Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Was this page helpful?
Después de definir tus criterios de éxito, el siguiente paso es diseñar evaluaciones para medir el rendimiento del LLM contra esos criterios. Esta es una parte vital del ciclo de ingeniería de prompts.
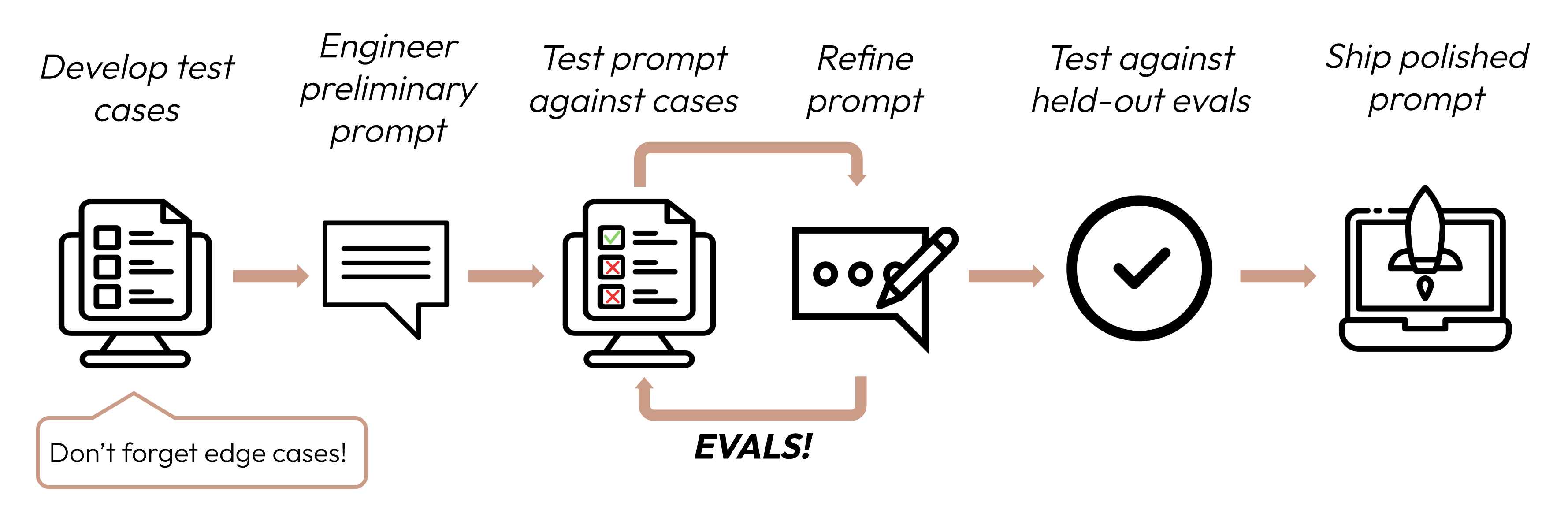
Esta guía se enfoca en cómo desarrollar tus casos de prueba.
Al decidir qué método usar para calificar evals, elige el método más rápido, más confiable y más escalable:
Calificación basada en código: La más rápida y confiable, extremadamente escalable, pero también carece de matices para juicios más complejos que requieren menos rigidez basada en reglas.
output == golden_answerkey_phrase in outputCalificación humana: La más flexible y de alta calidad, pero lenta y cara. Evita si es posible.
Calificación basada en LLM: Rápida y flexible, escalable y adecuada para juicios complejos. Prueba primero para asegurar confiabilidad y luego escala.
Más ejemplos de código de evals calificadas por humanos, código y LLM.