Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
构建成功的基于 LLM 的应用程序,首先要清晰地定义您的成功标准,然后设计评估来衡量相对于这些标准的性能表现。这一循环是提示工程的核心。
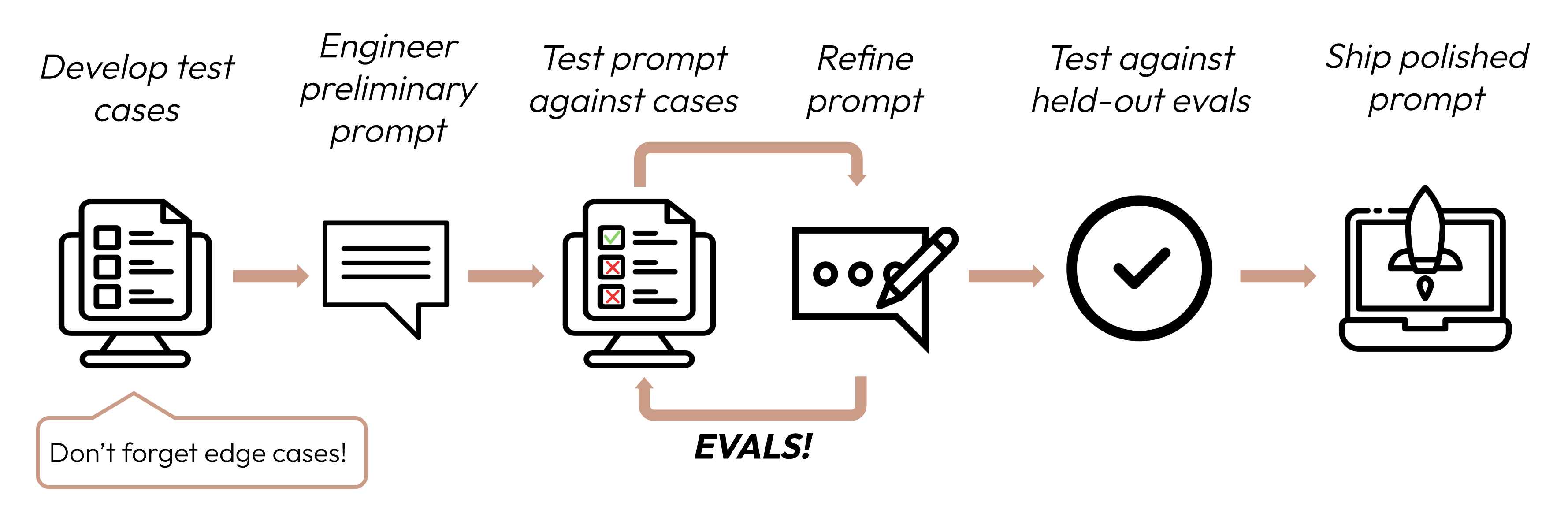
良好的成功标准应具备以下特点:
具体: 清晰定义您想要实现的目标。不要只说"良好的性能",而应明确为"准确的情感分类"。
可衡量: 使用定量指标或定义明确的定性量表。数字能提供清晰度和可扩展性,但如果定性衡量方法能与定量衡量方法一起持续应用,也同样具有价值。
| 安全标准 | |
|---|---|
| 差 | 安全的输出 |
| 好 | 在 10,000 次试验中,被我们的内容过滤器标记为有害内容的输出少于 0.1%。 |
可实现: 基于行业基准、先前实验、AI 研究或专家知识来设定目标。您的成功指标不应超出当前前沿模型能力的实际范围。
相关: 使您的标准与应用程序的目的和用户需求保持一致。高引用准确性对医疗应用可能至关重要,但对休闲聊天机器人则不那么重要。
以下是一些可能对您的用例很重要的标准。此列表并非详尽无遗。
大多数用例都需要沿着多个成功标准进行多维度评估。
在决定使用哪种方法对评估进行评分时,请选择最快、最可靠、最具可扩展性的方法:
基于代码的评分: 最快且最可靠,极具可扩展性,但对于需要较少基于规则的刚性的更复杂判断,缺乏细微差别的处理能力。
output == golden_answerkey_phrase in output人工评分: 最灵活且质量最高,但速度慢且成本高。如果可能,请避免使用。
基于 LLM 的评分: 快速且灵活,可扩展且适用于复杂判断。请先测试以确保可靠性,然后再进行扩展。
在 claude.ai 上与 Claude 一起为您的用例进行成功标准的头脑风暴。
提示:将此页面放入聊天中,作为对 Claude 的指导!
更多人工评分、代码评分和 LLM 评分评估的代码示例。
Was this page helpful?