para que las Skills sean más fáciles de referenciar y discutir. Considera usar la forma de gerundio (verbo + -ing) para los nombres de las Skills, ya que esto describe claramente la actividad o capacidad que proporciona la Skill.
Recuerda que el campo name debe usar solo letras minúsculas, números y guiones.
Buenos ejemplos de nomenclatura (forma de gerundio):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentationAlternativas aceptables:
pdf-processing, spreadsheet-analysisprocess-pdfs, analyze-spreadsheetsEvita:
helper, utils, toolsdocuments, data, filesanthropic-helper, claude-toolsLa nomenclatura consistente facilita:
El campo description permite el descubrimiento de la Skill y debe incluir tanto qué hace la Skill como cuándo usarla.
Escribe siempre en tercera persona. La descripción se inyecta en la indicación del sistema, y un punto de vista inconsistente puede causar problemas de descubrimiento.
Sé específico e incluye términos clave. Incluye tanto qué hace la Skill como los desencadenantes/contextos específicos de cuándo usarla.
Cada Skill tiene exactamente un campo de descripción. La descripción es crítica para la selección de Skills: Claude la usa para elegir la Skill correcta entre potencialmente más de 100 Skills disponibles. Tu descripción debe proporcionar suficiente detalle para que Claude sepa cuándo seleccionar esta Skill, mientras que el resto de SKILL.md proporciona los detalles de implementación.
Ejemplos efectivos:
Skill de procesamiento de PDF:
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.Skill de análisis de Excel:
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.Skill de ayuda para commits de Git:
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.Evita descripciones vagas como estas:
description: Helps with documentsdescription: Processes datadescription: Does stuff with filesSKILL.md sirve como una descripción general que dirige a Claude hacia materiales detallados según sea necesario, como una tabla de contenidos en una guía de incorporación. Para una explicación de cómo funciona la divulgación progresiva, consulta Cómo funcionan las Skills en la descripción general.
Orientación práctica:
Una Skill básica comienza con solo un archivo SKILL.md que contiene metadatos e instrucciones:
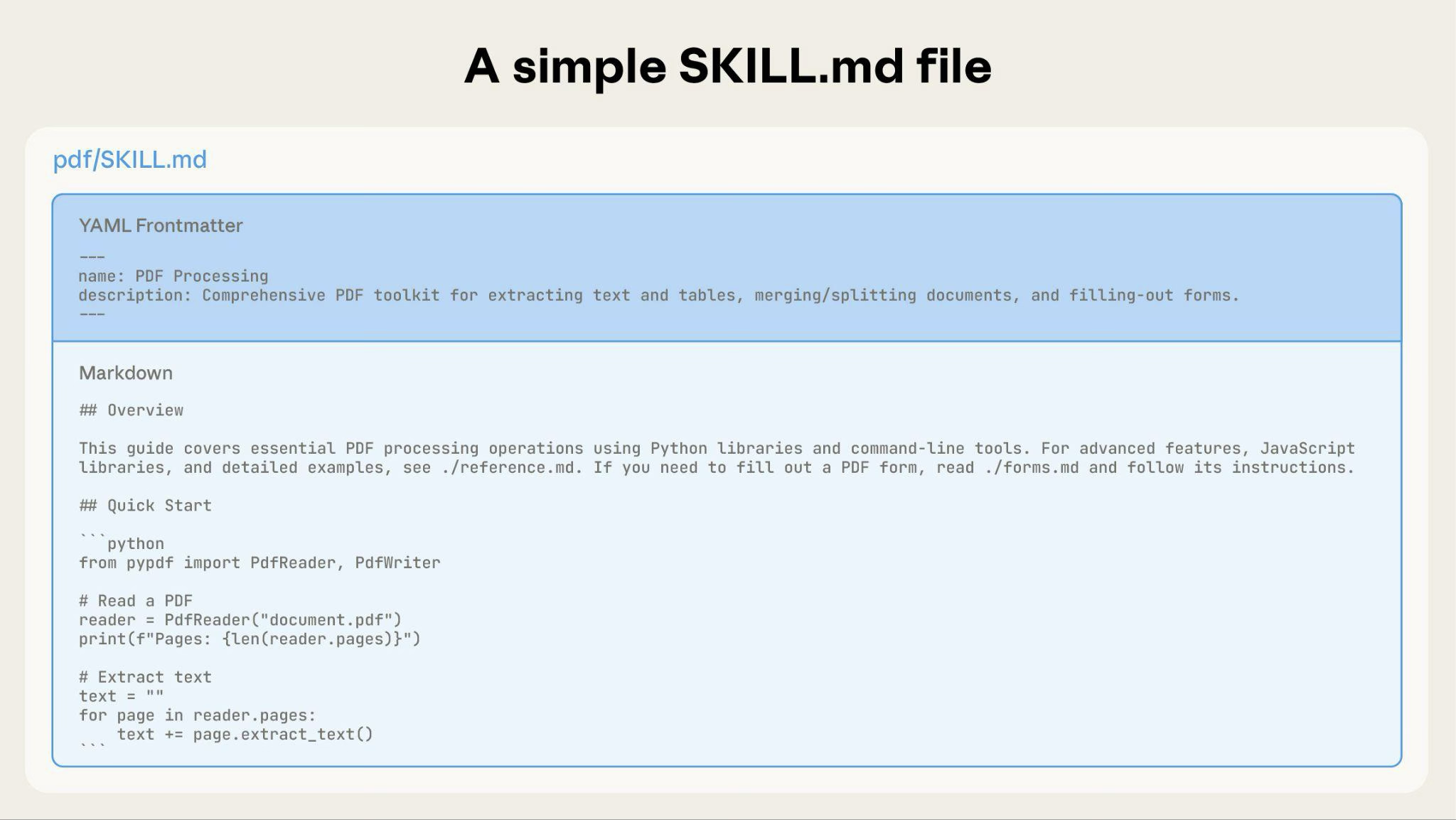
A medida que tu Skill crece, puedes agrupar contenido adicional que Claude carga solo cuando es necesario:

La estructura completa del directorio de la Skill podría verse así:
pdf/
├── SKILL.md # Main instructions (loaded when triggered)
├── FORMS.md # Form-filling guide (loaded as needed)
├── reference.md # API reference (loaded as needed)
├── examples.md # Usage examples (loaded as needed)
└── scripts/
├── analyze_form.py # Utility script (executed, not loaded)
├── fill_form.py # Form filling script
└── validate.py # Validation script---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patternsClaude carga FORMS.md, REFERENCE.md o EXAMPLES.md solo cuando es necesario.
Para Skills con múltiples dominios, organiza el contenido por dominio para evitar cargar contexto irrelevante. Cuando un usuario pregunta sobre métricas de ventas, Claude solo necesita leer esquemas relacionados con ventas, no datos de finanzas o marketing. Esto mantiene bajo el uso de tokens y el contexto enfocado.
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)# BigQuery Data Analysis
## Available datasets
**Finance**: Revenue, ARR, billing → See [reference/finance.md](reference/finance.md)
**Sales**: Opportunities, pipeline, accounts → See [reference/sales.md](reference/sales.md)
**Product**: API usage, features, adoption → See [reference/product.md](reference/product.md)
**Marketing**: Campaigns, attribution, email → See [reference/marketing.md](reference/marketing.md)
## Quick search
Find specific metrics using grep:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```Muestra contenido básico, enlaza a contenido avanzado:
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)Claude lee REDLINING.md u OOXML.md solo cuando el usuario necesita esas funciones.
Claude puede leer archivos parcialmente cuando se referencian desde otros archivos referenciados. Al encontrar referencias anidadas, Claude podría usar comandos como head -100 para previsualizar contenido en lugar de leer archivos completos, lo que resulta en información incompleta.
Mantén las referencias a un nivel de profundidad desde SKILL.md. Todos los archivos de referencia deben enlazarse directamente desde SKILL.md para garantizar que Claude lea archivos completos cuando sea necesario.
Mal ejemplo: Demasiado profundo:
# SKILL.md
See [advanced.md](advanced.md)...
# advanced.md
See [details.md](details.md)...
# details.md
Here's the actual information...Buen ejemplo: Un nivel de profundidad:
# SKILL.md
**Basic usage**: [instructions in SKILL.md]
**Advanced features**: See [advanced.md](advanced.md)
**API reference**: See [reference.md](reference.md)
**Examples**: See [examples.md](examples.md)Para archivos de referencia de más de 100 líneas, incluye una tabla de contenidos al principio. Esto garantiza que Claude pueda ver el alcance completo de la información disponible incluso al previsualizar con lecturas parciales.
Ejemplo:
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
## Authentication and setup
...
## Core methods
...Claude puede entonces leer el archivo completo o saltar a secciones específicas según sea necesario.
Para obtener detalles sobre cómo esta arquitectura basada en el sistema de archivos permite la divulgación progresiva, consulta la sección Entorno de ejecución en la sección Avanzado a continuación.
Divide las operaciones complejas en pasos claros y secuenciales. Para flujos de trabajo particularmente complejos, proporciona una lista de verificación que Claude pueda copiar en su respuesta y marcar a medida que avanza.
Ejemplo 1: Flujo de trabajo de síntesis de investigación (para Skills sin código):
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.Este ejemplo muestra cómo los flujos de trabajo se aplican a tareas de análisis que no requieren código. El patrón de lista de verificación funciona para cualquier proceso complejo de múltiples pasos.
Ejemplo 2: Flujo de trabajo de llenado de formularios PDF (para Skills con código):
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
```
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
```
**Step 1: Analyze the form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create field mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify output**
Run: `python scripts/verify_output.py output.pdf`
If verification fails, return to Step 2.Los pasos claros evitan que Claude omita validaciones críticas. La lista de verificación ayuda tanto a Claude como a ti a seguir el progreso a través de flujos de trabajo de múltiples pasos.
Patrón común: Ejecutar validador → corregir errores → repetir
Este patrón mejora enormemente la calidad de la salida.
Ejemplo 1: Cumplimiento de guía de estilo (para Skills sin código):
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the documentEsto muestra el patrón de bucle de validación usando documentos de referencia en lugar de scripts. El "validador" es STYLE_GUIDE.md, y Claude realiza la verificación leyendo y comparando.
Ejemplo 2: Proceso de edición de documentos (para Skills con código):
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test the output documentEl bucle de validación detecta errores temprano.
No incluyas información que quedará desactualizada:
Mal ejemplo: Sensible al tiempo (se volverá incorrecto):
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.Buen ejemplo (usa una sección de "patrones antiguos"):
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>La sección de patrones antiguos proporciona contexto histórico sin saturar el contenido principal.
Elige un término y úsalo en toda la Skill:
Bien - Consistente:
Mal - Inconsistente:
La consistencia ayuda a Claude a entender y seguir las instrucciones.
Proporciona plantillas para el formato de salida. Ajusta el nivel de rigurosidad a tus necesidades.
Para requisitos estrictos (como respuestas de API o formatos de datos):
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```Para orientación flexible (cuando la adaptación es útil):
## Report structure
Here is a sensible default format, but use your best judgment based on the analysis:
```markdown
# [Analysis Title]
## Executive summary
[Overview]
## Key findings
[Adapt sections based on what you discover]
## Recommendations
[Tailor to the specific context]
```
Adjust sections as needed for the specific analysis type.Para Skills donde la calidad de la salida depende de ver ejemplos, proporciona pares de entrada/salida tal como en el prompting regular:
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
**Example 3:**
Input: Updated dependencies and refactored error handling
Output:
```
chore: update dependencies and refactor error handling
- Upgrade lodash to 4.17.21
- Standardize error response format across endpoints
```
Follow this style: type(scope): brief description, then detailed explanation.Los ejemplos ayudan a Claude a entender el estilo y nivel de detalle deseados con más claridad que las descripciones por sí solas.
Guía a Claude a través de puntos de decisión:
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when completeSi los flujos de trabajo se vuelven grandes o complicados con muchos pasos, considera trasladarlos a archivos separados e indica a Claude que lea el archivo apropiado según la tarea en cuestión.
Crea evaluaciones ANTES de escribir documentación extensa. Esto garantiza que tu Skill resuelva problemas reales en lugar de documentar problemas imaginados.
Desarrollo guiado por evaluaciones:
Este enfoque garantiza que estés resolviendo problemas reales en lugar de anticipar requisitos que quizás nunca se materialicen.
Estructura de evaluación:
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF file and save it to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file using an appropriate PDF processing library or command-line tool",
"Extracts text content from all pages in the document without missing any pages",
"Saves the extracted text to a file named output.txt in a clear, readable format"
]
}Este ejemplo demuestra una evaluación basada en datos con una rúbrica de prueba simple. Actualmente no existe una forma integrada de ejecutar estas evaluaciones. Los usuarios pueden crear su propio sistema de evaluación. Las evaluaciones son tu fuente de verdad para medir la efectividad de las Skills.
El proceso de desarrollo de Skills más efectivo involucra al propio Claude. Trabaja con una instancia de Claude ("Claude A") para crear una Skill que sea usada por otras instancias ("Claude B"). Claude A te ayuda a diseñar y refinar instrucciones, mientras que Claude B las prueba en tareas reales. Esto funciona porque los modelos de Claude entienden tanto cómo escribir instrucciones efectivas para agentes como qué información necesitan los agentes.
Crear una nueva Skill:
Completa una tarea sin una Skill: Trabaja en un problema con Claude A usando prompting normal. Mientras trabajas, naturalmente proporcionarás contexto, explicarás preferencias y compartirás conocimiento procedimental. Observa qué información proporcionas repetidamente.
Identifica el patrón reutilizable: Después de completar la tarea, identifica qué contexto proporcionaste que sería útil para tareas futuras similares.
Ejemplo: Si trabajaste en un análisis de BigQuery, podrías haber proporcionado nombres de tablas, definiciones de campos, reglas de filtrado (como "siempre excluir cuentas de prueba") y patrones de consulta comunes.
Pide a Claude A que cree una Skill: "Crea una Skill que capture este patrón de análisis de BigQuery que acabamos de usar. Incluye los esquemas de tablas, las convenciones de nomenclatura y la regla sobre filtrar cuentas de prueba."
Los modelos de Claude entienden el formato y la estructura de las Skills de forma nativa. No necesitas indicaciones del sistema especiales ni una Skill de "escribir skills" para que Claude te ayude a crear Skills. Simplemente pide a Claude que cree una Skill y generará contenido de SKILL.md correctamente estructurado con frontmatter y contenido del cuerpo apropiados.
Revisa la concisión: Verifica que Claude A no haya agregado explicaciones innecesarias. Pide: "Elimina la explicación sobre qué significa la tasa de éxito; Claude ya sabe eso."
Mejora la arquitectura de la información: Pide a Claude A que organice el contenido de manera más efectiva. Por ejemplo: "Organiza esto para que el esquema de la tabla esté en un archivo de referencia separado. Podríamos agregar más tablas más adelante."
Prueba en tareas similares: Usa la Skill con Claude B (una instancia nueva con la Skill cargada) en casos de uso relacionados. Observa si Claude B encuentra la información correcta, aplica las reglas correctamente y maneja la tarea con éxito.
Itera según la observación: Si Claude B tiene dificultades o pasa algo por alto, regresa a Claude A con detalles específicos: "Cuando Claude usó esta Skill, olvidó filtrar por fecha para el Q4. ¿Deberíamos agregar una sección sobre patrones de filtrado por fecha?"
Iterar sobre Skills existentes:
El mismo patrón jerárquico continúa al mejorar Skills. Alternas entre:
Usa la Skill en flujos de trabajo reales: Dale a Claude B (con la Skill cargada) tareas reales, no escenarios de prueba
Observa el comportamiento de Claude B: Anota dónde tiene dificultades, tiene éxito o toma decisiones inesperadas
Observación de ejemplo: "Cuando le pedí a Claude B un informe de ventas regional, escribió la consulta pero olvidó filtrar las cuentas de prueba, aunque la Skill menciona esta regla."
Regresa a Claude A para mejoras: Comparte el SKILL.md actual y describe lo que observaste. Pregunta: "Noté que Claude B olvidó filtrar las cuentas de prueba cuando pedí un informe regional. La Skill menciona el filtrado, pero ¿quizás no es lo suficientemente prominente?"
Revisa las sugerencias de Claude A: Claude A podría sugerir reorganizar para hacer las reglas más prominentes, usar un lenguaje más fuerte como "DEBE filtrar" en lugar de "siempre filtrar", o reestructurar la sección de flujo de trabajo.
Aplica y prueba los cambios: Actualiza la Skill con los refinamientos de Claude A, luego prueba nuevamente con Claude B en solicitudes similares
Repite según el uso: Continúa este ciclo de observar-refinar-probar a medida que encuentres nuevos escenarios. Cada iteración mejora la Skill basándose en el comportamiento real del agente, no en suposiciones.
Recopilar retroalimentación del equipo:
Por qué funciona este enfoque: Claude A entiende las necesidades del agente, tú proporcionas experiencia en el dominio, Claude B revela brechas a través del uso real, y el refinamiento iterativo mejora las Skills basándose en el comportamiento observado en lugar de suposiciones.
A medida que iteras sobre las Skills, presta atención a cómo Claude las usa realmente en la práctica. Observa:
Itera basándote en estas observaciones en lugar de suposiciones. El 'name' y la 'description' en los metadatos de tu Skill son particularmente críticos. Claude los usa al decidir si activar la Skill en respuesta a la tarea actual. Asegúrate de que describan claramente qué hace la Skill y cuándo debe usarse.
Usa siempre barras diagonales en las rutas de archivos, incluso en Windows:
scripts/helper.py, reference/guide.mdscripts\helper.py, reference\guide.mdLas rutas estilo Unix funcionan en todas las plataformas, mientras que las rutas estilo Windows causan errores en sistemas Unix.
No presentes múltiples enfoques a menos que sea necesario:
**Bad example: Too many choices** (confusing):
"You can use pypdf, or pdfplumber, or PyMuPDF, or pdf2image, or..."
**Good example: Provide a default** (with escape hatch):
"Use pdfplumber for text extraction:
```python
import pdfplumber
```
For scanned PDFs requiring OCR, use pdf2image with pytesseract instead."Las secciones a continuación se centran en Skills que incluyen scripts ejecutables. Si tu Skill usa solo instrucciones en markdown, salta a Lista de verificación para Skills efectivas.
Al escribir scripts para Skills, maneja las condiciones de error en lugar de delegarlas a Claude.
Buen ejemplo: Manejar errores explícitamente:
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# Crea el archivo con contenido predeterminado en lugar de fallar
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# Proporciona una alternativa en lugar de fallar
print(f"Cannot access {path}, using default")
return ""Mal ejemplo: Delegar a Claude:
def process_file(path):
# Simplemente falla y deja que Claude lo resuelva
return open(path).read()Los parámetros de configuración también deben estar justificados y documentados para evitar "constantes vudú" (ley de Ousterhout). Si no conoces el valor correcto, ¿cómo lo determinará Claude?
Buen ejemplo: Autodocumentado:
# Las solicitudes HTTP normalmente se completan en 30 segundos
# Un tiempo de espera más largo contempla conexiones lentas
REQUEST_TIMEOUT = 30
# Tres reintentos equilibran confiabilidad y velocidad
# La mayoría de fallos intermitentes se resuelven al segundo reintento
MAX_RETRIES = 3Mal ejemplo: Números mágicos:
TIMEOUT = 47 # Why 47?
RETRIES = 5 # Why 5?Incluso si Claude pudiera escribir un script, los scripts prefabricados ofrecen ventajas:
Beneficios de los scripts de utilidad:

El diagrama anterior muestra cómo los scripts ejecutables funcionan junto con los archivos de instrucciones. El archivo de instrucciones (forms.md) referencia el script, y Claude puede ejecutarlo sin cargar su contenido en el contexto.
Distinción importante: Deja claro en tus instrucciones si Claude debe:
analyze_form.py para extraer campos"analyze_form.py para el algoritmo de extracción de campos"Para la mayoría de los scripts de utilidad, se prefiere la ejecución porque es más confiable y eficiente. Consulta la sección Entorno de ejecución a continuación para obtener detalles sobre cómo funciona la ejecución de scripts.
Ejemplo:
## Utility scripts
**analyze_form.py**: Extract all form fields from PDF
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
Output format:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**: Check for overlapping bounding boxes
```bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
```
**fill_form.py**: Apply field values to PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```Cuando las entradas se pueden renderizar como imágenes, haz que Claude las analice:
## Form layout analysis
1. Convert PDF to images:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. Analyze each page image to identify form fields
3. Claude can see field locations and types visuallyEn este ejemplo, necesitarías escribir el script pdf_to_images.py.
Las capacidades de visión de Claude ayudan a entender diseños y estructuras.
Cuando Claude realiza tareas complejas y abiertas, puede cometer errores. El patrón "planificar-validar-ejecutar" detecta errores temprano haciendo que Claude primero cree un plan en un formato estructurado, luego valide ese plan con un script antes de ejecutarlo.
Ejemplo: Imagina pedirle a Claude que actualice 50 campos de formulario en un PDF basándose en una hoja de cálculo. Sin validación, Claude podría referenciar campos inexistentes, crear valores conflictivos, omitir campos requeridos o aplicar actualizaciones incorrectamente.
Solución: Usa el patrón de flujo de trabajo mostrado arriba (llenado de formularios PDF), pero agrega un archivo intermedio changes.json que se valida antes de aplicar los cambios. El flujo de trabajo se convierte en: analizar → crear archivo de plan → validar plan → ejecutar → verificar.
Por qué funciona este patrón:
Cuándo usarlo: Operaciones por lotes, cambios destructivos, reglas de validación complejas, operaciones de alto riesgo.
Consejo de implementación: Haz que los scripts de validación sean detallados con mensajes de error específicos como "Campo 'signature_date' no encontrado. Campos disponibles: customer_name, order_total, signature_date_signed" para ayudar a Claude a corregir problemas.
Las Skills se ejecutan en el entorno de ejecución de código con limitaciones específicas de la plataforma:
Enumera los paquetes requeridos en tu SKILL.md y verifica que estén disponibles en la documentación de la herramienta de ejecución de código.
Las Skills se ejecutan en un entorno de ejecución de código con acceso al sistema de archivos, comandos bash y capacidades de ejecución de código. Para la explicación conceptual de esta arquitectura, consulta La arquitectura de Skills en la descripción general.
Cómo afecta esto a tu creación:
Cómo accede Claude a las Skills:
reference/guide.md), no barras invertidasform_validation_rules.md, no doc2.mdreference/finance.md, reference/sales.mddocs/file1.md, docs/file2.mdvalidate_form.py en lugar de pedirle a Claude que genere código de validaciónanalyze_form.py para extraer campos" (ejecutar)analyze_form.py para el algoritmo de extracción" (leer como referencia)Ejemplo:
bigquery-skill/
├── SKILL.md (overview, points to reference files)
└── reference/
├── finance.md (revenue metrics)
├── sales.md (pipeline data)
└── product.md (usage analytics)Cuando el usuario pregunta sobre ingresos, Claude lee SKILL.md, ve la referencia a reference/finance.md e invoca bash para leer solo ese archivo. Los archivos sales.md y product.md permanecen en el sistema de archivos, consumiendo cero tokens de contexto hasta que se necesiten. Este modelo basado en el sistema de archivos es lo que permite la divulgación progresiva. Claude puede navegar y cargar selectivamente exactamente lo que cada tarea requiere.
Para obtener detalles completos sobre la arquitectura técnica, consulta Cómo funcionan las Skills en la descripción general de Skills.
Si tu Skill usa herramientas de MCP (Model Context Protocol), usa siempre nombres de herramientas completamente calificados para evitar errores de "herramienta no encontrada".
Formato: ServerName:tool_name
Ejemplo:
Use the BigQuery:bigquery_schema tool to retrieve table schemas.
Use the GitHub:create_issue tool to create issues.Donde:
BigQuery y GitHub son nombres de servidores MCPbigquery_schema y create_issue son los nombres de las herramientas dentro de esos servidoresSin el prefijo del servidor, Claude puede fallar al localizar la herramienta, especialmente cuando hay múltiples servidores MCP disponibles.
No asumas que los paquetes están disponibles:
**Bad example: Assumes installation**:
"Use the pdf library to process the file."
**Good example: Explicit about dependencies**:
"Install required package: `pip install pypdf`
Then use it:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"El frontmatter de SKILL.md requiere los campos name y description con reglas de validación específicas:
name: Máximo 64 caracteres, solo letras minúsculas/números/guiones, sin etiquetas XML, sin palabras reservadasdescription: Máximo 1024 caracteres, no vacío, sin etiquetas XMLConsulta la descripción general de Skills para obtener detalles completos de la estructura.
Mantén el cuerpo de SKILL.md por debajo de 500 líneas para un rendimiento óptimo. Si tu contenido excede esto, divídelo en archivos separados usando los patrones de divulgación progresiva descritos anteriormente. Para obtener detalles arquitectónicos, consulta la descripción general de Skills.
Antes de compartir una Skill, verifica:
Crea tu primera Skill
Crea y gestiona Skills en Claude Code
Sube y usa Skills de forma programática
Was this page helpful?