Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
在定义成功标准之后,下一步是设计评估来衡量 LLM 相对于这些标准的表现。这是提示工程循环中至关重要的一部分。
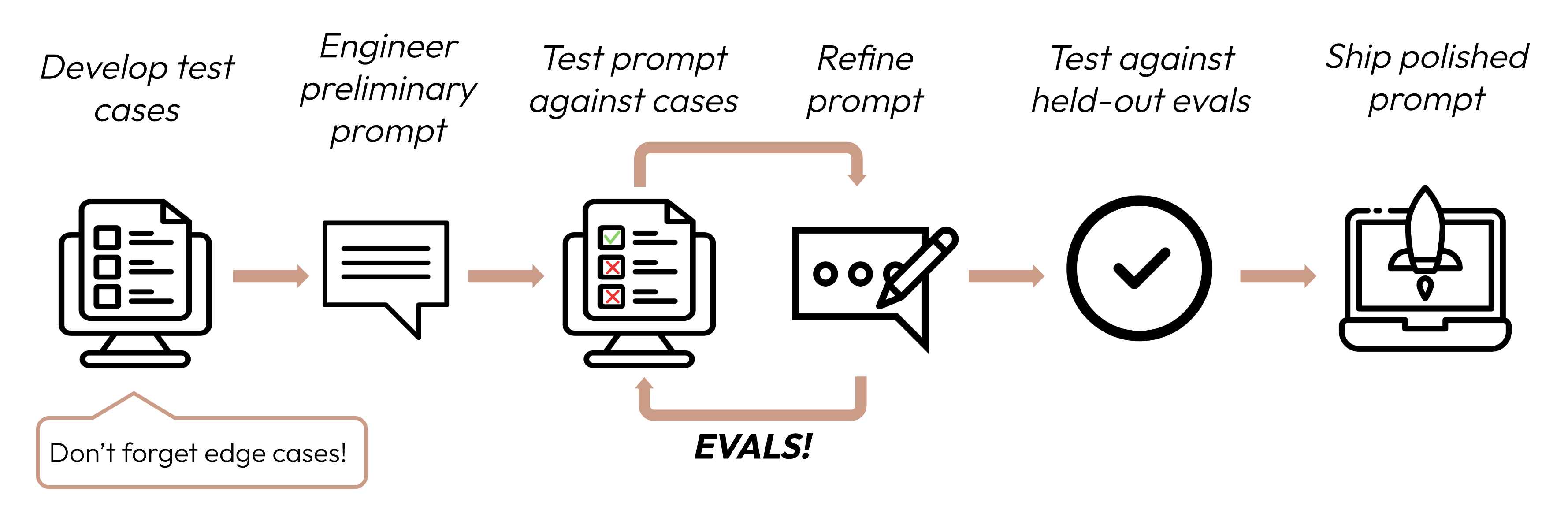
本指南重点介绍如何开发您的测试用例。
在决定使用哪种方法对评估进行评分时,选择最快、最可靠、最可扩展的方法:
基于代码的评分:最快且最可靠,极具可扩展性,但对于需要较少基于规则的严格性的更复杂判断缺乏细微差别。
output == golden_answerkey_phrase in output人工评分:最灵活且质量最高,但速度慢且成本高。尽可能避免使用。
基于 LLM 的评分:快速且灵活,可扩展且适合复杂判断。先测试以确保可靠性,然后再扩展规模。
Was this page helpful?